
golang算法篇之0-1背包算法介绍
[TOC]前言本篇是基于《代码随想录》加上自己做题时的一些思考整理出来的。希望对大家理解0-1背包问题有所帮助。一、0-1背包问题引入问题描述: 给定一组物品,每个物品都有自己的重量和价值,以及一个固定的容量的背包。目标是找到一个最佳的组合,使得放入背包的物品的总重量不超过背包容量,且总价值最大。基本思想: 将问题划分为若干个子问题,通过解决子问题得到原问题的最优解。对于每个物品,可以选择放入背包或不放入背包,从而形成递归结构。有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价...
golang算法篇之kmp算法介绍
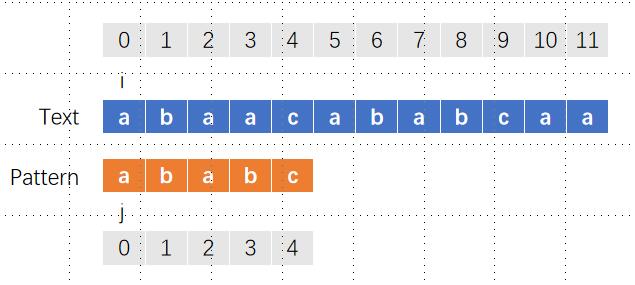
[TOC]一、题目描述LeetCode 28. 找出字符串中第一个匹配项的下标给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。示例 1:输入:haystack = "sadbutsad", needle = "sad" 输出:0 解释:"sad" 在下标 0 和 6 处匹配。 第一个匹配项的下标是 0 ,所以返回 0 。示例 2:输入:haystack ...

golang之gorm操作示例并兼容达梦数据库
[TOC]前言关于gorm的概念和安装本篇将不做过多赘述,本篇只针对Gorm的简单使用进行讲述。同时本篇使用的是beego框架,兼容MySQL和达梦数据库。达梦数据库gorm驱动可以使用:https://github.com/Leefs/gorm-driver-dm在该驱动中小编解决了达梦双单引号转义问题同时在编码过程中会存在以下三个问题:添加语句中无法返回自增ID驱动中dmSchema.Clob类型兼容性问题查询语句时间格式兼容性问题一、连接配置1.1 app.conf写入mysql连接信息# 连接数据库类型 mysql/dm db_type = mysql # 连接数据库账号 db_...
golang基础使用示例
[TOC]一、map、slice简单使用示例(1)使用 slice 存储 map 列表import "fmt" // 使用 slice 存储 map 列表 func main() { // 创建一个空的 map 切片 // data是一个切片,其元素类型是map[string]int // data可以包含多个map,每个map的键是字符串类型,值是整数类型 var data []map[string]int // 向切片中添加 map 元素 data = append(data, map[string]int{&q...
golang之context介绍
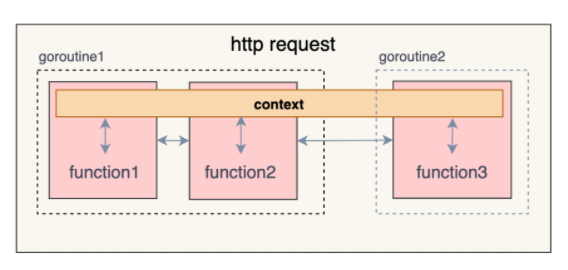
[TOC]一、Context作用context.Context是Go中定义的一个接口类型,从1.7版本中开始引入。其主要作用是在一次请求经过的所有协程或函数间传递取消信号及共享数据,以达到父协程对子协程的管理和控制的目的。需要注意的是context.Context的作用范围是一次请求的生命周期,即随着请求的产生而产生,随着本次请求的结束而结束。二、基本数据结构在context包中,context.Context的定义实际上是一个接口类型,该接口定义了获取上下文的Deadline的函数,根据key获取value值的函数、还有获取done通道的函数。type Context interfac...
