10.【转载】Spark RDD持久化
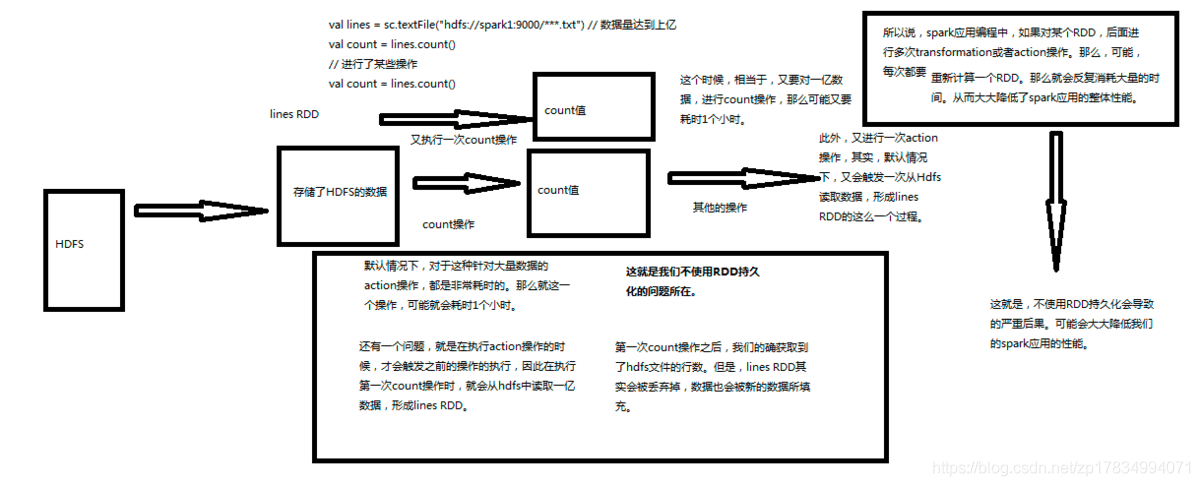
10.【转载】Spark RDD持久化一、什么是持久化?持久化的意思就是说将RDD的数据缓存到内存中或者持久化到磁盘上,只需要缓存一次,后面对这个RDD做任何计算或者操作,可以直接从缓存中或者磁盘上获得,可以大大加快后续RDD的计算速度。二、为什么要持久化?在之前的文章中讲到Spark中有tranformation和action两类算子,tranformation算子具有lazy特性,只有a...
09.【转载】Spark RDD任务划分
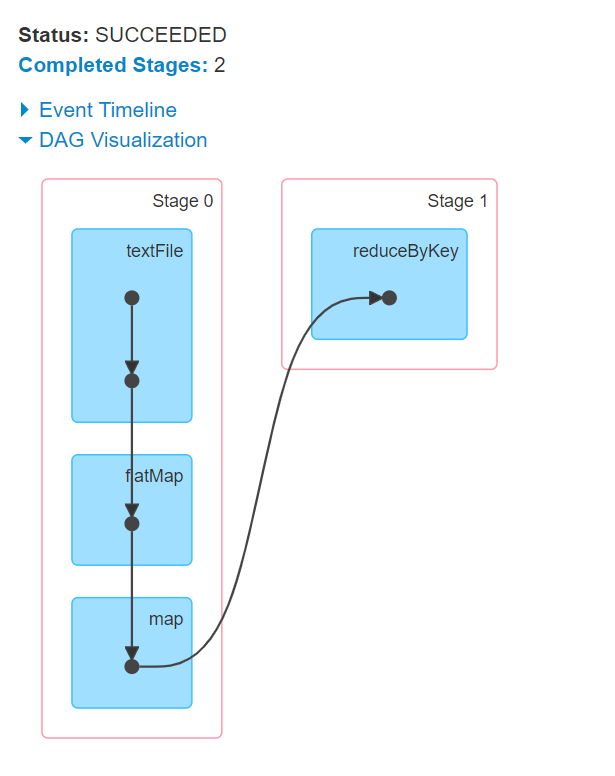
09.【转载】Spark RDD任务划分一、DAG有向无环图生成1.1 DAG是什么DAG(Directed Acyclic Graph) 叫做有向无环图(有方向,无闭环,代表着数据的流向),原始的RDD通过一系列的转换就形成了DAG。下图是基于单词统计逻辑得到的DAG有向无环图二、DAG划分stage2.1 stage是什么一个Job会被拆分为多组Task,每组任务被称为一个stagest...
