李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
Hbase之JavaAPI详细介绍
Leefs
2023-09-06 PM
2498℃
0条
[TOC] ### 前言 HBase本身是基于Java开发的,因此,也提供了一整套的Java API开发接口,整个接口方法非常完善,包括命名空间管理、表级管理、列族级管理、数据(增删改查、导入、导出)、集群调度、状态监测、集群优化等。 ### 一、常用java API介绍 **主要的Hbase API类和数据模型之间的的对应的关系** 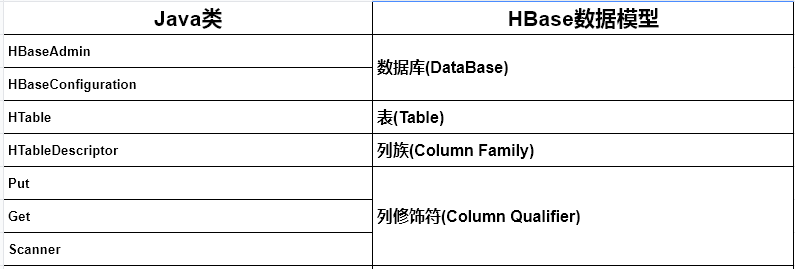 #### 1.1 Admin + `org.apache.hadoop.hbase.client.Admin` > 说明: > > `Admin`为Java接口类型,不可以直接用该接口实例化一个对象,而是必须调用`Connection.getAdmin()`方法,返回一个`Admin`的子对象,然后用这个`Admin`接口来操作返回的子对象方法。 > > 该接口用于管理 HBase 数据库的表信息,包括创建或删除表、列出表项、使表有效或无效、添加或删除表的列族成员、检查 HBase 的运行状态等。 + **主要方法** | 方法 | 说明 | | :----------------------------------------------------------- | :----------------------- | | `void addColumn(TableName tableName,HColumnDescriptor columnFamily)` | 向一个已存在的表添加列 | | `void closeRegion(byte[] regionName,String serverName)` | 关闭Region | | `void createTable(HTableDescriptor desc)` | 创建表 | | `void deleteTable(TableName tableName)` | 删除表 | | `void disableTable(TableName tableName)` | 使表无效 | | `void enableTable(TableName tableName)` | 使表有效 | | `boolean tableExists(TableName tableName)` | 检查表是否存在 | | `HTableDescriptor listTables()` | 列出所有的表项 | | `void abort(String why, Throwable e)` | 终止服务器或客户端 | | `boolean balancer()` | 调用balancer进行负载均衡 | + **用法示例** ```java HBaseAdmin admin = new HBaseAdmin(config); admin.disableTable("tablename") ``` #### 1.2 HBaseConfiguration + `org.apache.hadoop.hbase.HBaseConfiguration` > 说明: > > 该类用于管理 HBase 的配置信息 + **主要方法** | 方法 | 说明 | | :----------------------------------------------------------- | :------------------------------------------ | | `static Configuration create()` | 使用默认的HBase配置文件创建Configuration | | `static Configuration addHBaseResource(Configuration conf)` | 向当前Configuration添加参数conf中的配置信息 | | `static void merge(Configuration destConf,Configuration srcConf)` | 合并两个Configuration | #### 1.3 Table + `org.apache.hadoop.hbase.client.Table` > 说明: > > Table是Java接口类型,不可以用Table接口直接实例化一个对象,而是必须调用`Connection.getTable()`方法返回Table的一个子对象,然后再调用返回的子对象的成员方法。 > > 这个接口用于与HBase进行通信。如果多个线程对一个Table接口子对象进行put或者delete操作的话,则写缓冲器可能会崩溃。因此,在多线程环境下,建议使用`HTablePool`。 + **主要方法** | 方法 | 说明 | | :----------------------------------------------------------- | :-------------------------------------- | | `void close()` | 释放所有资源,根据缓冲区中变化更新Table | | `void delete(Delete delete)` | 删除指定的单元格或行 | | `boolean exists(Get get)` | 检查Get对象指定的列是否存在 | | `Result get(Get get)` | 从指定的行的某些单元格中取出相应的值 | | `void put(Put put)` | 向表中添加值 | | `ResultScanner getScanner(byte[] family) ResultScanner getScanner(byte[] family,byte[] qualifier) ResultScanner getScanner(Scan scan)` | 获得ResultScanner实例 | | `HTableDescriptor getTableDescriptor()` | 获得当前表的HTableDescriptor实例 | | `TableName getName()` | 获得当前表的名字实例 | + **用法示例** ```java HTable table = new HTable(conf,Bytes.toBytes(tableName)); ResultScanner scanner = table.getScanner(family); ``` #### 1.4 HTableDescriptor + `org.apache.hadoop.hbase.HTableDescriptor` > 说明: > > `HTableDescriptor` 包含了 HBase 中表格的详细信息,例如表中的列族、该表的类型(`-ROOT-`,`.META.`)、该表是否只读、`MemStore`的最大空间、`Region`什么时候应该分裂等。 + **主要方法** | 方法 | 说明 | | :----------------------------------------------------- | :----------------------- | | `HTableDescriptor addFamily(HColumnDescriptor family)` | 添加列族 | | `Collection getFamilies()` | 返回表中所有的列族的名字 | | `TableName getTableName()` | 返回表的名字实例 | | `byte[] getValue(byte[] key)` | 获得某个属性的值 | | `HColumnDescriptor removeFamily(byte[] column)` | 删除某个列族 | | `HColumnDescriptor setValue(byte[] key, byte[] value)` | 设置属性的值 | + **用法示例** ```java // 通过一个 HColumnDescriptor 实例,为 HTableDescriptor 添加了一个列族: family HTableDescriptor htd = new HTableDescriptor(table); htd.addFamily(new HColumnDescriptor("family")) ``` #### 1.5 HColumnDescriptor + `org.apache.hadoop.hbase.HColumnDescriptor` > 说明: > > `HColumnDescriptor`包含了列族的详细信息,例如列族的版本号、压缩设置等。 > > `HColumnDescriptor` 通常在添加列族或者创建表的时候使用。列族一旦建立就不能被修改,只能通过删除列族,然后再创建新的列族来间接的修改。一旦列族被删除了,该列族包含的数据也随之被删除。 + **主要方法** | 方法 | 说明 | | :----------------------------------------------------- | :----------------- | | `byte[] getName()` | 获取列族的名字 | | `byte[] getValue(byte[] key)` | 获得某列单元格的值 | | `HColumnDescriptor setValue(byte[] key, byte[] value)` | 设置某列单元格的值 | + **用法示例** ```java // 添加一个 content 的列族 HTableDescriptor htd = new HTableDescriptor(tableName); HColumnDescriptor col = new HColumnDescriptor("content:"); htd.addFamily(col); ``` #### 1.6 Put + `org.apache.hadoop.hbase.client.Put` > 说明: > > 用来对单元格执行添加数据操作。 + **主要方法** | 方法 | 说明 | | :----------------------------------------------------------- | :---------------------------------------------- | | `Put add(byte[] family, byte[] qualifier, byte[] value)` | 将指定的列族、列限定符、对应的值添加到Put实例中 | | `List get(byte[] family, byte[] qualifier)` | 获取列族和列限定符指定的列中的所有单元格 | | `boolean has(byte[] family, byte[] qualifier)` | 检查列族和列限定符指定的列是否存在 | | `boolean has(byte[] family, byte[] qualifier, byte[] value)` | 检查列族和列限定符指定的列中是否存在指定的value | #### 1.7 Get + `org.apache.hadoop.hbase.client.Get` > 说明: > > 用来获取单行的信息。 + **主要方法** | 方法 | 说明 | | :----------------------------------------------- | :------------------------------- | | `Get addColumn(byte[] family, byte[] qualifier)` | 根据列族和列限定符获得对应的列 | | `Get setFilter(Filter filter)` | 为获得具体的列,设置相应的过滤器 | #### 1.8 Result + `org.apache.hadoop.hbase.client.Result` > 说明: > > 用于存放Get或Scan操作后的查询结果,并以键值对的格式存储在map结构中。该类不是线程安全的。 + **主要方法** | 方法 | 说明 | | :-------------------------------------------------------- | :------------------------------------- | | `boolean containsColumn(byte[] family, byte[] qualifier)` | 检查指定的列是否存在 | | `NavigableMap<Cell, Cell> getFamilyMap(byte[] family)` | 获取对应列族所包含的修饰符与值的键值对 | | `byte[] getValue(byte[] family, byte[] qualifier)` | 获取对应列的最新值 | #### 1.9 ResultScanner + `org.apache.hadoop.hbase.client.ResultScanner` > 说明: > > 客户端获取值的接口。 + **主要方法** | 方法 | 说明 | | :------------ | :-------------------- | | void close() | 关闭scanner并释放资源 | | Result next() | 获得下一个Result实例 | #### 1.10 Scan + `org.apache.hadoop.hbase.client.Scan` > 说明: > > 可以利用Scan来限定需要查找的数据,例如限定版本跑不快、起始行号、终止行号、列族、列限定符、返回值的数量的上限等。 + **主要方法** | 方法 | 说明 | | :----------------------------------------------------------- | :----------------------------------------------------------- | | `Scan addFamily(byte[] family)` | 限定需要查找的列族 | | `Scan addColumn(byte[] family, byte[] qualifier)` | 限定列族和列限定符指定的列 | | `Scan setMaxVersions() Scan setMaxVersions(int maxVersions)` | 限定最大的版本个数。如果不带任何参数调用此方法,表示了所有的版本。如果不调用此方法,只会取最新的版本 | | `Scan setTimeRange(long minStamp, long maxStamp)` | 限定最大的时间戳和最小的时间戳,只有在此范围内的单元格才能被获取 | | `Scan setFilter(Filter filter)` | 指定Filter来过滤掉不需要的数据 | | `Scan setStartRow(byte[] startRow)` | 限定开始的行,否则从表头开始 | | `Scan setStopRow(byte[] stopRow)` | 限定结束的行(不含此行) | | `Scan setBatch(int batch)` | 限定最多返回的单元格数目。用于防止返回过多的数据,导致OutofMemory错误 | ### 二、操作演示 > 本次使用的是 HBase 2.5.5 版本,下方 API 操作对于 2.x 版本的都适用 #### 2.1 引入依赖包 ```xml <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.7.5</version> <relativePath/> <!-- lookup parent from repository --> </parent> <properties> <java.version>8</java.version> <hbase.client.version>2.5.5-hadoop3</hbase.client.version> </properties> <dependencies> <!-- springboot启动依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <!-- 该依赖不会向下传递 --> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>${hbase.client.version}</version> <exclusions> <exclusion> <artifactId>log4j</artifactId> <groupId>log4j</groupId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter</artifactId> <version>5.7.0</version> <scope>test</scope> </dependency> </dependencies> ``` #### 2.2 连接HBase步骤 > 通过 HBase API 进行操作通常需要以下三步: > > + 创建配置文件,设置HBase的连接地址 > + 创建连接 > + 调用相应API执行相关操作 ```java public static void main(String[] args) throws Exception{ //1.创建配置文件,设置HBase的连接地址 Configuration conf=HbaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "192.168.184.129:2181,192.168.184.130:2181"); //2.创建连接 Connection connection = ConnectionFactory.ceateConnection(conf); /** * 3、执行操作(操作技巧): * 对表的结构进行操作 则getAdmin * 对表的数据进行操作 则getTable */ Admin admin = connection.getAdmin(); Table stu = connection.getTable(TableName.valueOf("student")); connection.close(); } ``` ### 三、API操作示例 > 在使用HBase API时,一般会将相应方法封装成一个工具类,使用起来更方便快捷。 + 工具类`HBaseUtils.java` ```java import javafx.util.Pair; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.filter.FilterList; import org.apache.hadoop.hbase.util.Bytes; import java.io.IOException; import java.util.List; public class HBaseUtils { private static Connection connection; static { // 1. 创建 HBase 配置文件,设置 HBase 连接地址 Configuration configuration = HBaseConfiguration.create(); configuration.set("hbase.zookeeper.property.clientPort", "2181"); // 如果是集群 则主机名用逗号分隔 configuration.set("hbase.zookeeper.quorum", "192.168.184.129"); try { // 2. 创建 HBase 连接 connection = ConnectionFactory.createConnection(configuration); // 3. 执行操作: // 对表的结构进行操作使用 getAdmin // 对表的数据进行操作使用 getTable } catch (IOException e) { e.printStackTrace(); } } /** * 创建 HBase 表 * * @param tableName 表名 * @param columnFamilies 列族的数组 */ public static boolean createTable(String tableName, List<String> columnFamilies) { try { // 1. 判断表是否存在 HBaseAdmin admin = (HBaseAdmin) connection.getAdmin(); if (admin.tableExists(TableName.valueOf(tableName))) { return false; } // 2. 构建表描述构建器 TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName)); columnFamilies.forEach(columnFamily -> { // 3. 构建列族描述构建器 ColumnFamilyDescriptorBuilder cfDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily)); cfDescriptorBuilder.setMaxVersions(1); // 4. 构建列族描述 ColumnFamilyDescriptor familyDescriptor = cfDescriptorBuilder.build(); // 5. 构建表描述 tableDescriptor.setColumnFamily(familyDescriptor); }); // 6. 创建表 admin.createTable(tableDescriptor.build()); } catch (IOException e) { e.printStackTrace(); } return true; } /** * 删除 hBase 表 * * @param tableName 表名 */ public static boolean deleteTable(String tableName) { try { HBaseAdmin admin = (HBaseAdmin) connection.getAdmin(); if(admin.tableExists(TableName.valueOf(tableName))){ // 删除表前需要先禁用表 admin.disableTable(TableName.valueOf(tableName)); admin.deleteTable(TableName.valueOf(tableName)); } } catch (Exception e) { e.printStackTrace(); } return true; } /** * 插入数据 * * @param tableName 表名 * @param rowKey 唯一标识 * @param columnFamilyName 列族名 * @param qualifier 列标识 * @param value 数据 */ public static boolean putRow(String tableName, String rowKey, String columnFamilyName, String qualifier, String value) { try { Table table = connection.getTable(TableName.valueOf(tableName)); // 构建 put 对象 Put put = new Put(Bytes.toBytes(rowKey)); put.addColumn(Bytes.toBytes(columnFamilyName), Bytes.toBytes(qualifier), Bytes.toBytes(value)); table.put(put); table.close(); } catch (IOException e) { e.printStackTrace(); } return true; } /** * 插入数据 * * @param tableName 表名 * @param rowKey 唯一标识 * @param columnFamilyName 列族名 * @param pairList 列标识和值的集合 */ public static boolean putRow(String tableName, String rowKey, String