李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
08.UDF和UDAF函数介绍
Leefs
2021-07-16 PM
2263℃
0条
# 08.UDF和UDAF函数介绍 ### 前言 UDF、UDAF、UDTF都是用户自定义函数,用户可以通过 `spark.udf` 功能添加自定义函数,实现自定义功能。 **UDF:用户自定义函数(User Defined Function),一行输入一行输出。** **UDAF:用户自定义聚合函数(User Defined Aggregate Function),多行输入一行输出。** **UDTF:用户自定义表函数(User Defined Table Generating Function),一行输入多行输出。** **聚合函数和普通函数的区别**:普通函数是接受一行输入产生一个输出,聚合函数是接受一组(一般是多行)输入然后产生一个输出,即将一组的值想办法聚合一下。 本篇将介绍UDF和UDAF函数。 ### 一、概念 #### UDF UDF(User-Defined-Function),也就是最基本的函数,它提供了SQL中对字段转换的功能,不涉及聚合操作。 适用场景:UDF使用频率极高,对于单条记录进行比较复杂的操作,使用内置函数无法完成或者比较复杂的情况都比较适合使用UDF。 #### UDAF UDAF(User-Defined-Aggregate-Function)函数是用户自定义的聚合函数,为Spark SQL 提供对数据集的聚合功能。 类似于max()、min()、count()等功能,只不过自定义的功能是根据具体的业务功能来确定的。 因为DataFrame是弱类型的,DataSet是强类型,所以自定义的 UDAF也提供了两种实现,一个是弱类型的一个是强类型的(不常用)。 **误区** 我们可能下意识的认为UDAF是需要和group by一起使用的,实际上UDAF可以跟group by一起使用,也可以不跟group by一起使用,这个其实比较好理解,联想到mysql中的max、min等函数,可以: ```sql select max(age) from person group by address; ``` 表示根据address字段分组,然后求每个分组的最大值,这时候的分组有很多个,使用这个函数对每个分组进行处理,也可以: ```sql select max(age) from person; ``` 这种情况可以将整张表看做是一个分组,然后在这个分组(实际上就是一整张表)中求最大值。所以聚合函数实际上是对分组做处理,而不关心分组中记录的具体数量。 ### 二、具体用法 #### 2.1 UDF用法 **具体步骤:** 1. 实现UDF,可以是case class,可以是匿名类 2. 注册到spark,将类绑定到一个name,后续会使用这个name来调用函数 3. 在sql语句中调用注册的name调用UDF **代码示例:** ```scala import org.apache.spark.rdd.RDD import org.apache.spark.sql.SparkSession /** * @author lilinchao * @date 2021/7/15 * @description 1.0 **/ object SparkSQL_UDF { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[*]").appName("udf").getOrCreate() //后面要用到toDF,必须导入这个隐式转换 import spark.implicits._ //引入数据源 val rdd: RDD[(String, String)] = spark.sparkContext.parallelize(Seq(("010","zhagnsan"),("0020","王五"),("00345","赵六"))) //将集合转成dataFrame,并创建临时表 rdd.toDF("id","name").createOrReplaceTempView("person") //注册自定义udf函数 spark.udf.register("fillZero",fillZero _) //自定义匿名函数,统计字符串长度 spark.udf.register("strLen",(str: String) => str.length()) //没有加自定义函数 spark.sql("select id,name from person").show() //加了自定义udf函数 spark.sql("select fillZero(id),name,strLen(name) from person").show() spark.close() } /** * 补全Id */ def fillZero(id:String):String = { "0"*(8-id.length)+id } } ``` **直接对列使用UDF** 在sql语句中使用比较麻烦,还要进行注册,可以定义一个UDF然后将它直接应用到某个列上: ```scala import org.apache.spark.sql.{SparkSession, functions} /** * @author lilinchao * @date 2021/7/15 * @description 1.0 **/ object Spark01_SparkSQL_UDF2 { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[*]").appName("udf").getOrCreate() import spark.implicits._ val ds = Seq((1, "zhangsan"), (2, "lisi")).toDF("id", "name") //自定义匿名函数,小写转大写 val toUpperCase = functions.udf((s: String) => s.toUpperCase) ds.withColumn("name", toUpperCase('name)).show() spark.close() } } ``` #### 2.2 UDAF用法 **数据准备:** user.json文件 ```json {"id": 1001, "name": "王小帅", "sex": "man", "age": 22} {"id": 1002, "name": "岳小林", "sex": "man", "age": 16} {"id": 1003, "name": "邱小峰", "sex": "man", "age": 18} {"id": 1004, "name": "刘小明", "sex": "woman", "age": 17} {"id": 1005, "name": "张小飞", "sex": "woman", "age": 19} {"id": 1006, "name": "李小刀", "sex": "woman", "age": 20} ``` ##### 1. 继承`UserDefinedAggregateFunction` **具体步骤:** 1. 自定义类继承`UserDefinedAggregateFunction`,对每个阶段方法做实现 2. 在spark中注册UDAF,为其绑定一个名称 3. 