李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
01.MapReduce介绍
Leefs
2021-06-29 AM
1723℃
0条
# 01.MapReduce介绍 ### 一、简介 在分布式计算中,**MapReduce**框架负责处理了并行编程中`分布式存储`、`工作调度`、`负载均衡`、`容错均衡`、`容错处理`以及`网络通信`等复杂问题,把处理过程高度抽象为两个函数:`map`和`reduce`。 **MapReduce**采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。 **总结**:MapReduce就是"任务的分解与结果的汇总" ### 二、Map和Reduce **2.1 概念介绍** MapReduce 方法使用了拆分的思想,合并了map(映射)和reduce(归约)两种经典函数。 + **map**:接受一个键值对`(key-value pair)`,产生一组中间键值对。`MapReduce`框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。 + **reduce**:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。 **2.2 MapReduce编程模型**  说明: 1. user program链接了map reduce库,实现了最基本的map函数和reduce函数。 2. MapReduce库先把user program的输入文件划分为M份(划分到多少份是用户定义的),如上图所示,我们将用户输入文件划分为5份,分别是split0~split4. 3. user program用fork得到一个自己的副本进程,记为master,然后再fork几个进程记为worker,这个master是负责调度作业的,为空闲的worker分配任务。(Map作业,即是处理一个输入数据的分片;Reduce作业处理一个分区的中间键值对),woker的数量也是由用户指定的,用户想要fork几个就fork几个。 4. map得到的中间结果会被定期写入本地磁盘,且被分为R个区,R也是用户定义的,将来的每个区会对应一个reduce作业。这些中间结果的位置会被告知给master,master将这些信息告诉reduce worker。 5. reduce worker从master那里得到了自己负责的中间结果的位置,reduce worker得到所有的中间键值对,现对他们进行排序,使得相同键的键值对聚集在一起。 6. 然后reduce worker将得到键值及其相关联的值集合一起给reduce函数,reduce函数会将这些输出到这个分区的输出文件(HDFS)中。 7. 所有的map和reduce作业完成了,master唤醒user program,map reduce函数调用返回user program的代码。 **2.3 MapReduce中的shuffle** 整个MapReduce过程大致分为:`Map-->Shuffle(排序)-->Combine(组合)-->Reduce` 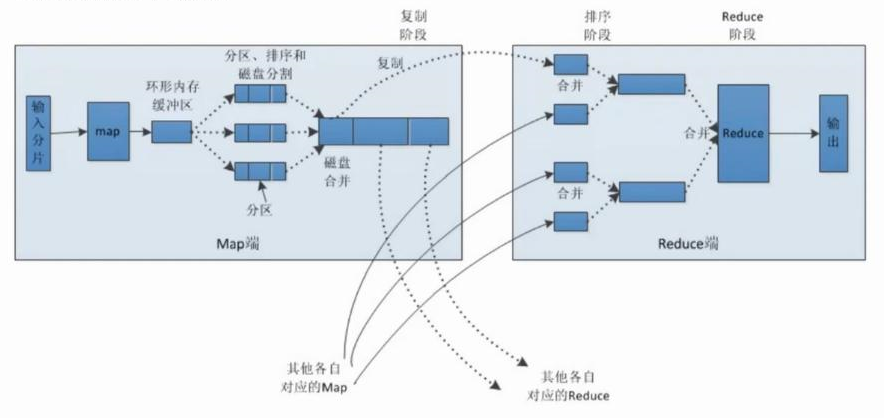 #### **流程分析** **Map端:** (1)**每个输入分片会让一个map任务来处理**。 > 默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中,当该缓冲区快要溢出时(默认为缓冲区大小的80%),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。 (2)**在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。** > 这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。 (3)**当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。** > 合并的过程中会不断地进行排序和combia操作,目的有两个: > > 1. 尽量减少每次写入磁盘的数据量; > 2. 尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。 (4)**将分区中的数据拷贝给相对应的reduce任务。** > 有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。 **Reduce端:** (1)Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中,如果数据量超过了该缓冲区大小的一定比例,则对数据合并后溢写到磁盘中。 (2)随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作。 (3)合并的过程中会产生许多的中间文件,但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。 *附:* https://www.cnblogs.com/LUO77/p/5789346.html https://blog.csdn.net/zhinengxuexi/article/details/83351705
标签:
Spark
,
Spark Core
,
Spark RDD
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1264.html
上一篇
03.Livy中REST API使用
下一篇
02. Spark Shuffle过程介绍
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
数据结构
Java阻塞队列
Elasticsearch
查找
Http
正则表达式
数学
pytorch
国产数据库改造
SpringCloudAlibaba
二叉树
Azkaban
NIO
Spark SQL
Beego
Kibana
Eclipse
字符串
JavaScript
SpringBoot
高并发
机器学习
FileBeat
Spark RDD
BurpSuite
容器深入研究
栈
工具
设计模式
Ubuntu
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