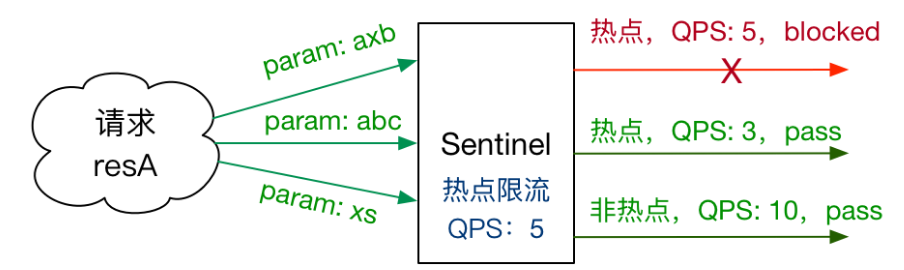
05.Sentinel热点key限流和系统规则
[TOC]一、概述官网地址:热点参数限流何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的Top K数据,并对其访问进行限制。比如:商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制热点参数限制会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限制。热点参数限流可以看作是一种特殊的流量控制,仅对包含热点参数的资源调用生效。Sentinel 利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控。热点参数限流支持集群模式。...
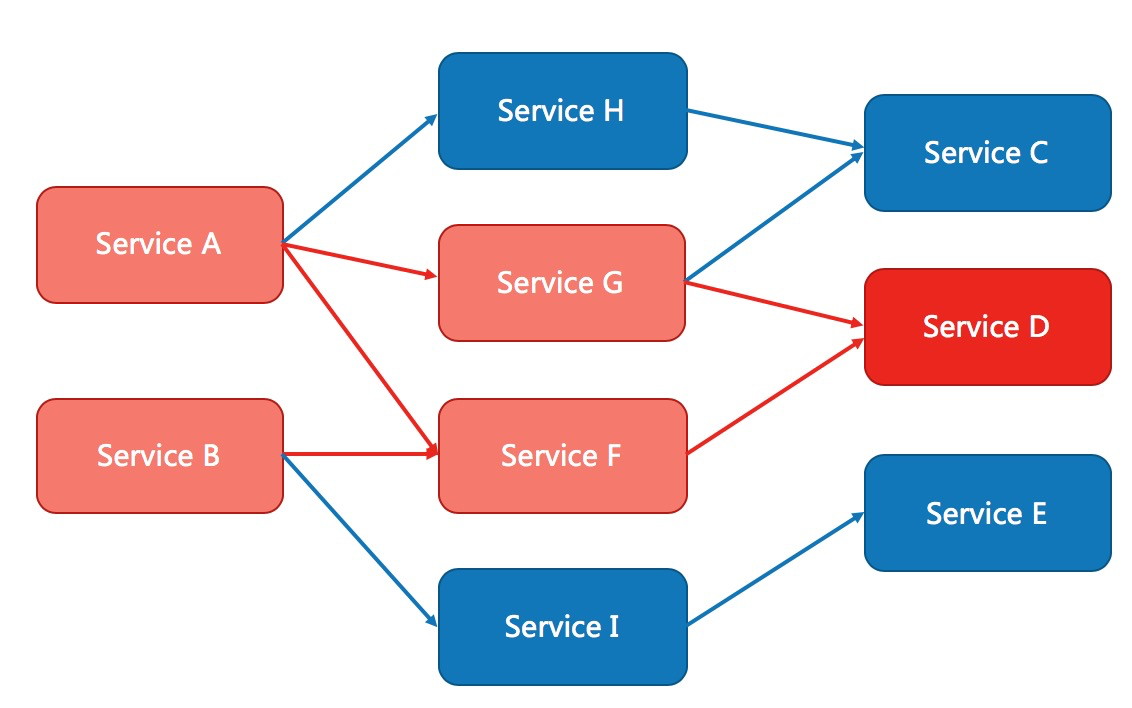
04.Sentinel降级规则
[TOC]前言本文档针对 Sentinel 1.8.0 及以上版本。1.8.0 版本对熔断降级特性进行了全新的改进升级。官网地址:熔断降级一、概述除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。一个服务常常会调用别的模块,可能是另外的一个远程服务、数据库,或者第三方API等。例如,支付的时候,可能需要远程调用银联提供的 API;查询某个商品的价格,可能需要进行数据库查询。然而,这个被依赖服务的稳定性是不能保证的。如果依赖的服务出现了不稳定的情况,请求的响应时间变长,那么调用服务的方法的响应时间也会变长,线程会产生堆积,最终可能耗尽业务自身的线程池,服务...