columnFamilyName, List<Pair<String, String>> pairList) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Put put = new Put(Bytes.toBytes(rowKey)); pairList.forEach(pair -> put.addColumn(Bytes.toBytes(columnFamilyName), Bytes.toBytes(pair.getKey()), Bytes.toBytes(pair.getValue()))); table.put(put); table.close(); } catch (IOException e) { e.printStackTrace(); } return true; } /** * 根据 rowKey 获取指定行的数据 * * @param tableName 表名 * @param rowKey 唯一标识 */ public static Result getRow(String tableName, String rowKey) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Get get = new Get(Bytes.toBytes(rowKey)); return table.get(get); } catch (IOException e) { e.printStackTrace(); } return null; } /** * 获取指定行指定列 (cell) 的最新版本的数据 * * @param tableName 表名 * @param rowKey 唯一标识 * @param columnFamily 列族 * @param qualifier 列标识 */ public static String getCell(String tableName, String rowKey, String columnFamily, String qualifier) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Get get = new Get(Bytes.toBytes(rowKey)); if (!get.isCheckExistenceOnly()) { get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier)); Result result = table.get(get); byte[] resultValue = result.getValue(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier)); return Bytes.toString(resultValue); } else { return null; } } catch (IOException e) { e.printStackTrace(); } return null; } /** * 检索全表 * * @param tableName 表名 */ public static ResultScanner getScanner(String tableName) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Scan scan = new Scan(); return table.getScanner(scan); } catch (IOException e) { e.printStackTrace(); } return null; } /** * 检索表中指定数据 * * @param tableName 表名 * @param filterList 过滤器 */ public static ResultScanner getScanner(String tableName, FilterList filterList) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Scan scan = new Scan(); scan.setFilter(filterList); return table.getScanner(scan); } catch (IOException e) { e.printStackTrace(); } return null; } /** * 检索表中指定数据 * * @param tableName 表名 * @param startRowKey 起始 RowKey * @param endRowKey 终止 RowKey * @param filterList 过滤器 */ public static ResultScanner getScanner(String tableName, String startRowKey, String endRowKey, FilterList filterList) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Scan scan = new Scan(); scan.withStartRow(Bytes.toBytes(startRowKey)); scan.withStopRow(Bytes.toBytes(endRowKey)); scan.setFilter(filterList); return table.getScanner(scan); } catch (IOException e) { e.printStackTrace(); } return null; } /** * 删除指定行记录 * * @param tableName 表名 * @param rowKey 唯一标识 */ public static boolean deleteRow(String tableName, String rowKey) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Delete delete = new Delete(Bytes.toBytes(rowKey)); table.delete(delete); } catch (IOException e) { e.printStackTrace(); } return true; } /** * 删除指定行指定列 * * @param tableName 表名 * @param rowKey 唯一标识 * @param familyName 列族 * @param qualifier 列标识 */ public static boolean deleteColumn(String tableName, String rowKey, String familyName, String qualifier) { try { Table table = connection.getTable(TableName.valueOf(tableName)); Delete delete = new Delete(Bytes.toBytes(rowKey)); delete.addColumn(Bytes.toBytes(familyName), Bytes.toBytes(qualifier)); table.delete(delete); table.close(); } catch (IOException e) { e.printStackTrace(); } return true; } } ``` + 测试`HBaseUtilsTest.java` ```java import com.lilinchao.utils.HBaseUtils; import javafx.util.Pair; import org.apache.hadoop.hbase.CompareOperator; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.filter.FilterList; import org.apache.hadoop.hbase.filter.SingleColumnValueFilter; import