李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
HBase过滤器介绍
Leefs
2023-09-13 PM
3703℃
1条
[TOC] ### 前言 本次使用的是 HBase 2.5.5 版本,同时本篇是基于上一篇: [Hbase之JavaAPI详细介绍](https://lilinchao.com/archives/2851.html)的基础上整理的,如果需要运行演示,请先阅读上一篇内容。 ### 一、HBase过滤器简介 HBase 提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predicate push down)。这样可以保证过滤掉的数据不会被传送到客户端,从而减轻网络传输和客户端处理的压力。 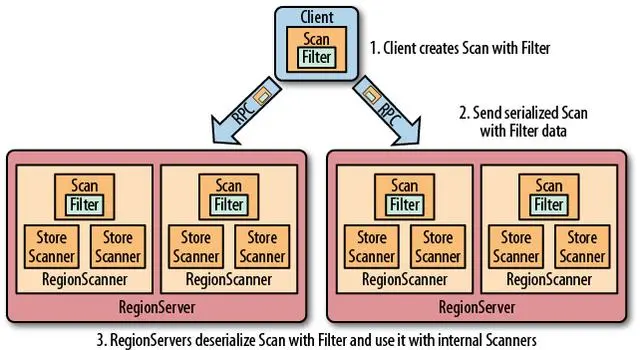 ### 二、过滤器基础 #### 2.1 Filter接口和FilterBase抽象类 Filter 接口中定义了过滤器的基本方法,`FilterBase` 抽象类实现了 Filter 接口。所有内置的过滤器则直接或者间接继承自 `FilterBase` 抽象类。用户只需要将定义好的过滤器通过 `setFilter` 方法传递给 `Scan` 或 `put` 的实例即可。 ```java setFilter(Filter filter) ``` ```java // Scan 中定义的 setFilter @Override public Scan setFilter(Filter filter) { super.setFilter(filter); return this; } ``` ```java // Get 中定义的 setFilter @Override public Get setFilter(Filter filter) { super.setFilter(filter); return this; } ``` #### 2.2 过滤器 **HBase 内置过滤器可以分为三类**: + **比较过滤器**:可应用于rowkey、列簇、列、列值过滤器 + **专用过滤器**:只能适用于特定的过滤器 + **包装过滤器**:包装过滤器就是通过包装其他过滤器以实现某些拓展的功能。 ### 三、比较过滤器 所有比较过滤器均继承自 `CompareFilter`。创建一个比较过滤器需要两个参数,分别是**比较运算符**和**比较器实例**。 ```java public CompareFilter(final CompareOp compareOp,final ByteArrayComparable comparator) { this.compareOp = compareOp; this.comparator = comparator; } ``` #### 3.1 比较运算符 比较运算符均定义在枚举类 `CompareOperator` 中 ```java @InterfaceAudience.Public public enum CompareOperator { LESS, LESS_OR_EQUAL, EQUAL, NOT_EQUAL, GREATER_OR_EQUAL, GREATER, NO_OP, } ``` > 注意:在 1.x 版本的 HBase 中,比较运算符定义在 `CompareFilter.CompareOp` 枚举类中,但在 2.0 之后这个类就被标识为 @deprecated ,并会在 3.0 移除。所以 2.0 之后版本的 HBase 需要使用 `CompareOperator` 这个枚举类。 **类型说明** | 类型 | 符号 | 说明 | | ---------------- | ---- | -------------------- | | LESS | < | 小于 | | LESS_OR_EQUAL | <= | 小于等于 | | EQUAL | = | 等于 | | NOT_EQUAL | != | 不等于 | | GREATER_OR_EQUAL | >= | 大于等于 | | GREATER | > | 大于 | | NO_OP | | 排除所有符合条件的值 | #### 3.2 比较器 所有比较器均继承自 `ByteArrayComparable` 抽象类,常用的有以下几种: | 比较器 | 含义 | | ---------------------- | ------------------------------------------------------------ | | BinaryComparator | 使用 `Bytes.compareTo(byte [],byte [])` 按字典序比较指定的字节数组。 | | BinaryPrefixComparator | 按字典序与指定的字节数组进行比较,但只比较到这个字节数组的长度。 | | RegexStringComparator | 使用给定的正则表达式与指定的字节数组进行比较。仅支持 `EQUAL` 和 `NOT_EQUAL` 操作。 | | SubStringComparator | 测试给定的子字符串是否出现在指定的字节数组中,比较不区分大小写。仅支持 `EQUAL` 和 `NOT_EQUAL` 操作。 | | NullComparator | 判断给定的值是否为空。 | | BitComparator | 按位进行比较。 | > `BinaryPrefixComparator` 和 `BinaryComparator` 的区别不是很好理解,这里举例说明一下 在进行 `EQUAL` 的比较时,如果比较器传入的是 `abcd` 的字节数组,但是待比较数据是 `abcdefgh`: - 如果使用的是 `BinaryPrefixComparator` 比较器,则比较以 `abcd` 字节数组的长度为准,即 `efgh` 不会参与比较,这时候认为 `abcd` 与 `abcdefgh` 是满足 `EQUAL` 条件的; - 如果使用的是 `BinaryComparator` 比较器,则认为其是不相等的。 #### 3.3 比较过滤器种类 比较过滤器共有五个(Hbase 1.x 版本和 2.x 版本相同),见下图:  **说明** | 比较过滤器 | 说明 | | --------------------- | ------------------------------------------------------------ | | RowFilter | 基于行键来过滤数据; | | FamilyFilter | 基于列族来过滤数据; | | QualifierFilter | 基于列限定符(列名)来过滤数据; | | ValueFilter | 基于单元格 (cell) 的值来过滤数据; | | DependentColumnFilter | 指定一个参考列来过滤其他列的过滤器,过滤的原则是基于参考列的时间戳来进行筛选 。 | 前四种过滤器的使用方法相同,均只要传递比较运算符和运算器实例即可构建,然后通过 `setFilter` 方法传递给 `scan`: ```java Filter filter = new RowFilter(CompareOperator.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("xxx"))); scan.setFilter(filter); ``` `DependentColumnFilter` 的使用稍微复杂一点,这里单独做下说明。 #### 3.4 DependentColumnFilter 可以把 `DependentColumnFilter` 理解为**一个 valueFilter 和一个时间戳过滤器的组合**。 `DependentColumnFilter` 有三个带参构造器,这里选择一个参数最全的进行说明: ```java DependentColumnFilter(final byte [] family, final byte[] qualifier, final boolean dropDependentColumn, final CompareOperator op, final ByteArrayComparable valueComparator) ``` **参数说明** - **family** :列族 - **qualifier** :列限定符(列名) - **dropDependentColumn** :决定参考列是否被包含在返回结果内,为 true 时表示参考列被返回,为 false 时表示被丢弃 - **op** :比较运算符 - **valueComparator** :比较器 **示例说明** ```java DependentColumnFilter dependentColumnFilter = new DependentColumnFilter( Bytes.toBytes("student"), Bytes.toBytes("name"), false, CompareOperator.EQUAL, new BinaryPrefixComparator(Bytes.toBytes("xiaolan"))); ``` - 首先会去查找 `student:name` 中值以 `xiaolan` 开头的所有数据获得 `参考数据集`,这一步等同于 valueFilter 过滤器; - 其次再用参考数据集中所有数据的时间戳去检索其他列,获得时间戳相同的其他列的数据作为 `结果数据集`,这一步等同于时间戳过滤器; - 最后如果 `dropDependentColumn` 为 true,则返回 `参考数据集`+`结果数据集`,若为 false,则抛弃参考数据集,只返回 `结果数据集`。 #### 3.5 使用示例 > 准备阶段 **(1)示例数据**  **添加示例数据** ```java /** * 创建工作空间 */ @Test public void createTable() { // 新建表 List<String> columnFamilies = Arrays.asList(STU_INFO, GRADES); boolean table = HBaseUtils.createTable(TABLE_NAME, columnFamilies); System.out.println("表创建结果:" + table); } /** * 插入数据 */ @Test public void insertData() { // 添加第一行数据 List<Pair<String, String>> pairs1 = Arrays.asList(new Pair<>("name", "alice"), new Pair<>("age", "18"), new Pair<>("sex", "female")); HBaseUtils.putRow(TABLE_NAME, "001", STU_INFO, pairs1); List<Pair<String, String>> pairs1and = Arrays.asList(new Pair<>("english", "80"), new Pair<>("math", "90")); HBaseUtils.putRow(TABLE_NAME, "001", GRADES, pairs1and); // 添加第二行数据 List<Pair<String, String>> pairs2 = Arrays.asList(new Pair<>("name", "nancy"), new Pair<>("sex", "male"), new Pair<>("class", "1802")); HBaseUtils.putRow(TABLE_NAME, "002", STU_INFO, pairs2); List<Pair<String, String>> pairs2and = Arrays.asList(new