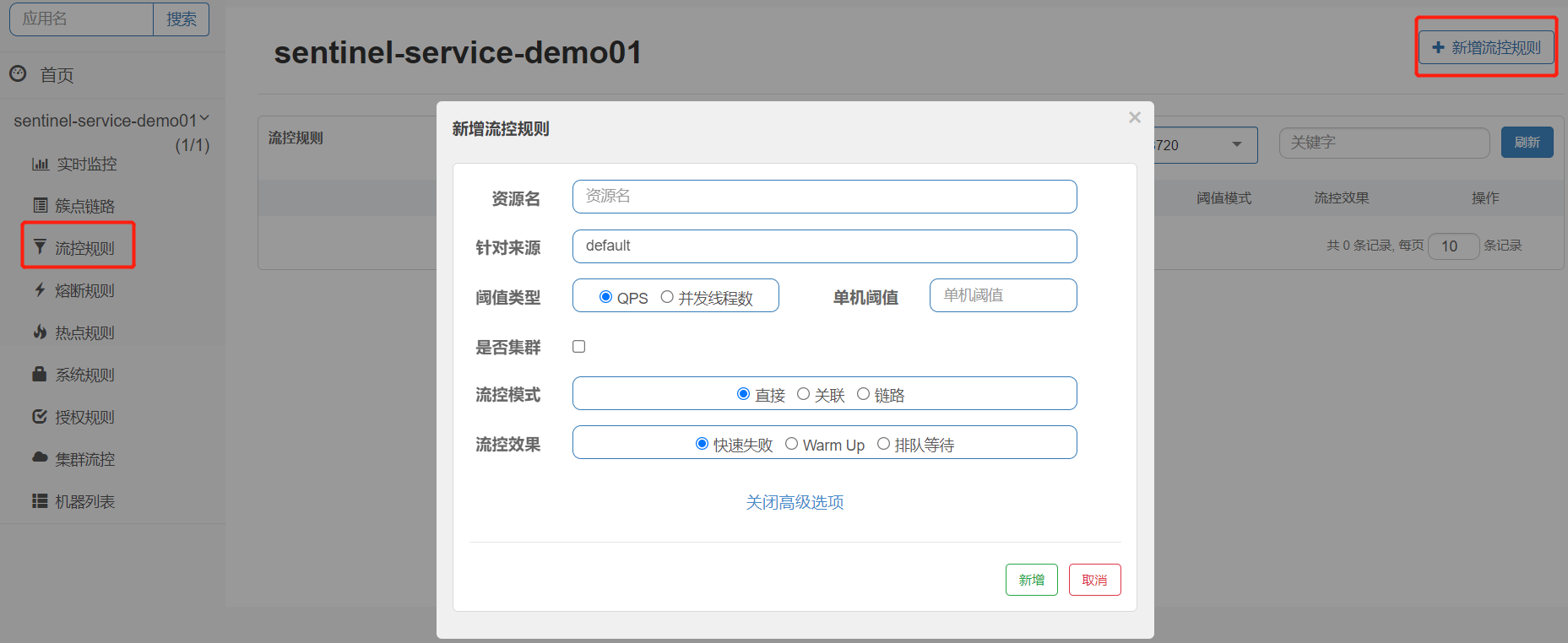
03.Sentinel流控规则
[TOC]一、概述流量控制(flow control),其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。流量限制控制规则,分为:流控模式和流控效果各选项含义:资源名:唯一名称,默认请求路径针对来源:Sentinel可以针对调用者进行限流,填写微服务名,默认default(不区分来源)阈值类型/单机阈值:QPS(每秒钟的请求数量):当调用该API的QPS达到阈值的时候,进行限流线程数:当调用该API的线程数量达到阈值的时候,进行限流是否集群:当前不需要集群流控模式:直接:API达到限流条件时,直接限流...