go并发之channel底层实现原理
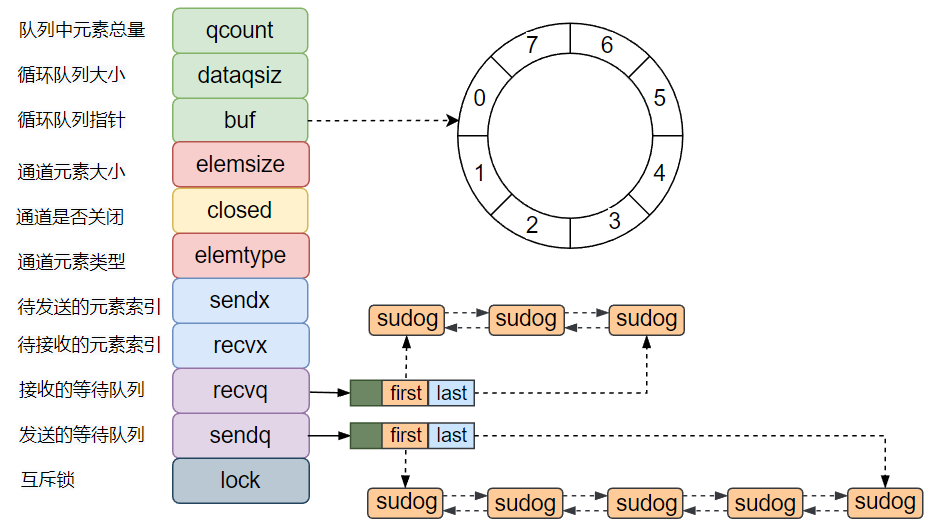
[TOC]前言在开始本章节之前还是要反复唠叨一句话:Go channel设计模式是:不要通过共享内存的方式进行通信,而是应该通过通信的方式共享内存。如果不理解的可以看之前的文章,本章节不再过多赘述。一、核心数据结构1.1 hchanGo语言channel是first-class的,意味着它可以被存储到变量中,可以作为参数传递给函数,也可以作为函数的返回值返回。作为Go语言的核心特征之一,虽然channel看上去很高端,但是其实channel仅仅就是一个数据结构而已,结构体定义如下:type hchan struct { qcount uint ...
go并发之channel
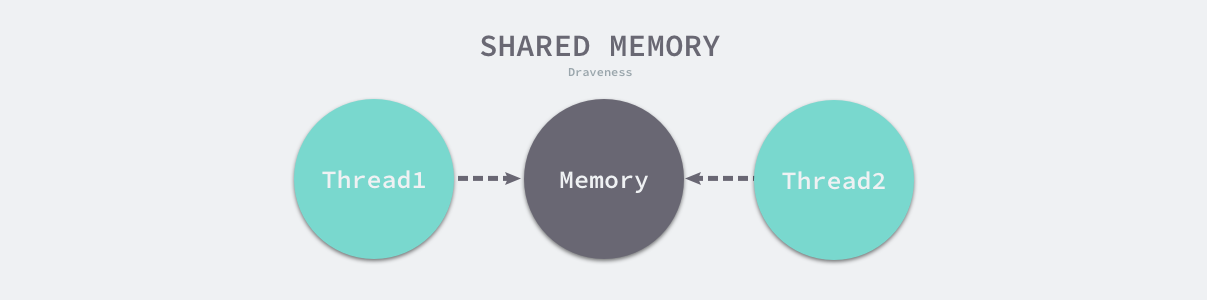
[TOC]一、channel的发送与接收特性Go 语言中最常见的、也是经常被人提及的设计模式就是:不要通过共享内存的方式进行通信,而是应该通过通信的方式共享内存。在很多主流的编程语言中,多个线程传递数据的方式一般都是共享内存,为了解决线程竞争,我们需要限制同一时间能够读写这些变量的线程数量,然而这与 Go 语言鼓励的设计并不相同。下面是多线程之间使用共享内存实现传递数据图示。虽然我们在 Go 语言中也能使用共享内存加互斥锁进行通信,但是 Go 语言提供了一种不同的并发模型,即通信顺序进程(Communicating sequential processes,CSP)。Goroutine ...