08.Spark RDD依赖关系
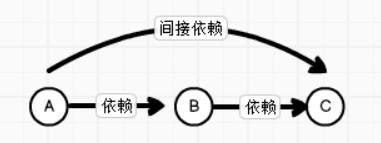
08.Spark RDD依赖关系一、RDD血缘关系1.1 概述RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。由于RDD中是不记录数据的,为了实现分布式计算中的容错 , RDD...

07.Spark RDD序列化
07.Spark RDD序列化一、闭包检查 从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor 端执行。 那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor 端执行,就会发生错误,所以需要在执行...
06.【转载】Spark RDD行动算子
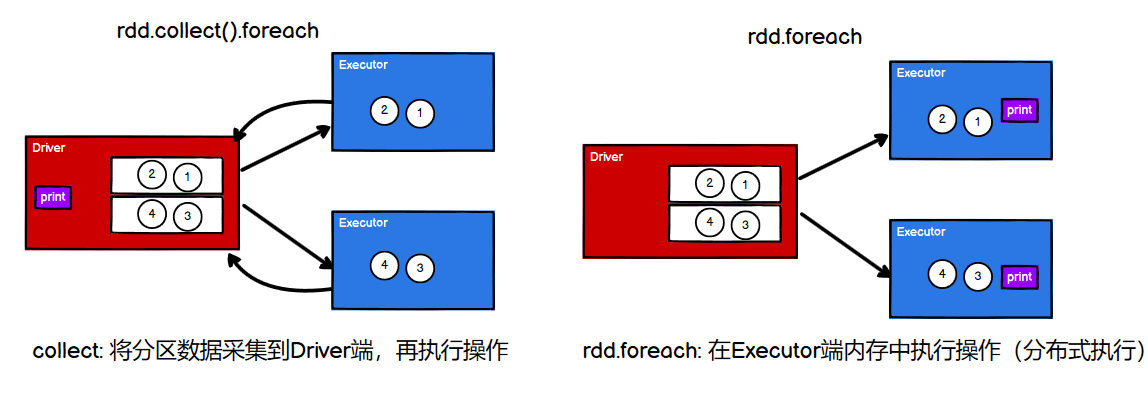
[TOC]行动算子如何理解行动算子?val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) // 转换算子:将旧的RDD封装为新的RDD,形成transform chain,不会执行任何Job val mapRdd: RDD[Int] = rdd.map(_ * 2) // 行动算子:其实就是触发作业(Job)执行的方法,返回值不再是RDD ma...

05.【转载】Spark RDD转换算子
[TOC]前言转换算子RDD 根据数据处理方式的不同,将算子整体上分为 Value 类型、双 Value 类型 和 Key-Value类型。Value类型mapdef map(f: T => U): RDD[U]说明:将RDD中类型为T的元素,一对一地映射为类型为U的元素,这里的转换可以是类型的转换,也可以是值的转换val rdd: RDD[Int] = sc.makeRDD(List...
04.Spark RDD创建简介
04.Spark RDD创建简介一、创建RDD1.1 RDD创建方式大概分为四种(1)从集合(内存中创建)RDD从集合中创建 RDD,Spark 主要提供了两个方法:parallelize 和 makeRDDparallelizedef parallelize[T](seq: Seq[T], numSlices: Int = defaultParallelism)(implicit arg0...