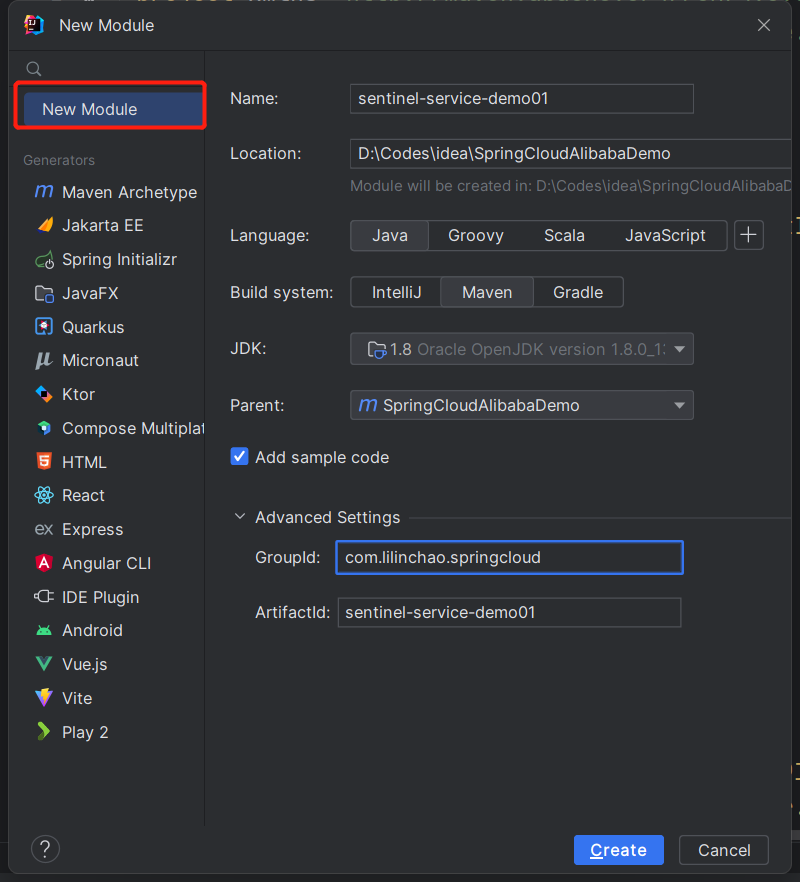
02.Sentinel初始化演示工程
[TOC]前言准备环境:JDK 1.8nacos 2.1.0sentinel-dashboard 1.8.5本次演示都是在本地windows系统上进行,只是入门级。1、启动Nacos服务windows系统Nacos启动命令(nacos服务bin目录下)startup.cmd -m standalone2、新建Module名称:sentinel-service-demo013、引入pom依赖基本上nacos和sentinel都是一起配置<?xml version="1.0" encoding="UTF-8"?> <project x...
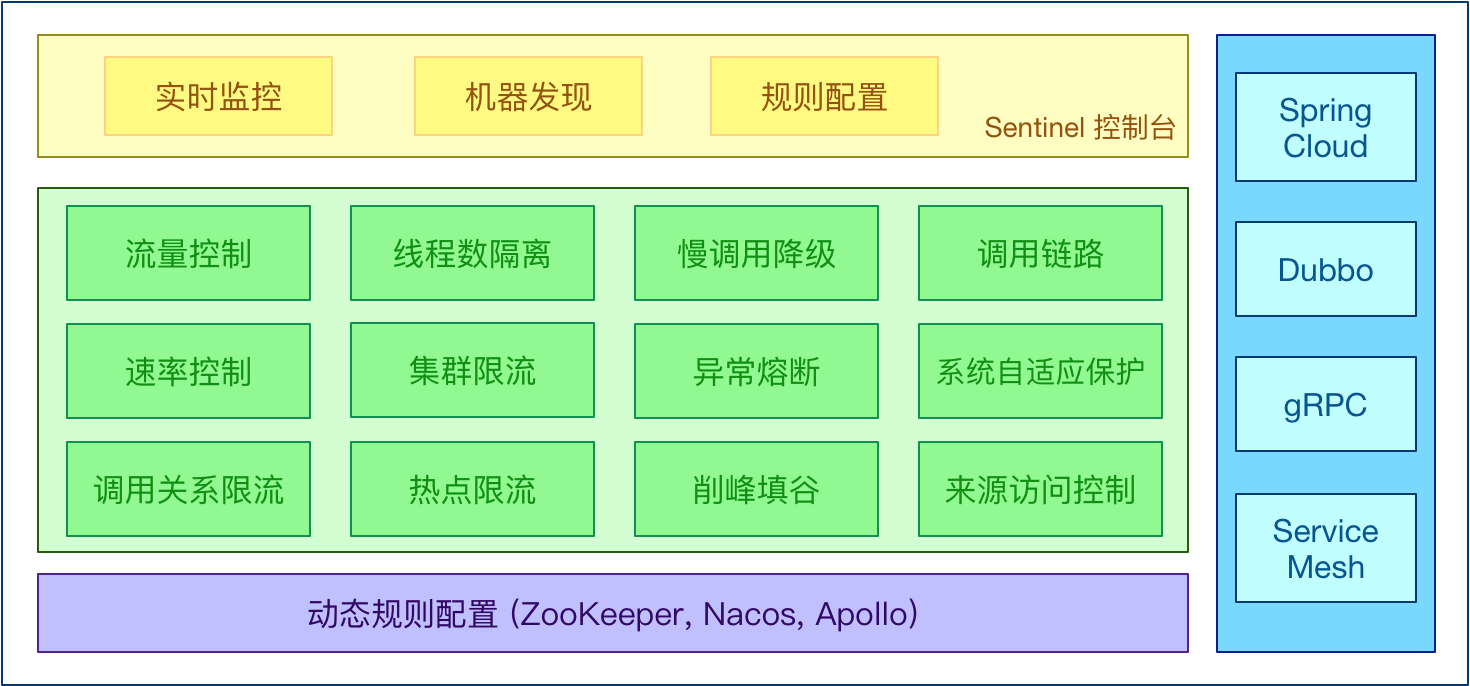
01.Sentinel介绍
[TOC]前言在基于 SpringCloud 构建的微服务体系中,服务间的调用链路会随着系统的演进变得越来越长,这无疑会增加了整个系统的不可靠因素。