07.RDD、DataFrame和DataSet对比与转换
07.RDD、DataFrame和DataSet对比与转换一、对比1.1 版本产生对比Spark1.0 => RDDSpark1.3 => DataFrameSpark1.6 => Dataset 如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不 同是的他们的执行效率和执行方式。在后期的 Spark 版本中,DataSet 有可能...

06.【转载】Dataset (DataFrame) 的基础操作(二)
06.【转载】Dataset (DataFrame) 的基础操作(二)三、Column 对象导读Column 表示了 Dataset 中的一个列, 并且可以持有一个表达式, 这个表达式作用于每一条数据, 对每条数据都生成一个值, 之所以有单独这样的一个章节是因为列的操作属于细节, 但是又比较常见, 会在很多算子中配合出现全套代码展示:package com.spark.transformat...

05.【转载】Dataset (DataFrame) 的基础操作(一)
05.【转载】Dataset (DataFrame) 的基础操作(一)导读这一章节主要目的是介绍 Dataset 的基础操作, 当然, DataFrame 就是 Dataset, 所以这些操作大部分也适用于 DataFrame有类型的转换操作无类型的转换操作基础 Action空值如何处理统计操作一、有类型转换操作1.1 flatMap通过 flatMap 可以将一条数据转为一个数组, 后再展...