Pair<>("english", "85"), new Pair<>("math", "78"), new Pair<>("bigdata", "88")); HBaseUtils.putRow(TABLE_NAME, "002", GRADES, pairs2and); // 添加第三行数据 List<Pair<String, String>> pairs3 = Arrays.asList(new Pair<>("name", "harry"), new Pair<>("age", "19"), new Pair<>("sex", "male"), new Pair<>("class", "1803")); HBaseUtils.putRow(TABLE_NAME, "003", STU_INFO, pairs3); List<Pair<String, String>> pairs3and = Arrays.asList(new Pair<>("english", "90"), new Pair<>("math", "80")); HBaseUtils.putRow(TABLE_NAME, "003", GRADES, pairs3and); } ``` **(2)将输出方法添加到工具类** ```java public static void print(ResultScanner scanner) { try { Result rs = null; while ((rs = scanner.next()) != null) { String id = Bytes.toString(rs.getRow()); //获取一行中的所有单元格 List<Cell> cells = rs.listCells(); StringBuilder sb = new StringBuilder(); sb.append("行键: ").append(id).append("\t"); for (Cell cell : cells) { //每个单元格中包含了rowkey,列簇,列名,版本号,列值 String qualifier = Bytes.toString(CellUtil.cloneQualifier(cell)); String value = Bytes.toString(CellUtil.cloneValue(cell)); sb.append(qualifier).append(": ").append(value).append("\t"); String s = sb.toString(); sb = new StringBuilder(); System.out.print(s); } //遍历一行后换行 System.out.println(); } } catch (IOException e) { e.printStackTrace(); } } ``` **(3)测试类中添加初始化和结束输出调用方法** ```java private static final String TABLE_NAME = "student_demo"; private static final String STU_INFO = "stuInfo"; private static final String GRADES = "grades"; static FilterList filterList = null; @BeforeAll @DisplayName("初始化 filterList 对象") public static void init(){ filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL); } @AfterAll @DisplayName("打印查询结果到控制台") public static void resultPrint(){ ResultScanner scanner = HBaseUtils.getScanner(TABLE_NAME, filterList); HBaseUtils.print(scanner); } ``` > 比较过滤器使用示例 ```java // -------------------------- 比较过滤器 -------------------------- /** * 通过 rowFilter 过滤 rowKey 小于等于 002 的所有数据 */ @Test @DisplayName("rowKey过滤器: RowFilter 行键过滤器") public void rowFilerTest(){ // 创建 BinaryComparator 比较器 // BinaryComparator: 按字节索引顺序比较指定字节数组 BinaryComparator binaryComparator = new BinaryComparator(Bytes.toBytes("002")); // 创建行键过滤器 RowFilter // RowFilter: rowKey 过滤器,基于行键来过滤数据 // LESS_OR_EQUAL ==> 小于等于(<=) RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.LESS_OR_EQUAL,binaryComparator); filterList.addFilter(rowFilter); } /** * 通过 FamilyFilter 查询列簇名包含 stu 的所有列簇下面的数据 */ @Test @DisplayName("列簇过滤器: FamilyFilter") public void familyFilterTest(){ //创建包含比较器 // SubstringComparator: 判断提供的子串是否出现在其中 SubstringComparator substringComparator = new SubstringComparator(STU_INFO); // 创建列簇过滤器 // FamilyFilter: 