李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
09.【转载】Spark RDD任务划分
Leefs
2021-06-29 AM
1643℃
0条
# 09.【转载】Spark RDD任务划分 ### 一、DAG有向无环图生成 ##### 1.1 DAG是什么 **DAG(Directed Acyclic Graph)** 叫做有向无环图(有方向,无闭环,代表着数据的流向),原始的RDD通过一系列的转换就形成了DAG。 下图是基于单词统计逻辑得到的DAG有向无环图 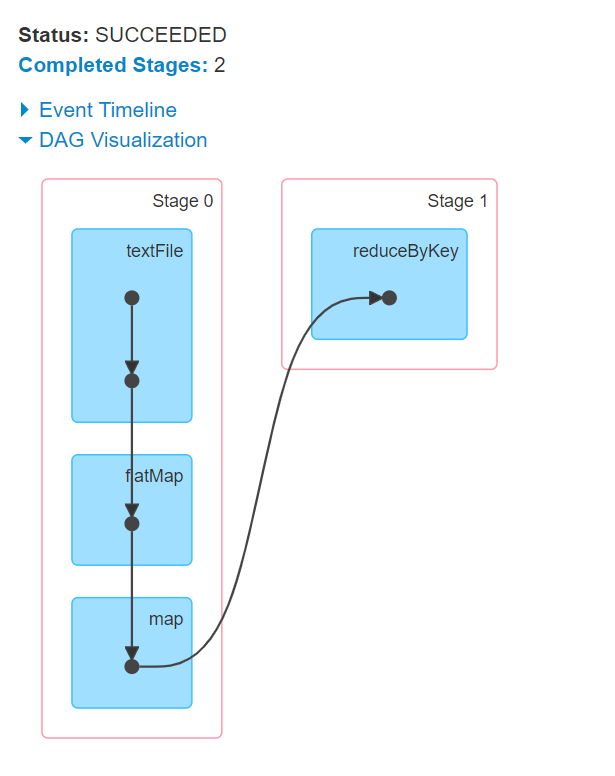 ### 二、DAG划分stage ##### 2.1 stage是什么 **一个Job会被拆分为多组Task,每组任务被称为一个stage** stage表示不同的调度阶段,一个spark job会对应产生很多个stage stage类型一共有2种: 1. ShuffleMapStage + 最后一个shuffle之前的所有变换的Stage叫ShuffleMapStage + 它对应的task是shuffleMapTask 2. ResultStage + 最后一个shuffle之后操作的Stage叫ResultStage,它是最后一个Stage + 它对应的task是ResultTask ##### 2.2 为什么要划分stage 根据RDD之间依赖关系的不同将DAG划分成不同的Stage(调度阶段) + 对于窄依赖,partition的转换处理在一个Stage中完成计算 + 对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,由于划分完stage之后,在同一个stage中只有窄依赖,没有宽依赖,可以实现流水线计算, stage中的每一个分区对应一个task,在同一个stage中就有很多可以并行运行的task。 **2.3 如何划分stage** **划分stage的依据就是宽依赖** 划分流程: (1) 首先根据rdd的算子操作顺序生成DAG有向无环图,接下里从最后一个rdd往前推,创建一个新的stage,把该rdd加入到该stage中,它是最后一个stage。 (2) 在往前推的过程中运行遇到了窄依赖就把该rdd加入到本stage中,如果遇到了宽依赖,就从宽依赖切开,那么最后一个stage也就结束了。 (3) 重新创建一个新的stage,按照第二个步骤继续往前推,一直到最开始的rdd,整个划分stage也就结束了  ##### 2.4 stage与stage之间的关系 划分完stage之后,每一个stage中有很多可以并行运行的task,后期把每一个stage中的task封装在一个taskSet集合中,最后把一个一个的taskSet集合提交到worker节点上的executor进程中运行。 rdd与rdd之间存在依赖关系,**stage与stage之前也存在依赖关系,前面stage中的task先运行,运行完成了再运行后面stage中的task**,也就是说后面stage中的task输入数据是前面stage中task的输出结果数据。  ### 三、Spark的任务调度  ``` (1) Driver端运行客户端的main方法,构建SparkContext对象,在SparkContext对象内部依次构建DAGScheduler和TaskScheduler (2) 按照rdd的一系列操作顺序,来生成DAG有向无环图 (3) DAGScheduler拿到DAG有向无环图之后,按照宽依赖进行stage的划分。每一个stage内部有很多可以并行运行的task,最后封装在一个一个的taskSet集合中,然后把taskSet发送给TaskScheduler (4) TaskScheduler得到taskSet集合之后,依次遍历取出每一个task提交到worker节点上的executor进程中运行。 (5) 所有task运行完成,整个任务也就结束了 ``` ### 四、spark的运行架构  ``` (1) Driver端向资源管理器Master发送注册和申请计算资源的请求 (2) Master通知对应的worker节点启动executor进程(计算资源) (3) executor进程向Driver端发送注册并且申请task请求 (4) Driver端运行客户端的main方法,构建SparkContext对象,在SparkContext对象内部依次构建DAGScheduler和TaskScheduler (5) 按照客户端代码洪rdd的一系列操作顺序,生成DAG有向无环图 (6) DAGScheduler拿到DAG有向无环图之后,按照宽依赖进行stage的划分。每一个stage内部有很多可以并行运行的task,最后封装在一个一个的taskSet集合中,然后把taskSet发送给TaskScheduler (7) TaskScheduler得到taskSet集合之后,依次遍历取出每一个task提交到worker节点上的executor进程中运行 (8) 所有task运行完成,Driver端向Master发送注销请求,Master通知Worker关闭executor进程,Worker上的计算资源得到释放,最后整个任务也就结束了。 ``` 附: 原文链接地址:https://www.cnblogs.com/jimmy888/p/13551719.html
标签:
Spark
,
Spark Core
,
Spark RDD
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1318.html
上一篇
08.Spark RDD依赖关系
下一篇
10.【转载】Spark RDD持久化
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
MyBatis
Java工具类
Linux
序列化和反序列化
并发编程
FileBeat
JVM
Livy
Quartz
高并发
Zookeeper
NIO
Spark Streaming
Spark
Hbase
栈
递归
JavaScript
Stream流
Elastisearch
队列
Java
SpringCloudAlibaba
ajax
链表
人工智能
Spark RDD
Flume
DataWarehouse
BurpSuite
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