04.DataFrame常用API
04.DataFrame常用API一、介绍Spark SQL中的DataFrame类似于一张关系型数据表。在关系型数据库中对单表或进行的查询操作,在DataFrame中都可以通过调用其API接口来实现。可以参考,Scala提供的DataFrame API。二、DataFrame操作2.1 Action操作方法说明collect()返回值是一个数组,返回dataframe集合所有的行colle...
03.IDEA创建SparkSQL环境对象
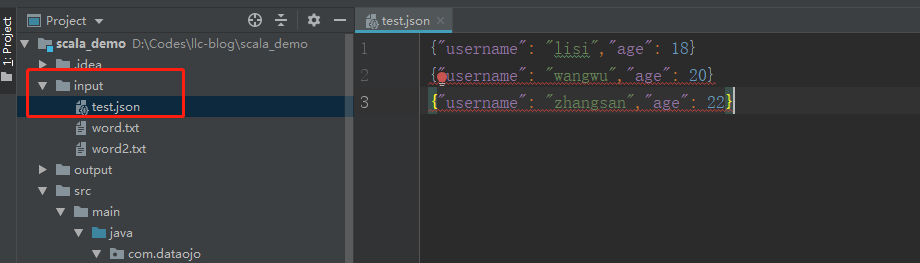
03.IDEA创建SparkSQL环境对象一、引入坐标依赖<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.0.0</version> ...
02.SparkSQL数据模型DataFrame和DataSet介绍
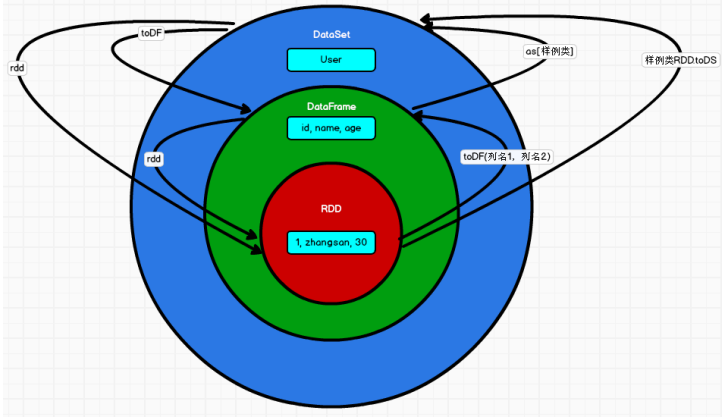
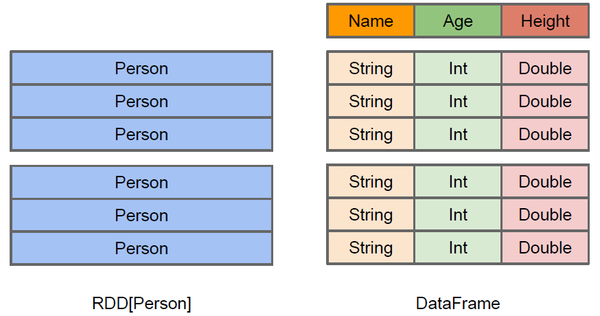
02.SparkSQL数据模型DataFrame和DataSet介绍前言本篇在上篇介绍SparkSQL概念的基础上对DataFrame和DataSet概念进行扩展一、DataFrame介绍1.1 DataFrame概念DataFrame的前身是SchemaRDD,从Spark 1.3.0开始SchemaRDD更名为DataFrame。与SchemaRDD的主要区别是:DataFrame不再直...
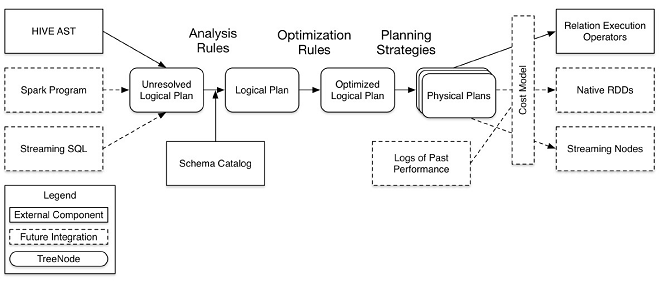
01.SparkSQL概述
01.SparkSQL概述一、简介spark SQL是spark的一个模块,主要用于进行结构化数据的处理。它提供的最核心的编程抽象就是DataFrame。 和基本的Spark RDD API不同的是Spark SQL提供了更多关于数据结构和正在执行的计算的信息。 在内部,Spark SQL使用这些额外的信息来执行额外的优化。可以使用SQL或者Dataset API与Spark SQL进行交互...
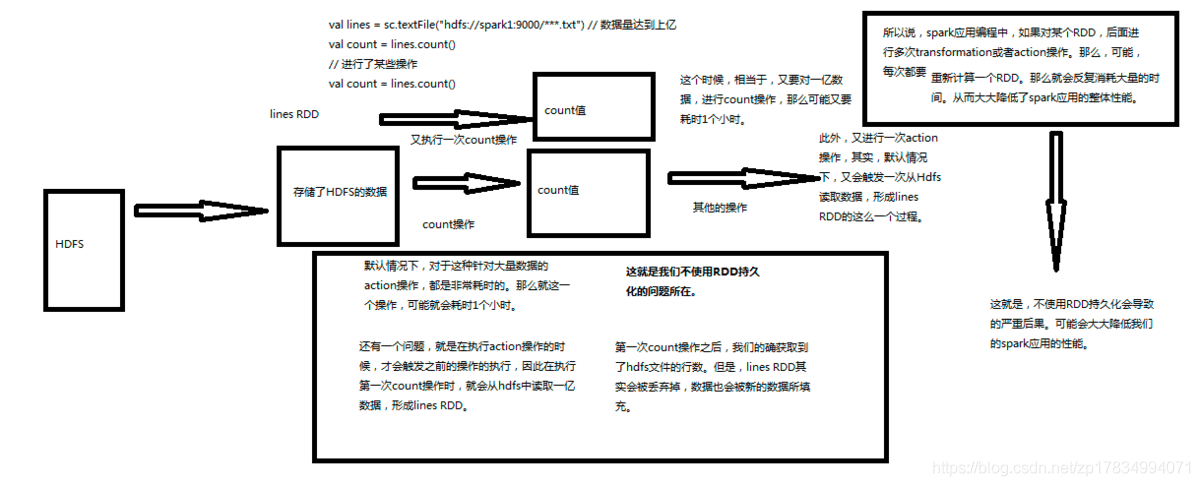
10.【转载】Spark RDD持久化
10.【转载】Spark RDD持久化一、什么是持久化?持久化的意思就是说将RDD的数据缓存到内存中或者持久化到磁盘上,只需要缓存一次,后面对这个RDD做任何计算或者操作,可以直接从缓存中或者磁盘上获得,可以大大加快后续RDD的计算速度。二、为什么要持久化?在之前的文章中讲到Spark中有tranformation和action两类算子,tranformation算子具有lazy特性,只有a...
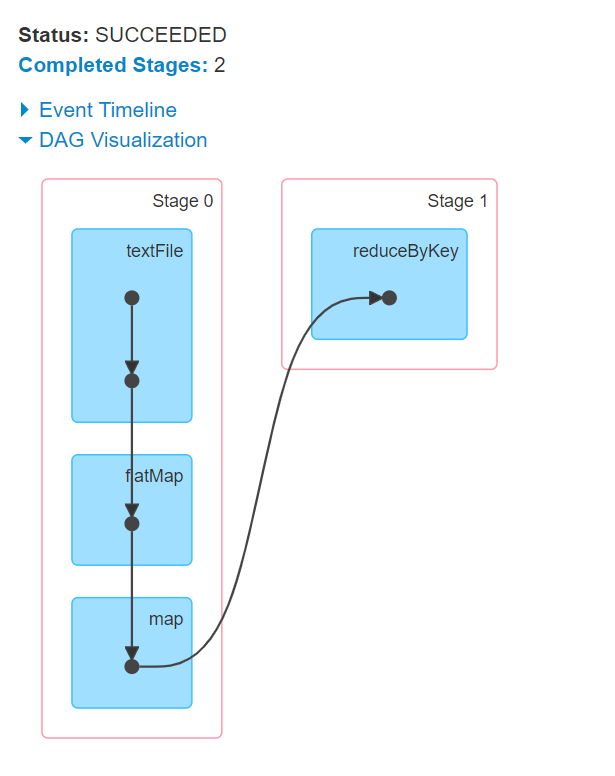
09.【转载】Spark RDD任务划分
09.【转载】Spark RDD任务划分一、DAG有向无环图生成1.1 DAG是什么DAG(Directed Acyclic Graph) 叫做有向无环图(有方向,无闭环,代表着数据的流向),原始的RDD通过一系列的转换就形成了DAG。下图是基于单词统计逻辑得到的DAG有向无环图二、DAG划分stage2.1 stage是什么一个Job会被拆分为多组Task,每组任务被称为一个stagest...