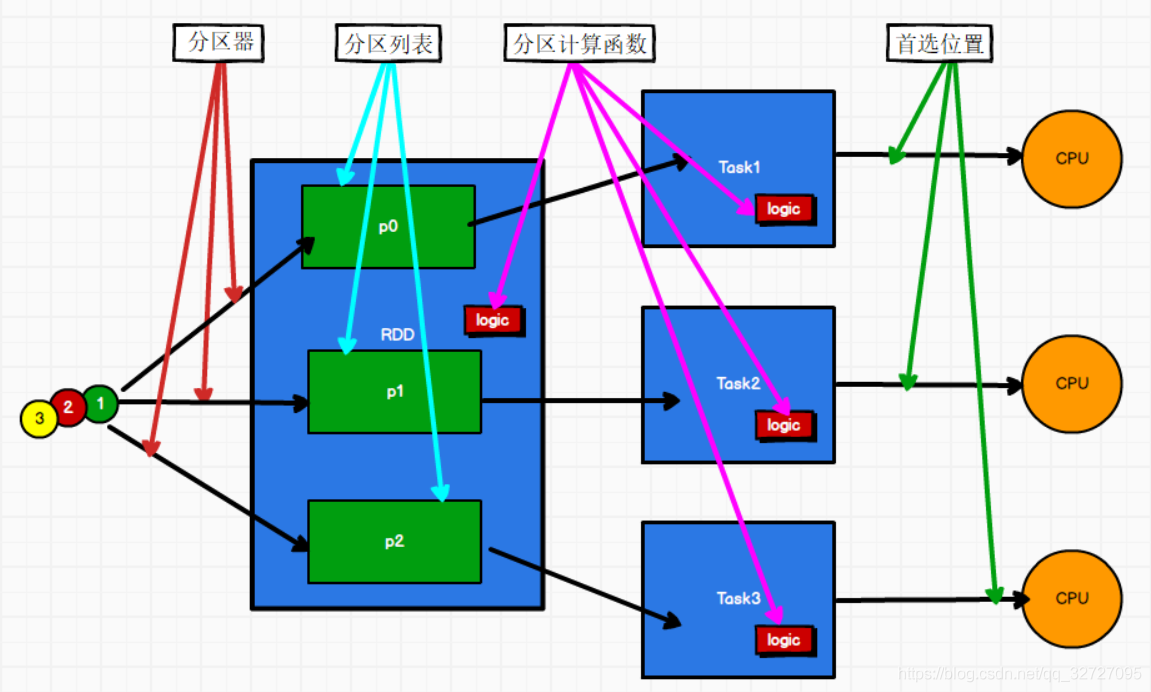
03.Spark RDD简介
03.Spark RDD简介一、RDD定义RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。弹性存储的弹性:内存与磁盘的自动切换;容错的弹性:数据丢失可以自动恢复;计算的弹性:计算出错重试机制;分片的弹性:可根据需要重新分片分布式:数据...

02. Spark Shuffle过程介绍
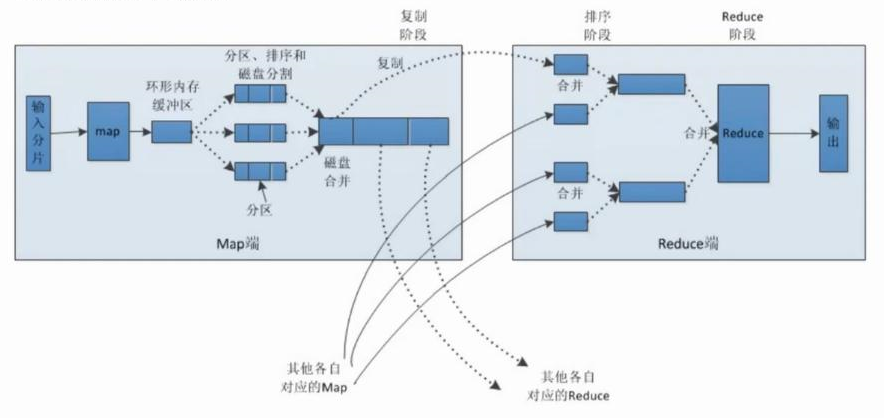
02. Spark Shuffle过程介绍一、Shuffle概念1.1 Shuffle简介有些运算需要将各节点上的同一类数据汇集到某一节点进行计算,把这些分布在不同节点的数据按照一定的规则汇集到一起的过程称为 Shuffle。1.2 MapReduce中的Shuffle在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对...
01.MapReduce介绍
01.MapReduce介绍一、简介 在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce。 MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结...