在并发流量比较高的情况下,由于网络调用之间存在一定的超时时间,链路中的某个服务出现宕机都会大大增加整个调用链路的响应时间,而瞬间的流量洪峰则会导致这条链路上所有服务的可用线程资源被打满,从而造成整体服务的不可用,这也就是我们常说的 “雪崩效应”。而在微服务系统设计的过程中,为了应对这样的糟糕情况,最常用的手段就是进行 ”流量控制“ 以及对网络服务的调用实现“熔断降级”。因此,Sentinel 就因运而生了。一、Sentinel介绍Sentin...
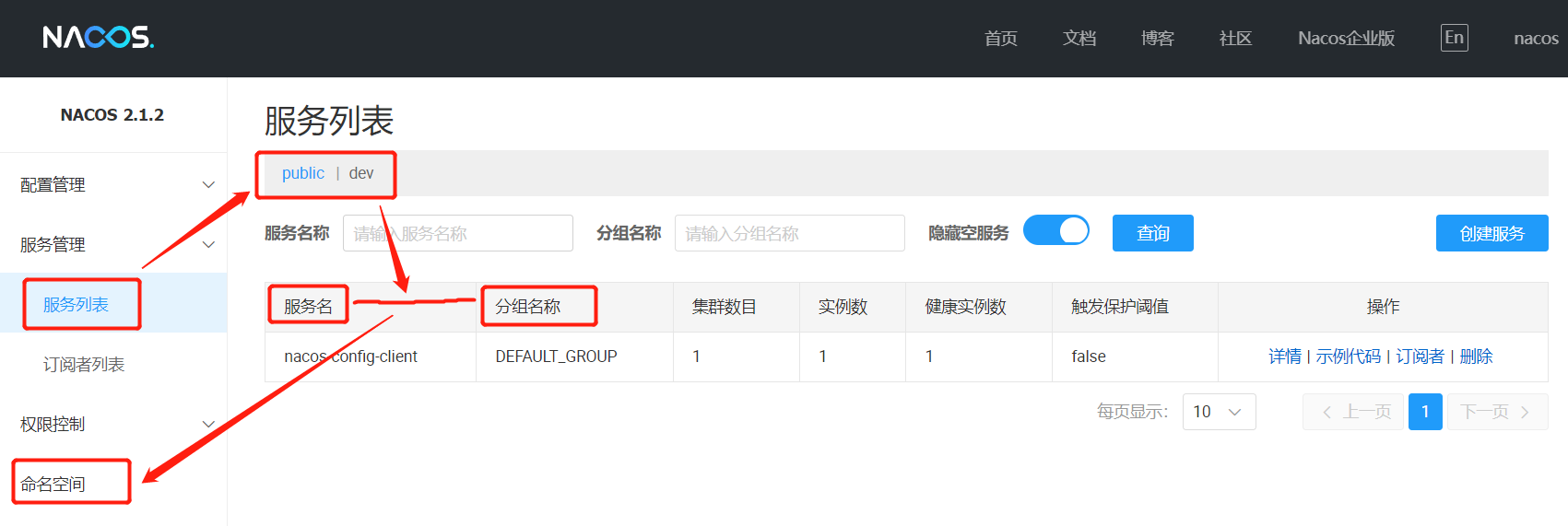
04.Nacos作为服务配置中心分类配置演示
[TOC]一、分类配置1.1 分布式开发中的多环境多项目管理问题问题一实际开发中,通常一个系统会准备dev开发环境、test测试环境、prod生产环境。如何保证指定环境启动时服务能正确读取到Nacos上相应环境的配置文件呢?问题二一个大型分布式微服务系统会有很多微服务子项目,每个微服务项目又都会有相应的开发环境、测试环境、预发环境、正式环境。