在sql语句中使用上面绑定的名字调用 **下面写一个计算平均值的UDAF例子** + 首先定义一个类继承UserDefinedAggregateFunction: ```scala import org.apache.spark.sql.Row import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction} import org.apache.spark.sql.types._ import org.apache.spark.sql.expressions.UserDefinedAggregateFunction /** * @author lilinchao * @date 2021/7/15 * @description 1.0 **/ object AverageUserDefinedAggregateFunction extends UserDefinedAggregateFunction{ // 聚合函数的输入数据结构 override def inputSchema: StructType = StructType(StructField("input", LongType) :: Nil) // 缓存区数据结构 override def bufferSchema: StructType = StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil) // 聚合函数返回值数据结构 override def dataType: DataType = DoubleType // 聚合函数是否是幂等的,即相同输入是否总是能得到相同输出 override def deterministic: Boolean = true // 初始化缓冲区 override def initialize(buffer: MutableAggregationBuffer): Unit = { buffer(0) = 0L buffer(1) = 0L } // 给聚合函数传入一条新数据进行处理 override def update(buffer: MutableAggregationBuffer, input: Row): Unit = { if (input.isNullAt(0)) return buffer(0) = buffer.getLong(0) + input.getLong(0) buffer(1) = buffer.getLong(1) + 1 } // 合并聚合函数缓冲区 override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = { buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0) buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1) } // 计算最终结果 override def evaluate(buffer: Row): Any = buffer.getLong(0).toDouble / buffer.getLong(1) } ``` + 在主函数中进行注册并完成调用 ```json import org.apache.spark.sql.SparkSession /** * @author lilinchao * @date 2021/7/15 * @description 1.0 **/ object SparkSql_UDAFDemo { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[*]").appName("SparkUDAF").getOrCreate() spark.read.json("input/user.json").createOrReplaceTempView("user") spark.udf.register("u_avg", AverageUserDefinedAggregateFunction) // 将整张表看做是一个分组对求所有人的平均年龄 spark.sql("select count(1) as count, u_avg(age) as avg_age from user").show() // 按照性别分组求平均年龄 spark.sql("select sex, count(1) as count, u_avg(age) as avg_age from user group by sex").show() } } ``` + 运行结果 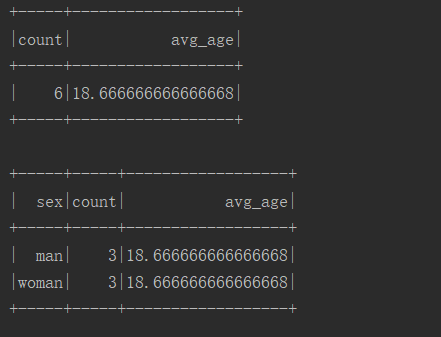 ##### 2. 继承Aggregator + 继承Aggregator这个类,优点是可以带类型 ```scala import org.apache.spark.sql.expressions.Aggregator import org.apache.spark.sql.{Encoder, Encoders} /** * @author lilinchao * @date 2021/7/15 * @description 计算平均值 **/ object AverageAggregator extends Aggregator[User, Average, Double]{ // 初始化buffer override def zero: Average = Average(0L, 0L) // 处理一条新的记录 override def reduce(b: Average, a: User): Average = { b.sum += a.age b.count += 1L b } // 合并聚合buffer override def merge(b1: Average, b2: Average): Average = { b1.sum += b2.sum b1.count += b2.count b1 } // 减少中间数据传输 override def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count override def bufferEncoder: Encoder[Average] = Encoders.product // 最终输出结果的类型 override def outputEncoder: Encoder[Double] = Encoders.scalaDouble } /** * 计算平均值过程中使用的Buffer * * @param sum * @param count */ case class Average(var sum: Long, var count: Long) { } case class User(id: Long, name: String, sex: String, age: Long) { } ``` + 主函数调用 ```scala import org.apache.spark.sql.SparkSession /** * @author lilinchao * @date 2021/7/15 * @description 1.0 **/ object SparkSql_UDAFDemo02 { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[*]").appName("SparkUDAF").getOrCreate() import spark.implicits._ val user = spark.read.json("input/user.json").as[User] user.select(AverageAggregator.toColumn.name("avg")).show() } } ``` + 运行结果  *附:参考文章链接* https://blog.csdn.net/newchitu/article/details/100693142
标签:
Spark
,
Spark SQL
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1354.html
上一篇
07.RDD、DataFrame和DataSet对比与转换
下一篇
09.SparkSQL数据的加载和保存
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
SpringCloud
nginx
JavaScript
Jenkins
Spark SQL
Spark RDD
Spark Core
查找
算法
Redis
Java
Ubuntu
链表
设计模式
正则表达式
LeetCode刷题
Netty
随笔
SpringCloudAlibaba
Git
稀疏数组
Beego
MyBatisX
Azkaban
容器深入研究
VUE
Golang
JVM
二叉树
Nacos
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