李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
05.DStream转换
Leefs
2021-10-22 AM
1589℃
0条
[TOC] ### 一、概念 DStream的原语与RDD类似,分分为**转换(Transformation)**和**输出(Output)**两种,此外还有一些特殊的原语,如:updateStateByKey,transform以及各种窗口(window)相关的原语。 **转换分类:** DStream转换操作包括**无状态转换**和**有状态转换**。 + **无状态转换:**每个批次的处理不依赖于之前批次的数据。 + **有状态转换:**当前批次的处理需要使用之前批次的数据或者中间结果。有状态转换包括基于滑动窗口的转换和追踪状态变化的转换(updateStateByKey)。 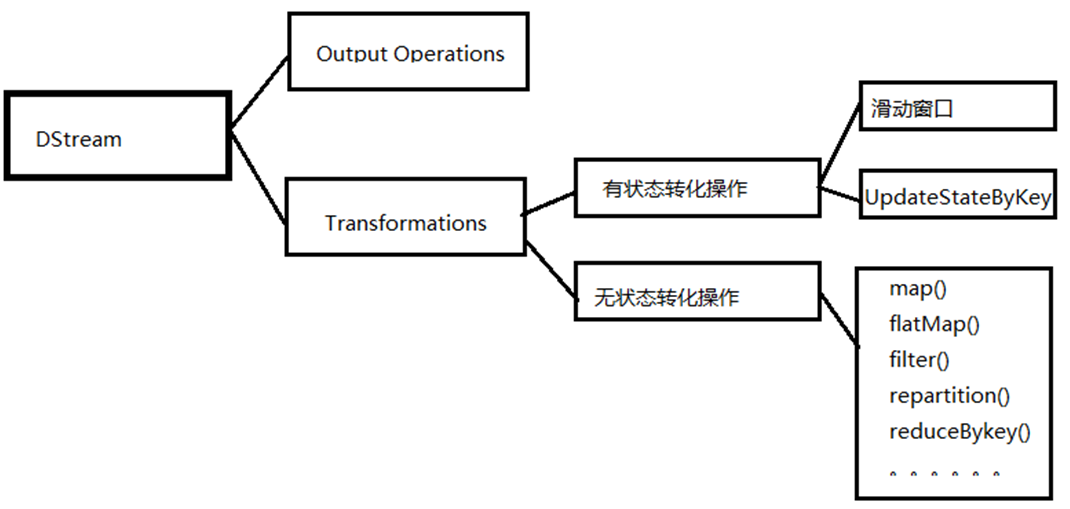 ### 二、无状态转换 无状态的转化操作,就是把简单的RDD转化操作应用到每个批次上,也就是转化DStream中的每一个RDD。 *注意:针对键值对的 DStream 转化操作(比如 reduceByKey())要添加 `import StreamingContext._`才能在 Scala 中使用。* | 函数名称 | **目的** | Scala示例 | 用来操作DStream[T]的用户自定义函数的函数签名 | | ------------- | ------------------------------------------------------------ | ----------------------------- | -------------------------------------------- | | map() | 对DStream中的每个元素应用给定函数,返回由各元素输出的元素组成的DStream | ds.map(x => x+1) | f:(T) -> U | | flatMap() | 对DStream中的每个元素应用给定函数,返回由各元素输出的迭代器组成的DStream | ds.flatMap(x => x.split("\t") | f:T -> Iterable[U] | | filter() | 返回由给定DStream中通过筛选的元素组成的DStream | ds.filter(x => x!=1) | f:T -> T | | repartition() | 改变DStream的分区数 | ds.repartition(10) | N/A | | reduceByKey() | 将每个批次中键相同的记录归约 | ds.reduceByKey((x,y) => x+ y) | f:T,T->T | | groupByKey() | 将每个批次中的记录根据键分组 | ds.groupByKey() | N/A | 需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个 DStream 在内部 是由许多RDD(批次)组成,且无状态转化操作是分别应用到每个RDD上的。 *例如:reduceByKey()会归约每个时间区间中的数据,但不会归约不同区间之间的数据。* #### 2.1 Transform Transform允许DStream上执行任意的 RDD-to-RDD 函数。即使这些函数并没有在DStream的API中暴露出来,通过该函数可以方便的扩展Spark API。 该函数每一批次调度一次。 其实也就是对DStream中的 RDD 应用转换。 **代码示例** ```scala import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @author lilinchao * @date 2021/10/20 * @description 1.0 **/ object Transform { def main(args: Array[String]): Unit = { //创建 SparkConf val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount") //创建 StreamingContext val ssc = new StreamingContext(sparkConf, Seconds(3)) val lineDStream = ssc.socketTextStream("127.0.0.1",9999) //转换为 RDD 操作 val wordAndCountDStream: DStream[(String, Int)] = lineDStream.transform(rdd => { val words: RDD[String] = rdd.flatMap(_.split(" ")) val wordAndOne: RDD[(String, Int)] = words.map((_, 1)) val value: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _) value }) //打印 wordAndCountDStream.print //启动 ssc.start() ssc.awaitTermination() } } ``` **netcat输入数据**  **运行结果**  #### 2.2 join 两个流之间的 join 需要两个流的批次大小一致,这样才能做到同时触发计算。计算过程就是对当前批次的两个流中各自的RDD进行join,与两个RDD的join效果相同。 **代码示例** ```scala import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @author lilinchao * @date 2021/10/20 * @description 1.0 **/ object JoinTest { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming") val ssc = new StreamingContext(sparkConf, Seconds(5)) val data9999 = ssc.socketTextStream("localhost", 9999) val data8888 = ssc.socketTextStream("localhost", 8888) val map9999: DStream[(String, Int)] = data9999.map((_,9)) val map8888: DStream[(String, Int)] = data8888.map((_,8)) // 所谓的DStream的Join操作,其实就是两个RDD的join val joinDS: DStream[(String, (Int, Int))] = map9999.join(map8888) joinDS.print() ssc.start() ssc.awaitTermination() } } ``` ### 三、有状态转化 #### 3.1 UpdateStateByKey `UpdateStateByKey`原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加 wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。 给定一个由(键,事件)对构成的DStream,并传递一个指定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的DStream,其内部数 据为(键,状态) 对。 updateStateByKey() 的结果会是一个新的DStream,其内部的RDD序列是由每个时间区间对应的(键,状态)对组成的。 **功能** updateStateByKey操作使得我们可以在用新信息进行更新时保持任意的状态。为使用这个功能,需要做下面两步: 1. 定义状态,状态可以是一个任意的数据类型。 2. 定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新。 使用 updateStateByKey需要对检查点目录进行配置,会使用检查点来保存状态。 **代码示例** ```scala import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @author lilinchao * @date 2021/10/20 * @description 1.0 **/ object UpdateStateByKeyTest { def main(args: Array[String]): Unit = { // 定义更新状态方法,参数 values 为当前批次单词频度,state 为以往批次单词频度 val updateFunc = (values: Seq[Int], state: Option[Int]) => { val currentCount = values.foldLeft(0)(_ + _) val previousCount = state.getOrElse(0) Some(currentCount + previousCount) } val conf = new SparkConf().setMaster("local[*]").setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, Seconds(3)) ssc.checkpoint("./ck") val lines = ssc.socketTextStream("localhost", 9999) val words = lines.flatMap(_.split(" ")) val pairs = words.map(word => (word, 1)) // 使用 updateStateByKey 来更新状态,统计从运行开始以来单词总的次数 val stateDstream = pairs.updateStateByKey[Int](updateFunc) stateDstream.print() ssc.start() ssc.awaitTermination() //ssc.stop() } } ``` **netcat输入数据** ```bash [root@root ~]# nc -lp 9999 hello spark hello scala ``` **运行结果**  #### 3.2 窗口操作(Window Operations) 窗口操作可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Streaming的允许状态。 基于窗口的操作会在一个比StreamingContext的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。  **说明** 窗口在源DStream上滑动,合并和操作落入窗内的源RDDs,产生窗口化的DStream的RDDs。 在这个具体的例子中,程序在三个时间单元的数据上进行窗口操作,并且每两个时间单元滑动一次。这说明,任何一个窗口操作都需要指定两个参数: - **窗口长度:**窗口的持续时间 - **滑动的时间间隔:**窗口操作执行的时间间隔 这两个参数必须是源DStream的批时间间隔的倍数。 **代码示例** > 3 秒一个批次,窗口 12 秒,滑步 6 秒。 ```scala import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} /** * @author lilinchao * @date 2021/10/21 * @description 1.0 **/ object WindowOperationsTest { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[2]").setAppName("WindowOperationsTest") val ssc = new StreamingContext(conf, Seconds(3)) ssc.checkpoint("./ck") val lines = ssc.socketTextStream("192.168.1.172", 9999) val words = lines.flatMap(_.split(" ")) val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b),Seconds(12), Seconds(6)) wordCounts.print() ssc.start() ssc.awaitTermination() } } ``` **netcat输入数据** ```bash [root@root ~]# nc -lk 9999 a a a a a aa aaa aaa ``` **运行结果**  **Window的操作方法** + **window(windowLength, slideInterval):** 基于对源 DStream 窗化的批次进行计算返回一个新的 Dstream; + **countByWindow(windowLength, slideInterval):** 返回一个滑动窗口计数流中的元素个数; + **reduceByWindow(func, windowLength, slideInterval):** 通过使用自定义函数整合滑动区间 流元素来创建一个新的单元素流; + **reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]):** 当在一个(K,V) 对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数 据使用reduce函数来整合每个key的value值。 + **reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]):** 这个函数是上述函数的变化版本,每个窗口的reduce值都是通过用前一个窗的reduce值来递增计算。 通过 reduce 进入到滑动窗口数据并”反向 reduce”离开窗口的旧数据来实现这个操作。 一个例子是随着窗口滑动对 keys 的“加”“减”计数。通过前边介绍可以想到,这个函数只适用于”可逆的 reduce函数”,也就是这些 reduce 函数有相应的”反 reduce”函数(以参数invFunc形式传入)。如前述函数,reduce任务的数量通过可选参数来配置。  ```scala val ipDStream = accessLogsDStream.map(logEntry => (logEntry.getIpAddress(), 1)) val ipCountDStream = ipDStream.reduceByKeyAndWindow( {(x, y) => x + y}, {(x, y) => x - y}, Seconds(30), Seconds(10)) //加上新进入窗口的批次中的元素 //移除离开窗口的老批次中的元素 //窗口时长// 滑动步长 ``` + countByWindow()和 countByValueAndWindow()作为对数据进行计数操作的简写。 + countByWindow()返回一个表示每个窗口中元素个数的DStream,而countByValueAndWindow()返回的 DStream则包含窗口中每个值的个数。 ```scala val ipDStream = accessLogsDStream.map{entry => entry.getIpAddress()} val ipAddressRequestCount = ipDStream.countByValueAndWindow(Seconds(30), Seconds(10)) val requestCount = accessLogsDStream.countByWindow(Seconds(30), Seconds(10)) ``` *附:参考文章链接* *https://www.kancloud.cn/kancloud/spark-programming-guide/51567*
标签:
Spark
,
Spark Streaming
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1591.html
上一篇
04.SparkStreaming之Kafka数据源
下一篇
06.DStream输出
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Spark Streaming
ajax
Git
Golang基础
Java
队列
Filter
nginx
Scala
JavaScript
Quartz
Livy
机器学习
HDFS
国产数据库改造
排序
Redis
Zookeeper
RSA加解密
Map
递归
散列
Jenkins
Java编程思想
SpringCloudAlibaba
正则表达式
Python
Netty
Java阻塞队列
Spark
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