
07.DStream优雅关闭
[TOC]前言流式任务需要 7*24 小时执行,但是有时涉及到升级代码需要主动停止程序,但是分布式程序,没办法做到一个个进程去杀死,所有配置优雅的关闭就显得至关重要了。一、概念非优雅关闭两种方式:kill -9 processIdyarn -kill applicationId弊端:由于Spark Streaming是基于micro-batch机制工作的,按照间隔时间生成RDD,如果在间隔期...
06.DStream输出
[TOC]一、概念 输出操作允许DStream的操作推到如数据库、文件系统等外部系统中。因为输出操作实际上是允许外部系统消费转换后的数据,它们触发的实际操作是DStream转换。与 RDD 中的惰性求值类似,如果一个 DStream 及其派生出的 DStream 都没有被执行输出操作,那么这些 DStream 就都不会被求值。如果 StreamingContext 中没有设定...
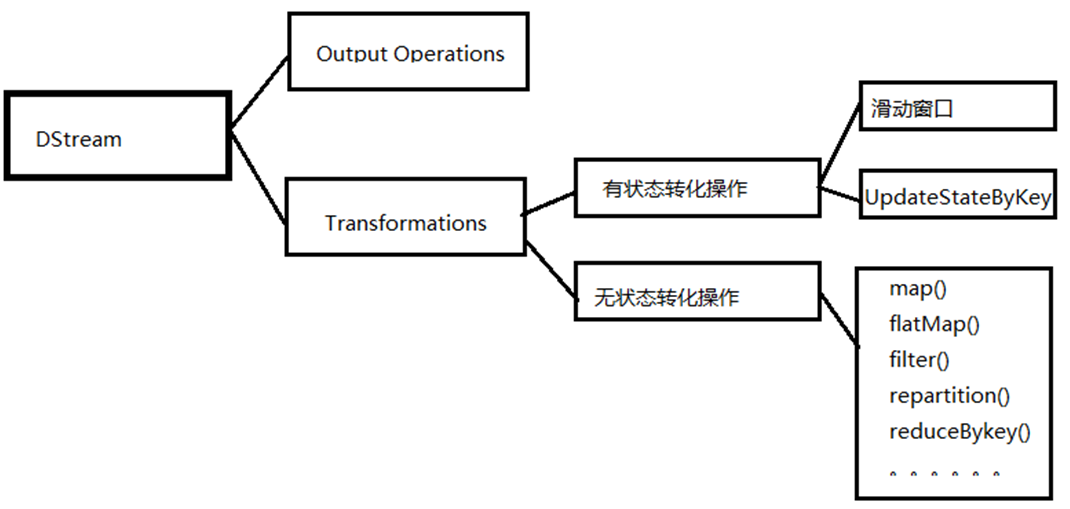
05.DStream转换
[TOC]一、概念DStream的原语与RDD类似,分分为转换(Transformation)和输出(Output)两种,此外还有一些特殊的原语,如:updateStateByKey,transform以及各种窗口(window)相关的原语。转换分类:DStream转换操作包括无状态转换和有状态转换。无状态转换:每个批次的处理不依赖于之前批次的数据。有状态转换:当前批次的处理需要使用之前批次...
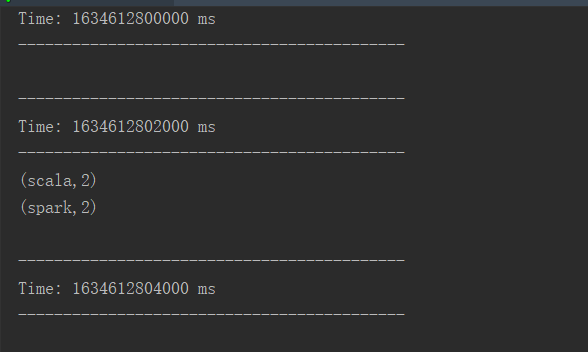
04.SparkStreaming之Kafka数据源
[TOC]一、概述1.1 概念kafka作为一个实时的分布式消息队列,实时的生产和消费消息,这里我们可以利用SparkStreaming实时计算框架实时地读取kafka中的数据然后进行计算。1.2 创建DStream方式在spark1.3版本后,kafkaUtils里面提供了两个创建dstream的方法:KafkaUtils.createDstream(需要receiver接收)Receiv...
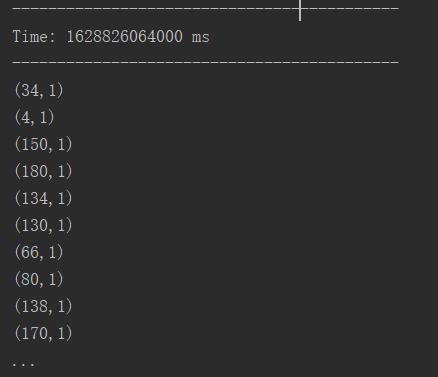
03.DStream创建
[TOC]一、RDD队列1.1 用法及说明 测试过程中,可以通过使用 ssc.queueStream(queueOfRDDs)来创建 DStream,每一个推送到 这个队列中的 RDD,都会作为一个 DStream 处理。1.2 案例实操需求循环创建几个RDD,将 RDD放入队列。通过SparkStream创建Dstream,计算WordCount。实现代码import or...
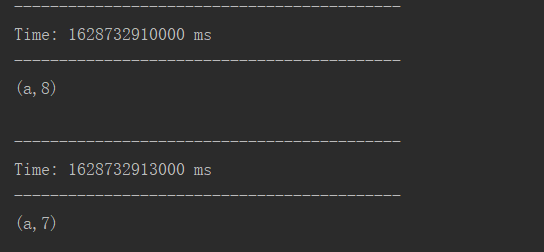
02.DStream入门
[TOC]前言本篇将通过一个WordCount案例来作为DStream的入门。一、环境1.1 所需运行环境IP作用系统192.168.10.2(本机)运行案例代码接收服务端9999端口发送的信息windows192.168.10.7运行netcat监听9999端口Linux1.2 netcat工具介绍和安装介绍 netcat简称nc,netcat是网络工具中的瑞士军刀,它能通过TCP...

01.SparkStreaming概述
[TOC]前言在介绍SparkStreaming之前需要先理解几个概念:流式计算流式计算的上游算子处理完一条数据后,会立马发送给下游算子,所以一条数据从进入流式系统到输出结果的时间间隔较短(当然有的流式系统为了保证吞吐,也会对数据做buffer)。批量计算批量计算按数据块来处理数据,每一个task接收一定大小的数据块,比如MR,map任务在处理完一个完整的数据块后(比如128M),然后将中间...