李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
07.RDD、DataFrame和DataSet对比与转换
Leefs
2021-07-16 PM
1663℃
0条
# 07.RDD、DataFrame和DataSet对比与转换 ### 一、对比 #### 1.1 版本产生对比 + Spark1.0 => RDD + Spark1.3 => DataFrame + Spark1.6 => Dataset 如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不 同是的他们的执行效率和执行方式。在后期的 Spark 版本中,DataSet 有可能会逐步取代 RDD 和 DataFrame 成为唯一的 API 接口。 #### 1.2 三者的共性 + RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数 据提供便利; + 三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到 Action 如 foreach 时,三者才会开始遍历运算; + 三者有许多共同的函数,如 filter,排序等; + 在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:import spark.implicits._(在 创建好 SparkSession 对象后尽量直接导入) + 三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会 内存溢出 + 三者都有 partition 的概念 + DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型 #### 1.3 三者的区别 (1)RDD + RDD 一般和 spark mllib 同时使用 + RDD 不支持 sparksql 操作 (2)DataFrame + 与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为 Row,每一列的值没法直 接访问,只有通过解析才能获取各个字段的值 + DataFrame 与 DataSet 一般不与 spark mllib 同时使用 + DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能 注册临时表/视窗,进行 sql 语句操作 + DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表 头,这样每一列的字段名一目了然(后面专门讲解) (3)DataSet + Dataset 和 DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同。 DataFrame 其实就是 DataSet 的一个特例 `type DataFrame = Dataset[Row]` + DataFrame 也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的getAS方法或者共性中的第七条提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息 ### 二、数据比较 ##### 2.1 RDD中的数据  ##### 2.2 DataFrame中的数据  ##### 2.3 Dataset中的数据  或者是这样  DataSet包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。 ### 三、三者的相互转换 RDD、DataFrame、Dataset三者有许多共性,有各自适用的场景常常需要在三者之间转换 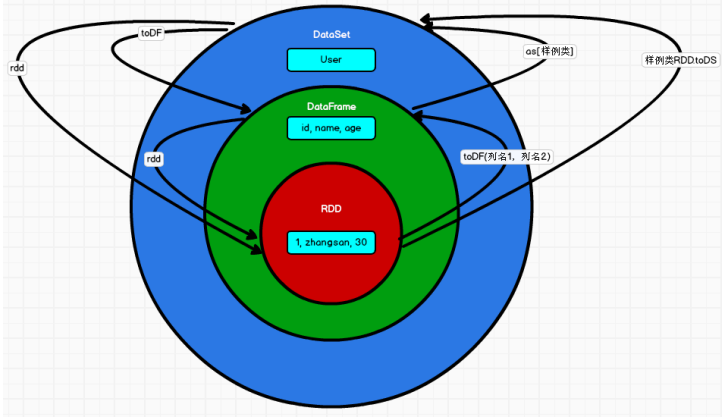 ##### **DataFrame/Dataset转RDD:** ```scala val rdd1=testDF.rdd val rdd2=testDS.rdd ``` ##### **RDD转DataFrame:** ```scala import spark.implicits._ val testDF: DataFrame = rdd.map {line=> (line._1,line._2) }.toDF("col1","col2") ``` 一般用元组把一行的数据写在一起,然后在toDF中指定字段名 ##### **RDD转Dataset:** ```scala import spark.implicits._ case class Person(col1:String,col2:Int)extends Serializable //定义字段名和类型 val testDS: Dataset[Person] = rdd.map {line=> Person(line._1,line._2) }.toDS ``` 可以注意到,定义每一行的类型(case class)时,已经给出了字段名和类型,后面只要往case class里面添加值即可 ##### **Dataset转DataFrame:** 这个也很简单,因为只是把case class封装成Row ```scala import spark.implicits._ val testDF = testDS.toDF ``` ##### **DataFrame转Dataset:** ```scala import spark.implicits._ case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型 val testDS = testDF.as[Coltest] ``` 这种方法就是在给出每一列的类型后,使用as方法,转成Dataset,这在数据类型是DataFrame又需要针对各个字段处理时极为方便 *附参考文章链接:* https://blog.csdn.net/qq_22473611/article/details/103205420 https://blog.csdn.net/weixin_42702831/article/details/82492421
标签:
Spark
,
Spark SQL
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1351.html
上一篇
06.【转载】Dataset (DataFrame) 的基础操作(二)
下一篇
08.UDF和UDAF函数介绍
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
国产数据库改造
MyBatis
SpringCloud
栈
Golang基础
LeetCode刷题
Stream流
Ubuntu
数据结构
Linux
SpringCloudAlibaba
SpringBoot
SQL练习题
Spark
链表
Typora
哈希表
并发编程
CentOS
Spark Core
MyBatisX
递归
Git
查找
Zookeeper
Flink
JVM
pytorch
Kafka
持有对象
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