李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
08.Spark RDD依赖关系
Leefs
2021-06-29 AM
1714℃
0条
# 08.Spark RDD依赖关系 ### 一、RDD血缘关系 #### 1.1 概述 RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。 **由于RDD中是不记录数据的,为了实现分布式计算中的容错 , RDD必须记录RDD之间的血缘关系** #### 1.2 图解血缘关系 **依赖关系** 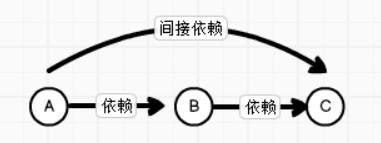 + A和B,B和C之间是直接依赖 + A和C之间是间接依赖 **血缘关系**  相邻的两个RDD的关系称之为依赖关系,新的RDD依赖于旧的RDD,多个连续的RDD的依赖关系,称之为血缘关系 #### 1.3 代码 输出wordCount的血缘关系 + RDD血缘关系的追溯:toDebugString缓存 ```scala object LineageDemo01 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) val RDD1: RDD[String] = sc.textFile("input/word.txt") println(RDD1.toDebugString) println("----------------------") val RDD2: RDD[String] = RDD1.flatMap(_.split(" ")) println(RDD2.toDebugString) println("----------------------") val RDD3: RDD[(String, Int)] = RDD2.map((_,1)) println(RDD3.toDebugString) println("----------------------") val RDD4: RDD[(String, Int)] = RDD3.reduceByKey(_+_) println(RDD4.toDebugString) RDD4.collect() } } ``` **输出结果** ```scala (2) input/word.txt MapPartitionsRDD[1] at textFile at LineageDemo01.scala:17 [] | input/word.txt HadoopRDD[0] at textFile at LineageDemo01.scala:17 [] ---------------------- (2) MapPartitionsRDD[2] at flatMap at LineageDemo01.scala:20 [] | input/word.txt MapPartitionsRDD[1] at textFile at LineageDemo01.scala:17 [] | input/word.txt HadoopRDD[0] at textFile at LineageDemo01.scala:17 [] ---------------------- (2) MapPartitionsRDD[3] at map at LineageDemo01.scala:23 [] | MapPartitionsRDD[2] at flatMap at LineageDemo01.scala:20 [] | input/word.txt MapPartitionsRDD[1] at textFile at LineageDemo01.scala:17 [] | input/word.txt HadoopRDD[0] at textFile at LineageDemo01.scala:17 [] ---------------------- (2) ShuffledRDD[4] at reduceByKey at LineageDemo01.scala:26 [] +-(2) MapPartitionsRDD[3] at map at LineageDemo01.scala:23 [] | MapPartitionsRDD[2] at flatMap at LineageDemo01.scala:20 [] | input/word.txt MapPartitionsRDD[1] at textFile at LineageDemo01.scala:17 [] | input/word.txt HadoopRDD[0] at textFile at LineageDemo01.scala:17 [] ``` **代码分析** 每个RDD会保存血缘关系,但每个RDD不会保存数据,如果在reduceByKey过程中出现错误时,由于RDD2不会保存数据,但可以根据血缘关系将数据源重新读取进行计算  黄色区域就是每个RDD保存的血缘关系,reducrByKey出现错误后,会根据RDD2存储的血缘关系重新计算。 ### 二、依赖关系 这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关 #### 代码 + 查看RDD间依赖类型:dependencies ```scala object LineageDemo01 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) val RDD1: RDD[String] = sc.textFile("input/word.txt") println(RDD1.dependencies) println("----------------------") val RDD2: RDD[String] = RDD1.flatMap(_.split(" ")) println(RDD2.dependencies) println("----------------------") val RDD3: RDD[(String, Int)] = RDD2.map((_,1)) println(RDD3.dependencies) println("----------------------") val RDD4: RDD[(String, Int)] = RDD3.reduceByKey(_+_) println(RDD4.dependencies) RDD4.collect() } } ``` **运行结果** ```scala List(org.apache.spark.OneToOneDependency@50850539) ---------------------- List(org.apache.spark.OneToOneDependency@5fcfde70) ---------------------- List(org.apache.spark.OneToOneDependency@712cfb63) ---------------------- List(org.apache.spark.ShuffleDependency@15c487a8) ``` ### 三、RDD窄依赖 ##### 3.1 概念 父RDD的每个分区只被一个子RDD分区使用一次。 **窄依赖我们形象的比喻为独生子女。** ##### 3.2 分类 窄依赖分为两种: + 一对一的依赖,即`OneToOneDependency` + 范围的依赖RangeDependency,它仅仅被org.apache.spark.rdd.UnionRDD使用。UnionRDD是把多个RDD合成一个RDD,这些RDD是被拼接而成,每个父RDD的Partition的相对顺序不会变,只不过每个父RDD在UnionRDD中的Partition的起始位置不同 ##### 3.3 常见算子 `map`, `filter`, `union`, `join`, `mapPartitions`, `mapValues` ##### 3.4 图解  不存在shuffle操作 ### 四、RDD宽依赖 ##### **4.1 概念** 父RDD的每个分区都有可能被多个子RDD分区使用,子RDD分区通常对应父RDD所有分区 **宽依赖我们形象的比喻为多生。** 会有shuffle的产生,这样就不会产生磁盘io的读写 ##### 4.2 常见算子 `groupByKey`, `join`,`partitionBy`,`reduce`  ##### 窄依赖与窄依赖比较 - 宽依赖往往对应着shuffle操作,需要在运行的过程中将同一个RDD分区传入到不同的RDD分区中,中间可能涉及到多个节点之间数据的传输,而窄依赖的每个父RDD分区通常只会传入到另一个子RDD分区,通常在一个节点内完成。 - 当RDD分区丢失时,对于窄依赖来说,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重新计算与子RDD分区对应的父RDD分区就行。这个计算对数据的利用是100%的 - 当RDD分区丢失时,对于宽依赖来说,重算的父RDD分区只有一部分数据是对应丢失的子RDD分区的,另一部分就造成了多余的计算。宽依赖中的子RDD分区通常来自多个父RDD分区,极端情况下,所有父RDD都有可能重新计算。 #### wordCount演示 ##### 代码 ```scala object LineageDemo02 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) val path = "input/word2.txt" val lines = sc.textFile(path, 3) //查看每个分区的数据 // lines.mapPartitionsWithIndex((n, partition) => { // partition.map(x => (s"分区编号${n}", s"分区数据${x}")) // }).foreach(println) val words = lines.flatMap(_.split(",")) val wordPair = words.map(x => (x, 1)) val result = wordPair.reduceByKey(_ + _) result.collect().foreach(println) } } ``` ##### 图解  ### 五、阶段划分 DAG(Directed Acyclic Graph)叫做有**向无环图**,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage。 对于窄依赖,partition的转换处理在Stage中完成计算。 对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。  *附:* [参考文章链接1](https://blog.csdn.net/yz972641975/article/details/103573496)
标签:
Spark
,
Spark Core
,
Spark RDD
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1312.html
上一篇
07.Spark RDD序列化
下一篇
09.【转载】Spark RDD任务划分
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Spark
Quartz
DataX
JVM
Thymeleaf
Eclipse
Hive
DataWarehouse
前端
机器学习
Spring
Ubuntu
ClickHouse
高并发
MySQL
Linux
HDFS
SpringBoot
字符串
Filter
Netty
Zookeeper
RSA加解密
稀疏数组
Jquery
国产数据库改造
Golang
Golang基础
gorm
Java
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