如何对这些微服务配置进行管理呢?1.2 Nacos图形化管理界面(1)配置管理(2)命名空间2.3 三者关系?对于Nacos配置管理,通过Namespace、group、Data ID能够定位到一个配置集。默认情况Namespace:publicGr...
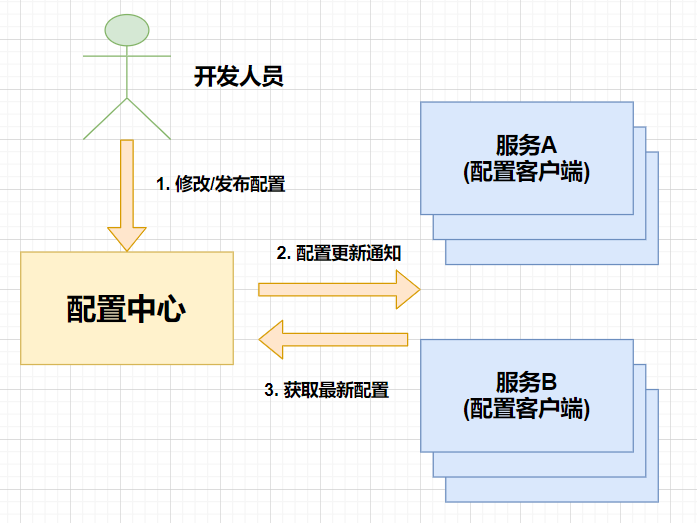
03.Nacos作为服务配置中心基础配置演示
[TOC]一、概述在微服务架构中,配置中心就是统一管理各个微服务配置文件的服务。把传统的单体jar包拆分成多个微服务后,配置文件也要拆分,每个微服务都要有自己的配置文件。为了统一维护,方便管理,所以出现了配置中心的概念,所有的微服务配置文件都在配置中心中管理和读取。二、配置中心的优势微服务架构下关于配置文件的一些问题:配置文件相对分散在一个微服务架构下,配置文件会随着微服务的增多变的越来越多,而且分散在各个微服务中,不好统一配置和管理。配置文件无法区分环境微服务项目可能会有多个环境,例如:测试环境、预发布环境、生产环境。每一个环境所使用的配置理论上都是不同的,一旦需要修改,就需要到各个微...
