李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
04.SparkStreaming之Kafka数据源
Leefs
2021-10-21 PM
1581℃
0条
[TOC] ### 一、概述 #### 1.1 概念 kafka作为一个实时的分布式消息队列,实时的生产和消费消息,这里我们可以利用SparkStreaming实时计算框架实时地读取kafka中的数据然后进行计算。 #### 1.2 创建DStream方式 在spark1.3版本后,kafkaUtils里面提供了两个创建dstream的方法: + **KafkaUtils.createDstream(需要receiver接收)** Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启多个,再手动合并数据(union),再进行处理,很麻烦。 + **KafkaUtils.createDirectStream(Direct直连方式)** Direct方式是直接连接kafka分区来获取数据,从每个分区直接读取数据大大提高了并行能力。 #### 1.3 Direct直连方式优点 推荐使用KafkaUtils.createDirectStream的方式相比基于Receiver方式有几个优点: + 简化并行 不需要创建多个kafka输入流,然后union它们,sparkStreaming将会创建和kafka分区一种的rdd的分区数,而且会从kafka中并行读取数据,spark中RDD的分区数和kafka中的分区数据是一一对应的关系。 + 高效 第一种实现数据的零丢失是将数据预先保存在WAL中,会复制一遍数据,会导致数据被拷贝两次,第一次是被kafka复制,另一次是写到WAL中。而没有receiver的这种方式消除了这个问题。 + 恰好一次语义(Exactly-once-semantics) Receiver读取kafka数据是通过kafka高层次api把偏移量写入zookeeper中,虽然这种方法可以通过数据保存在WAL中保证数据不丢失,但是可能会因为sparkStreaming和ZK中保存的偏移量不一致而导致数据被消费了多次。EOS通过实现kafka低层次api,偏移量仅仅被ssc保存在checkpoint中,消除了zk和ssc偏移量不一致的问题。缺点是无法使用基于zookeeper的kafka监控工具。 + 版本限制 开发中SparkStreaming和kafka集成有两个版本:0.8及0.10+ 0.8版本有Receiver和Direct模式(但是0.8版本生产环境问题较多,在Spark2.3之后不支持0.8版本了) 0.10以后只保留了direct模式(Reveiver模式不适合生产环境),并且0.10版本API有变化(更加强大) ### 二、整合流程 本次我们只通过KafkaUtils.createDirectStream的方式进行整合。 本次使用到的Kafka版本2.8.0。 ##### 2.1 通过命令在Kafka中创建Topic ```bash # 创建Topic kafka_spark [root@hadoopserver kafka_2.12-2.8.0]# bin/kafka-topics.sh --zookeeper 192.168.159.135:2181 --create --topic kafka_spark --partitions 2 --replication-factor 1 # 查看Topic列表 [root@hadoopserver kafka_2.12-2.8.0]# bin/kafka-topics.sh --zookeeper localhost:2181 --list __consumer_offsets demo first kafkaDemo kafka_spark ``` ##### 2.2 在项目中引入pom依赖 ```xml <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.12</artifactId> <version>2.4.3</version> </dependency> ``` ##### 2.3 编写Scala代码 ```scala import org.apache.spark.SparkConf import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies} import org.apache.spark.streaming.{Seconds, StreamingContext} import scala.collection.mutable /** * @author lilinchao * @date 2021/10/19 * @description Spark Streaming整合Kafka **/ object KafkaDirectWordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("DirectKafka").setMaster("local[2]") val ssc = new StreamingContext(conf, Seconds(2)) val topicsSet = Array("kafka_spark") val kafkaParams = mutable.HashMap[String, String]() //必须添加以下参数,否则会报错 kafkaParams.put("bootstrap.servers", "192.168.159.135:9092") kafkaParams.put("group.id", "group1") kafkaParams.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") kafkaParams.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") val messages = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams)) val lines = messages.map(_.value) val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _) wordCounts.print() // Start the computation ssc.start() ssc.awaitTermination() } } ``` **运行代码!** ##### 2.4 Kafka客户端启动生产者,想Topic中写入数据 ```bash [root@hadoopserver kafka_2.12-2.8.0]# bin/kafka-console-producer.sh --broker-list 192.168.159.135:9092 --topic kafka_spark >spark scala spark scala ``` **运行结果** 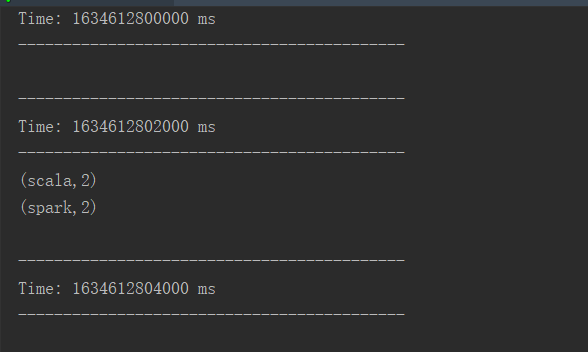 *附:* *参考文章链接:https://www.jianshu.com/p/ec3bf53dcf3f*
标签:
Spark
,
Spark Streaming
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1583.html
上一篇
03.DStream创建
下一篇
05.DStream转换
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
散列
Thymeleaf
数学
JavaSE
递归
Redis
微服务
RSA加解密
Hive
Java阻塞队列
Python
算法
Livy
线程池
Flink
栈
字符串
二叉树
Nacos
工具
Stream流
Yarn
并发线程
Linux
序列化和反序列化
Typora
Quartz
Java
nginx
Jquery
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