org.apache.hadoop.hbase.util.Bytes; import org.junit.jupiter.api.Assertions; import org.junit.jupiter.api.DisplayName; import org.junit.jupiter.api.Test; import java.util.Arrays; import java.util.List; @DisplayName("HBase 相关操作测试") public class HBaseUtilsTest extends Assertions { private static final String TABLE_NAME = "class"; private static final String TEACHER = "teacher"; private static final String STUDENT = "student"; /** * 创建 HBase 表空间 */ @Test public void createTable() { // 新建表 List<String> columnFamilies = Arrays.asList(TEACHER, STUDENT); boolean table = HBaseUtils.createTable(TABLE_NAME, columnFamilies); System.out.println("表创建结果:" + table); } /** * 插入数据 */ @Test public void insertData() { List<Pair<String, String>> pairs1 = Arrays.asList(new Pair<>("name", "Tom"), new Pair<>("age", "22"), new Pair<>("gender", "1")); HBaseUtils.putRow(TABLE_NAME, "rowKey1", STUDENT, pairs1); List<Pair<String, String>> pairs2 = Arrays.asList(new Pair<>("name", "Jack"), new Pair<>("age", "33"), new Pair<>("gender", "2")); HBaseUtils.putRow(TABLE_NAME, "rowKey2", STUDENT, pairs2); List<Pair<String, String>> pairs3 = Arrays.asList(new Pair<>("name", "Mike"), new Pair<>("age", "44"), new Pair<>("gender", "1")); HBaseUtils.putRow(TABLE_NAME, "rowKey3", STUDENT, pairs3); } /** * 根据 rowKey 获取一行数据 */ @Test public void getRow() { Result result = HBaseUtils.getRow(TABLE_NAME, "rowKey1"); if (result != null) { System.out.println(Bytes .toString(result.getValue(Bytes.toBytes(STUDENT), Bytes.toBytes("name")))); } } /** * 获取指定行,指定列的数据 */ @Test public void getCell() { String cell = HBaseUtils.getCell(TABLE_NAME, "rowKey2", STUDENT, "age"); System.out.println("cell age :" + cell); } /** * 扫描全表,打印 rowKey 和 name */ @Test public void getScanner() { ResultScanner scanner = HBaseUtils.getScanner(TABLE_NAME); if (scanner != null) { scanner.forEach(result -> System.out.println(Bytes.toString(result.getRow()) + "->" + Bytes .toString(result.getValue(Bytes.toBytes(STUDENT), Bytes.toBytes("name"))))); scanner.close(); } } /** * 根据指定条件查询数据 * 通过过滤器拼接过滤条件 */ @Test public void getScannerWithFilter() { FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL); SingleColumnValueFilter nameFilter = new SingleColumnValueFilter(Bytes.toBytes(STUDENT), Bytes.toBytes("name"), CompareOperator.EQUAL, Bytes.toBytes("Jack")); filterList.addFilter(nameFilter); ResultScanner scanner = HBaseUtils.getScanner(TABLE_NAME, filterList); if (scanner != null) { scanner.forEach(result -> System.out.println(Bytes.toString(result.getRow()) + "->" + Bytes .toString(result.getValue(Bytes.toBytes(STUDENT), Bytes.toBytes("name"))))); scanner.close(); } } /** * 根据指定行,列删除数据 */ @Test public void deleteColumn() { boolean b = HBaseUtils.deleteColumn(TABLE_NAME, "rowKey2", STUDENT, "age"); System.out.println("删除结果: " + b); } /** * 删除指定行数据 */ @Test public void deleteRow() { boolean b = HBaseUtils.deleteRow(TABLE_NAME, "rowKey2"); System.out.println("删除结果: " + b); } /** * 删除整个表空间 */ @Test public void deleteTable() { boolean b = HBaseUtils.deleteTable(TABLE_NAME); System.out.println("删除结果: " + b); } } ``` *附参考文章链接* *https://juejin.cn/post/6844903949732937735*
标签:
Hbase
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/2851.html
上一篇
IDEA编译运行Spark源码
下一篇
HBase过滤器介绍
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Git
MyBatisX
CentOS
容器深入研究
散列
JavaWEB项目搭建
Docker
Zookeeper
Flume
Spark
SpringBoot
Thymeleaf
Elastisearch
Netty
Flink
Sentinel
Spark Streaming
Java阻塞队列
线程池
Azkaban
设计模式
Spark RDD
Spark Core
FastDFS
Spring
Map
Eclipse
Jquery
Typora
高并发
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