HBase过滤器介绍
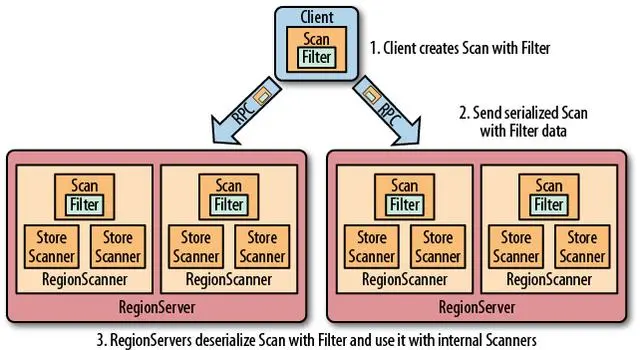
[TOC]前言本次使用的是 HBase 2.5.5 版本,同时本篇是基于上一篇: Hbase之JavaAPI详细介绍的基础上整理的,如果需要运行演示,请先阅读上一篇内容。一、HBase过滤器简介HBase 提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predicate push down)。这样可以保证过滤掉的数据不会被传送到客户端,从而减轻网络传输和客户端处理的压力。二、过滤器基础2.1 Filter接口和FilterBase抽象类Filter 接口中定义了过滤器的基本方法,Fil...
Hbase之JavaAPI详细介绍
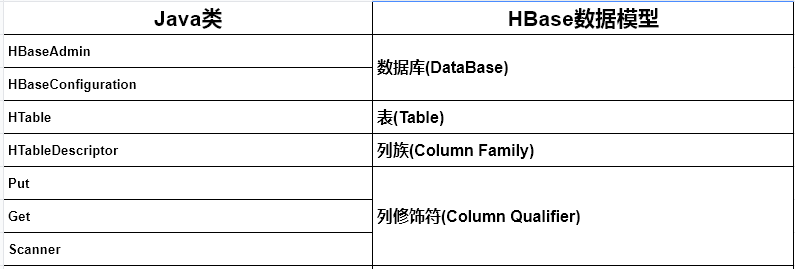
[TOC]前言HBase本身是基于Java开发的,因此,也提供了一整套的Java API开发接口,整个接口方法非常完善,包括命名空间管理、表级管理、列族级管理、数据(增删改查、导入、导出)、集群调度、状态监测、集群优化等。一、常用java API介绍主要的Hbase API类和数据模型之间的的对应的关系1.1 Adminorg.apache.hadoop.hbase.client.Admin说明:Admin为Java接口类型,不可以直接用该接口实例化一个对象,而是必须调用Connection.getAdmin()方法,返回一个Admin的子对象,然后用这个Admin接口来操作返回的子对象...
IDEA编译运行Spark源码
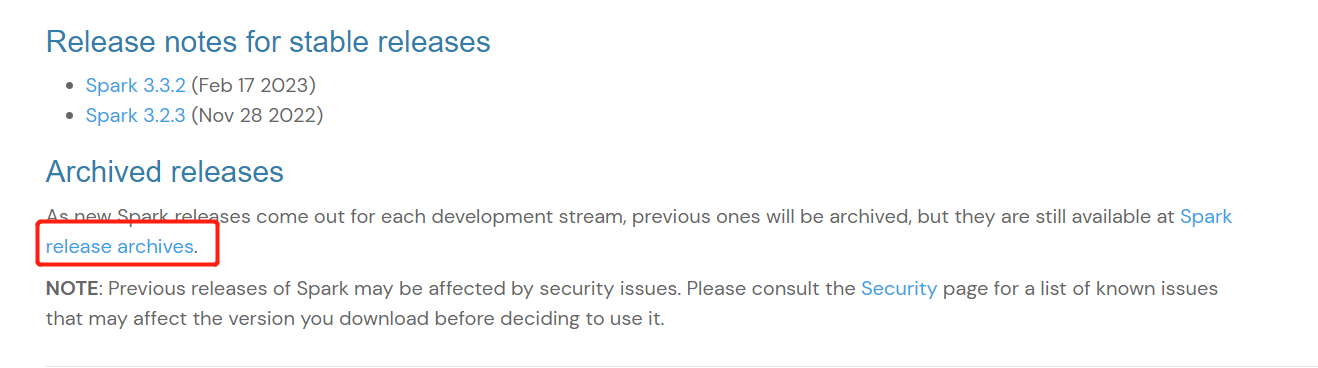
前言环境准备IDEA 2022.3Scala 2.12.15maven 3.6.3JDK 1.8一、下载Spark源码1.1 官网地址Spark官网地址:https://spark.apache.org/downloads.html本次下载的源码版本为:Spark 3.2.31.2 下载之前版本Spark1.3 选择Spark 3.2.3版本下载地址:https://archive.apache.org/dist/spark/1.4 下载源码文件选择下载的源码文件spark-3.2.3.tgz1.5 将源码文件解压到对应目录二、IDEA插件安装编译Spark源码需要安装Scala和ant...