李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
03.Spark RDD简介
Leefs
2021-06-29 AM
1776℃
0条
# 03.Spark RDD简介 ### 一、RDD定义 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的**数据处理模型**。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。 + 弹性 + 存储的弹性:内存与磁盘的自动切换; + 容错的弹性:数据丢失可以自动恢复; + 计算的弹性:计算出错重试机制; + 分片的弹性:可根据需要重新分片 + 分布式:数据存储在大数据集群不同节点上 + 数据集:RDD封装了计算逻辑,并不保存数据 + 数据抽象:RDD是一个抽象类,需要子类具体实现 + 不可变:RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装计算逻辑 + 可分区、并行计算 **RDD体现了装饰者设计模式,将数据处理的逻辑进行了封装。** ### 二、核心属性 RDD核心属性包括:分区器、分区列表、分区计算函数、首选位置 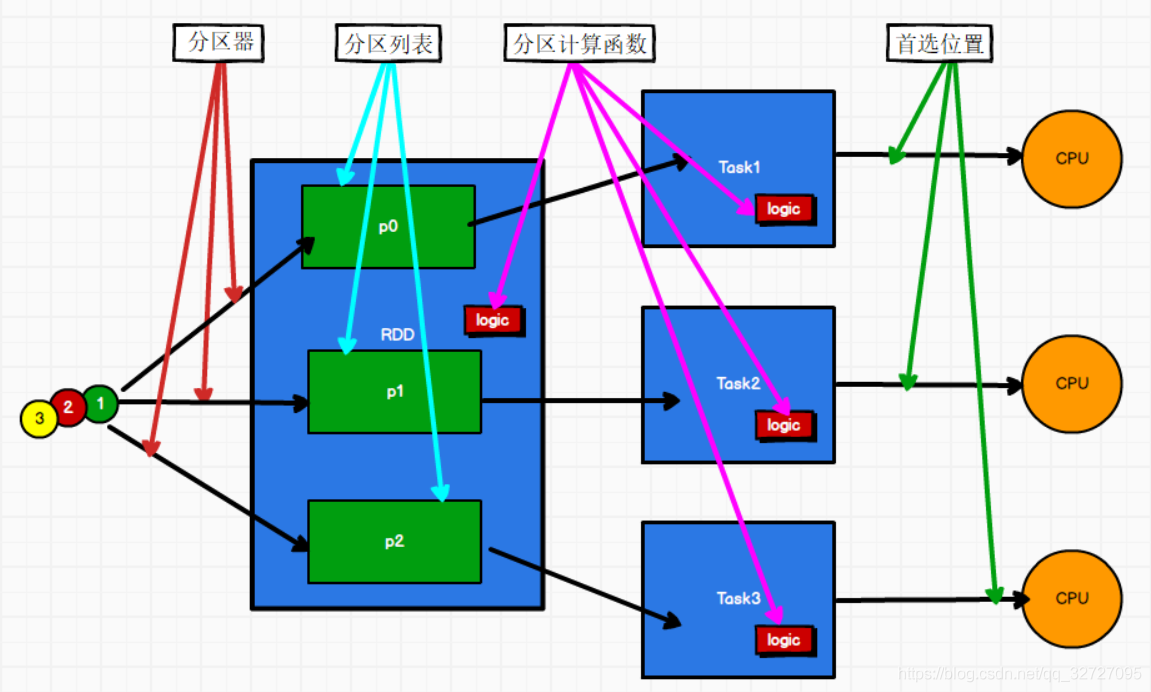 + **分区列表** RDD中的分区,即数据集的基本组成单位,每个分区可以运行在不同节点上; 对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度,是实现分布式计算的重要属性。  + **分区计算函数** Spark在计算时,是使用分区函数对每一个分区进行计算  + **RDD之间的依赖关系** RDD是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个RDD建立依赖关系  + **分区器(可选)** 当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区  + **首选位置(可选)** 计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算  ### 三、执行原理 从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。 执行时,需要将计算资源和计算模型进行协调和整合。 Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的 计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计 算。最后得到计算结果。 RDD 是 Spark 框架中用于数据处理的核心模型,接下来我们看看,在 Yarn 环境中,RDD 的工作原理: (1)启动Yarn集群环境  (2)Spark通过申请资源创建调度节点和计算节点  (3)Spark框架根据需求将计算逻辑根据分区划分成不同的任务  (4)调度节点将任务根据计算节点状态发送到对应的计算节点进行计算  从**以上流程可以看出 RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给 Executor 节点执行计算** **总结** 一个 RDD 可以简单的理解为一个分布式的元素集合,每个 RDD 可以分成多个分区,每个分区可以在集群中不同的节点上进行计算; RDD 表示只读的数据集,对 RDD 进行改动,只能通过 RDD 的转换操作,得到新的 RDD,并不会对原本的 RDD 有任何影响; 在 Spark 中,所有的工作都是以操作 RDD 为主,要么是创建 RDD,要么是转换已经存在 RDD 成为新的 RDD,要么在 RDD 上去执行一些操作来得到一些计算结果。 *附:* [参考文章链接](https://blog.csdn.net/qq_32727095/article/details/108454852)
标签:
Spark
,
Spark Core
,
Spark RDD
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1280.html
上一篇
02. Spark Shuffle过程介绍
下一篇
04.Spark RDD创建简介
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
nginx
MyBatis
Quartz
DataX
Java编程思想
SpringCloudAlibaba
数学
Filter
Kafka
NIO
数据结构和算法
容器深入研究
MyBatisX
Jenkins
RSA加解密
线程池
Spark SQL
Java阻塞队列
DataWarehouse
稀疏数组
Spark RDD
JVM
哈希表
Stream流
LeetCode刷题
Redis
Livy
Scala
MySQL
Http
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