列簇过滤器,基于列族来过滤数据 // EQUAL ==> 等于(=) FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL, substringComparator); filterList.addFilter(familyFilter); } /** * 通过 FamilyFilter 与 BinaryPrefixComparator 过滤出列簇以 s 开头的列簇下的所有数据 */ @Test @DisplayName("列簇过滤器: FamilyFilter") public void familyFilterTest2(){ // 创建前缀比较器 // BinaryComparator: 只是比较左端前缀的数据是否相同 BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("s".getBytes()); //创建列簇过滤器 FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL, binaryPrefixComparator); filterList.addFilter(familyFilter); } /** * 通过 QualifierFilter 与 SubstringComparator 查询列名包含 ge 的列的值 */ @Test @DisplayName("列名过滤器: QualifierFilter") public void qualifierFilterTest(){ // 创建包含比较器 SubstringComparator substringComparator = new SubstringComparator("ge"); // 创建列名过滤器 // QualifierFilter: 列过滤器,基于列(列名)来过滤数据 QualifierFilter qualifierFilter = new QualifierFilter(CompareFilter.CompareOp.EQUAL, substringComparator); filterList.addFilter(qualifierFilter); } /** * 列值过滤器比较的是每一个cell,只要一个行中的任意一个值满足都会被列出来 * 列出名字为 alice 的学生 */ @Test @DisplayName("列值过滤器: ValueFilter") public void valueFilterTest(){ //创建二进制前缀比较器 BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("alice".getBytes()); //创建列值过滤器 // ValueFilter: 列值过滤器,基于cell的值来过滤数据 ValueFilter valueFilter = new ValueFilter(CompareFilter.CompareOp.EQUAL, binaryPrefixComparator); filterList.addFilter(valueFilter); } @Test @DisplayName("列值过滤器: ValueFilter") public void valueFilterTest2(){ //创建列值过滤器 ValueFilter valueFilter = new ValueFilter(CompareFilter.CompareOp.GREATER, new BinaryComparator("90".getBytes())); filterList.addFilter(valueFilter); } ``` ### 四、专用过滤器 专用过滤器通常直接继承自 `FilterBase`,适用于范围更小的筛选规则。 #### 4.1 单列列值过滤器 (SingleColumnValueFilter) 基于某列(参考列)的值决定某行数据是否被过滤。其实例有以下方法: | 过滤器 | 默认值 | 说明 | | ----------------------------------------------- | ------ | ------------------------------------------------------------ | | setFilterIfMissing(boolean filterIfMissing) | false | 如果该行数据不包含参考列,其依然被包含在最后的结果中;设置为 true 时,则不包含。 | | setLatestVersionOnly(boolean latestVersionOnly) | true | 只检索参考列的最新版本数据;设置为 false,则检索所有版本数据。 | **使用示例** ```java @Test @DisplayName("单列值过滤器: SingleColumnValueFilter") public void singleColumnValueFilterTest(){ //使用前缀比较器 BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("18".getBytes()); //创建单列值过滤器 // SingleColumnValueFilter: 返回满足条件的cell所在行的所有cell的值(即会返回一行数据) SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter( Bytes.toBytes(STU_INFO), // 列族名称 "age".getBytes(), // 筛选的字段名 CompareFilter.CompareOp.EQUAL, binaryPrefixComparator); singleColumnValueFilter.setFilterIfMissing(true); // singleColumnValueFilter.setLatestVersionOnly(false); filterList.addFilter(singleColumnValueFilter); } ``` #### 4.2 单列列值排除器 (SingleColumnValueExcludeFilter) `SingleColumnValueExcludeFilter` 继承自上面的 `SingleColumnValueFilter`,过滤行为与其相反。 ```java @Test @DisplayName("列值排除过滤器: SingleColumnValueExcludeFilter") public void singleColumnValueExcludeFilter(){ //使用前缀比较器 BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("19".getBytes()); //创建单列值过滤器 // SingleColumnValueExcludeFilter: 与SingleColumnValueFilter相反,会排除掉指定的列,其他的列全部返回 SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter( Bytes.toBytes(STU_INFO), // 列族名称 "age".getBytes(), // 需要排除的列 CompareFilter.CompareOp.EQUAL, binaryPrefixComparator); filterList.addFilter(singleColumnValueExcludeFilter); } ``` #### 4.3 行键前缀过滤器 (PrefixFilter) 基于 RowKey 值决定某行数据是否被过滤。 ```java /** * 通过 PrefixFilter 查询以 00 开头的所有前缀的 rowkey */ @Test @DisplayName("rowkey前缀过滤器: PrefixFilter") public void prefixFilterTest(){ //创建行键前缀过滤器 PrefixFilter prefixFilter = new PrefixFilter("001".getBytes()); filterList.addFilter(prefixFilter); } ``` #### 4.4 列名前缀过滤器 (ColumnPrefixFilter) 基于列限定符(列名)决定某行数据是否被过滤。 ```java /** * 查询列名为 age 的数据列 */ @Test @DisplayName("列名前缀过滤器: ColumnPrefixFilter") public void columnPrefixFilterTest(){ //基于列限定符(列名)决定某行数据是否被过滤 ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter(Bytes.toBytes("age")); filterList.addFilter(columnPrefixFilter); } ``` #### 4.5 分页过滤器 (PageFilter) 基于行的分页过滤器,设置返回行数。 ```java public PageFilter(final long pageSize) { Preconditions.checkArgument(pageSize >= 0, "must be positive %s", pageSize); this.pageSize = pageSize; } ``` **分页查询工具类** ```java /** * 分页查询 * @param tableName * @param pageNum 要查询的页数 * @param pageSize 每页的条数 * @throws IOException */ public static void pageFilter(String tableName,int pageNum,int pageSize) throws IOException { Table table = connection.getTable(TableName.valueOf(tableName)); Scan scan = new Scan(); if (pageNum == 1) { scan.withStartRow("".getBytes()); //使用分页过滤器,实现数据的分页 PageFilter pageFilter = new PageFilter(pageSize); scan.setFilter(pageFilter); ResultScanner scanner = table.getScanner(scan); print(scanner); } else { String current_page_start_rows = ""; // 记录当前页的开始 rk // 先获取第 N 页的第一条数据的rk int scanDatas = (pageNum - 1) * pageSize + 1; // PageFilter pageFilter = new PageFilter(scanDatas); scan.setFilter(pageFilter); ResultScanner scanner = table.getScanner(scan); for (Result rs : scanner) { current_page_start_rows = Bytes.toString(rs.getRow()); } scan.withStartRow(current_page_start_rows.getBytes()); PageFilter pageFilter2and = new PageFilter(pageSize); scan.setFilter(pageFilter2and); ResultScanner scanner2and = table.getScanner(scan); print(scanner2and); } } ``` **调用方法测试** ```java /** * 分页查询 每页两条数据,返回第二页的数据列表 * @throws IOException */ @Test @DisplayName("分页过滤器: PageFilter") public void pageFilterTest() throws IOException { //创建行键前缀过滤器 HBaseUtils.pageFilter(TABLE_NAME,2,2); } ``` 下面的代码体现了客户端实现分页查询的主要逻辑,这里对其进行一下解释说明: 客户端进行分页查询,需要传递 `startRow`(起始 RowKey),知道起始 `startRow` 后,就可以返回对应的 pageSize 行数据。这里唯一的问题就是,对于第一次查询,显然 `startRow` 就是表格的第一行数据,但是之后第二次、第三次查询我们并不知道 `startRow`,只能知道上一次查询的最后一条数据的 RowKey(简单称之为 `lastRow`)。 我们不能将 `lastRow` 作为新一次查询的 `startRow` 传入,因为 scan 的查询区间是[startRow,endRow) ,即前开后闭区间,这样 `startRow` 在新的查询也会被返回,这条数据就重复了。 同时在不使用第三方数据库存储 RowKey 的情况下,我们是无法通过知道 `lastRow` 的下一个 RowKey 的,因为 RowKey 的设计可能是连续的也有可能是不连续的。 **分页改进版本** 由于 Hbase 的 RowKey 是按照字典序进行排序的。这种情况下,就可以在 `lastRow` 后面加上 `0` ,作为 `startRow` 传入,因为按照字典序的规则,某个值加上 `0` 后的新值,在字典序上一定是这个值的下一个值,对于 HBase 来说下一个 RowKey 在字典序上一定也是等于或者大于这个新值的。 所以最后传入 `lastRow`+`0`,如果等于这个值的 RowKey 存在就从这个值开始 scan,否则从字典序的下一个 RowKey 开始 scan。 > 25 个字母以及数字字符,字典排序如下: > > '0' < '1' < '2' < ... < '9' < 'a' < 'b' < ... < 'z' 分页查询主要实现逻辑: ```java byte[] POSTFIX = new byte[] { 0x00 }; Filter filter = new PageFilter(15); int totalRows = 0; byte[] lastRow = null; while (true) { Scan scan = new Scan(); scan.setFilter(filter); if (lastRow != null) { // 如果不是首行 则 lastRow + 0 byte[] startRow = Bytes.add(lastRow, POSTFIX); System.out.println("start row: " + Bytes.toStringBinary(startRow)); scan.withStartRow(startRow); } ResultScanner scanner = table.getScanner(scan); int localRows = 0; Result result; while ((result = scanner.next()) != null) { System.out.println(localRows++ + ": " + result); totalRows++; lastRow = result.getRow(); } scanner.close(); //最后一页,查询结束 if (localRows == 0) break; } System.out.println("total rows: " + totalRows); ``` > 需要注意的是在多台 Regin Services 上执行分页过滤的时候,由于并行执行的过滤器不能共享它们的状态和边界,所以有可能每个过滤器都会在完成扫描前获取了 PageCount 行的结果,这种情况下会返回比分页条数更多的数据,分页过滤器就有失效的可能。 #### 4.6 时间戳过滤器 (TimestampsFilter) ```java /** * 查询出时间戳为 1691319263000L 的数据行 */ @Test @DisplayName("时间戳过滤器: TimestampsFilter") public void timestampsFilterTest(){ List<Long> list = new ArrayList<>(); list.add(1691319263000L); TimestampsFilter timestampsFilter = new TimestampsFilter(list); filterList.addFilter(timestampsFilter); } ``` #### 4.7 首次行键过滤器 (FirstKeyOnlyFilter) `FirstKeyOnlyFilter` 只扫描每行的第一列,扫描完第一列后就结束对当前行的扫描,并跳转到下一行。相比于全表扫描,其性能更好,通常用于行数统计的场景,因为如果某一行存在,则行中必然至少有一列。 ```java /** * 查询每条数据的第一列 */ @Test @DisplayName("首次行键过滤器: FirstKeyOnlyFilter") public void firstKeyOnlyFilterTest(){ FirstKeyOnlyFilter firstKeyOnlyFilter = new FirstKeyOnlyFilter(); filterList.addFilter(firstKeyOnlyFilter); } ``` ### 五、包装过滤器 包装过滤器就是通过包装其他过滤器以实现某些拓展的功能。 #### 5.1 SkipFilter过滤器 `SkipFilter` 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,则拓展过滤整行数据。 ```java // 查询列值不包含 19 的信息 @Test @DisplayName("SkipFilter过滤器") public void skipFilterTest(){ // 定义 ValueFilter 过滤器 Filter filter1 = new ValueFilter(CompareOperator.NOT_EQUAL, new BinaryComparator(Bytes.toBytes("19"))); // 使用 SkipFilter 进行包装 Filter filter2 = new SkipFilter(filter1); filterList.addFilter(filter2); } ``` #### 5.2 WhileMatchFilter过滤器 `WhileMatchFilter` 包装一个过滤器,当被包装的过滤器遇到一个需要过滤的 KeyValue 实例时,`WhileMatchFilter` 则结束本次扫描,返回已经扫描到的结果。 ```java /** * 查询 rowKey 为 002 以前的所有数据 */ @Test @DisplayName("WhileMatchFilter过滤器") public void whileMatchFilterTest(){ Filter filter1 = new RowFilter(CompareOperator.NOT_EQUAL, new BinaryComparator(Bytes.toBytes("002"))); filterList.addFilter(filter1); // 使用 WhileMatchFilter 进行包装 Filter filter2 = new WhileMatchFilter(filter1); filterList.addFilter(filter2); } ``` ### 六、FilterList 以上都是讲解单个过滤器的作用,当需要多个过滤器共同作用于一次查询的时候,就需要使用 `FilterList`。`FilterList` 支持通过构造器或者 `addFilter` 方法传入多个过滤器。 ```java // 构造器传入 public FilterList(final Operator operator, final List<Filter> filters) public FilterList(final List<Filter> filters) public FilterList(final Filter... filters) // 方法传入 public void addFilter(List<Filter> filters) public void addFilter(Filter filter) ``` 多个过滤器组合的结果由 `operator` 参数定义 ,其可选参数定义在 `Operator` 枚举类中。 只有 `MUST_PASS_ALL` 和 `MUST_PASS_ONE` 两个可选的值: - **MUST_PASS_ALL** :相当于 AND,必须所有的过滤器都通过才认为通过; - **MUST_PASS_ONE** :相当于 OR,只有要一个过滤器通过则认为通过。 **使用示例** ```java List<Filter> filters = new ArrayList<Filter>(); Filter filter1 = new RowFilter(CompareOperator.GREATER_OR_EQUAL, new BinaryComparator(Bytes.toBytes("XXX"))); filters.add(filter1); Filter filter2 = new RowFilter(CompareOperator.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("YYY"))); filters.add(filter2); Filter filter3 = new QualifierFilter(CompareOperator.EQUAL, new RegexStringComparator("ZZZ")); filters.add(filter3); FilterList filterList = new FilterList(filters); Scan scan = new Scan(); scan.setFilter(filterList); ``` **附参考文章链接地址** *https://cloud.tencent.com/developer/article/2058352?from=15425*
标签:
Hbase
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/2855.html
上一篇
Hbase之JavaAPI详细介绍
下一篇
go并发之channel
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
机器学习
Golang基础
Spark RDD
SpringBoot
Kafka
Map
Spark Streaming
Git
DataWarehouse
LeetCode刷题
并发线程
链表
稀疏数组
MyBatis
ClickHouse
人工智能
Beego
Zookeeper
MyBatisX
Http
Tomcat
DataX
散列
pytorch
RSA加解密
JavaWEB项目搭建
Spark SQL
Nacos
JavaScript
MySQL
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