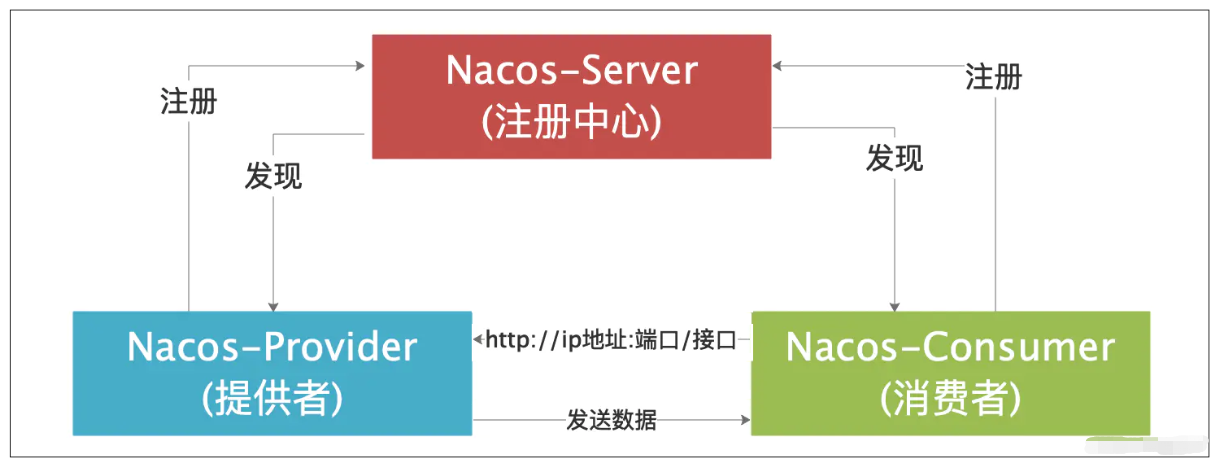
02.Nacos作为服务注册中心演示
[TOC]前言版本关系Spring Cloud Alibaba Version:2.2.9.RELEASESpring Cloud Version:Spring Cloud Hoxton.SR12Spring Boot Version:2.3.12.RELEASE组件版本关系Sentinel Version:1.8.5Nacos Version:2.1.0RocketMQ Version:4.9.4Seata Version:1.5.2这个版本组合是目前找到的最新的版本组合。本人使用的为IDEA 2022.3版本,有的地方和之前版本的有所不同。一、Nacos注册中心示意图注册中心主要有三...
MySQL迁移到达梦数据库
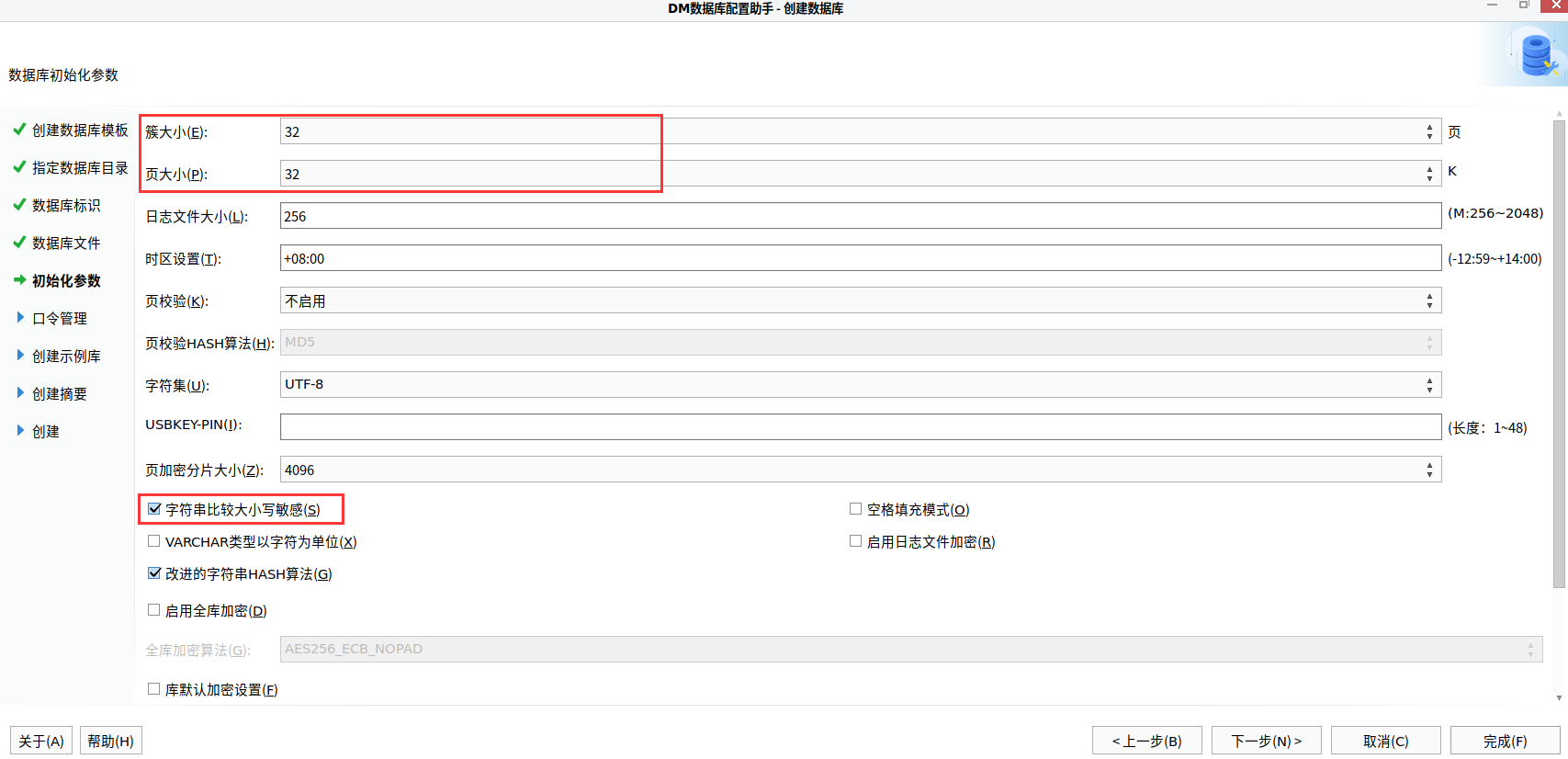
[TOC]前言本次通过SpringBoot+MyBatisPlus架构,将MySQL数据库替换成国产达梦数据库。注意:此次改造的项目同时兼容MySQL和达梦数据库。一、部署注意事项因为MySQL是大小写不敏感的,DM数据库支持大小写敏感和不敏感,默认是大小写敏感。在进行数据库初始化参数设置时,记得将【字符串比较大小写敏感】的勾给去掉。注意:初始化完成之后该参数是不支持再次修改的,切记去掉。二、数据迁移MySQL迁移到达梦数据库达梦官方文档:https://eco.dameng.com/document/dm/zh-cn/start/dm-create-tablespace.html达梦的...
01.Nacos介绍
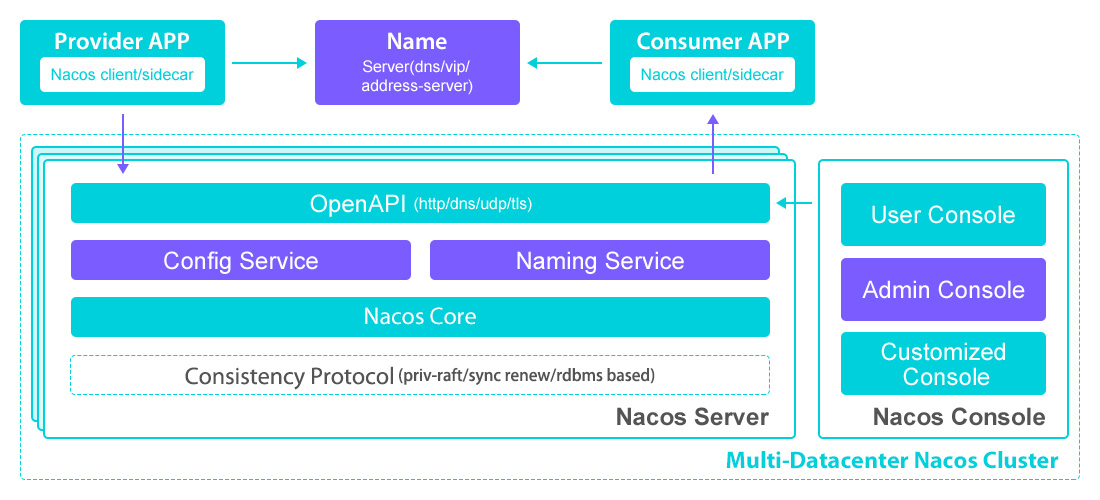
[TOC]一、Nacos概述Nacos是Dynamic Naming and Configuration Service的首字母简称,是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台,是阿里巴巴的新开源项目 。Nacos主要提供三种功能:服务注册与发现、动态配置服务、动态DNS服务。Nacos = Eureka+Config+Bus服务(Service)是 Nacos 世界的一等公民。Nacos 支持几乎所有主流类型的“服务”的发现、配置和管理:Kubernetes ServicegRPC & Dubbo RPC ServiceSpring Cloud RESTful S...