什么是OLAP
[TOC]一、介绍 OLAP 名为联机分析处理,又可以称之为多维分析处理,是由关系型数据之父于 1993 年提出的概念。顾名思义,它指的是通过多种不同的维度审视数据,进行深层次分析。维度可以看成是观察数据的一种视角,例如人类能看到的世界是三维的,它包含长、宽、高三个维度。直接一点理解,维度就好比是一张数据表的字段,而多维分析则是基于这些字段进行聚合查询。那么多维分析通常都包含...
21.Hive案例实操
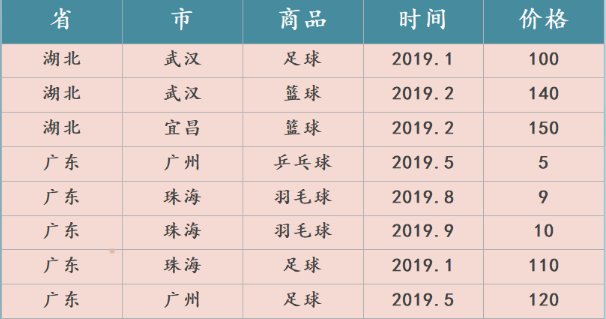
[TOC]一、需求统计某视频网站的常规指标,各种 TopN 指标:统计视频观看数 Top10统计视频类别热度 Top10统计出视频观看数最高的 20 个视频的所属类别以及类别包含 Top20 视频的个数统计视频观看数 Top50 所关联视频的所属类别排序统计每个类别中的视频热度 Top10,以 Music 为例统计每个类别视频观看数 Top10统计上传视频最多的用户 Top10 以及他们上传...

20.Hive自定义UDTF函数
[TOC]前言之前已经介绍过自定义UDF函数,本篇将继续介绍自定义UDTF函数。一、简介UDTF:即用户定义表生成函数(user-defined table-generating function),作用于单行数据,并且产生多个数据行。UDTF函数的输入与输出值是1:n的关系。UDTF(一进多出)二、自定义UDTF函数2.1 实现步骤(1)引入依赖包;(2)创建自定义类,继承抽象类Gener...
19.Hive自定义UDF函数
[TOC]前言本篇使用的版本是Hive 3.1.2。一、UDF函数简介Hive中的用户自定义函数(即User Defined Function,简称UDF),是用户对一些列Hive操作进行封装以实现特定的功能的函数。比如:在Hive的UDF中,可以直接使用select语句,对查询结果按照一定的格式输出。UDF操作作用于单个数据行,并且产生一个数据行作为输出。(一进一出)UDF函数可以直接在方...
18.Hive正则表达式详解
[TOC]前言当真正使用Hive处理数据的时候,往往需要使用正则表达式来对数据做一些过滤操作,本篇将通过一些示例介绍一下Hive中的正则表达式的使用。一、正则匹配LIKE语法A LIKE B操作类型: strings返回类型: boolean或null描述如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合表达式B的正则语法,则为TRUE,否则为FALSE;B中字符"_"表示...
17.Hive行转列和列转行
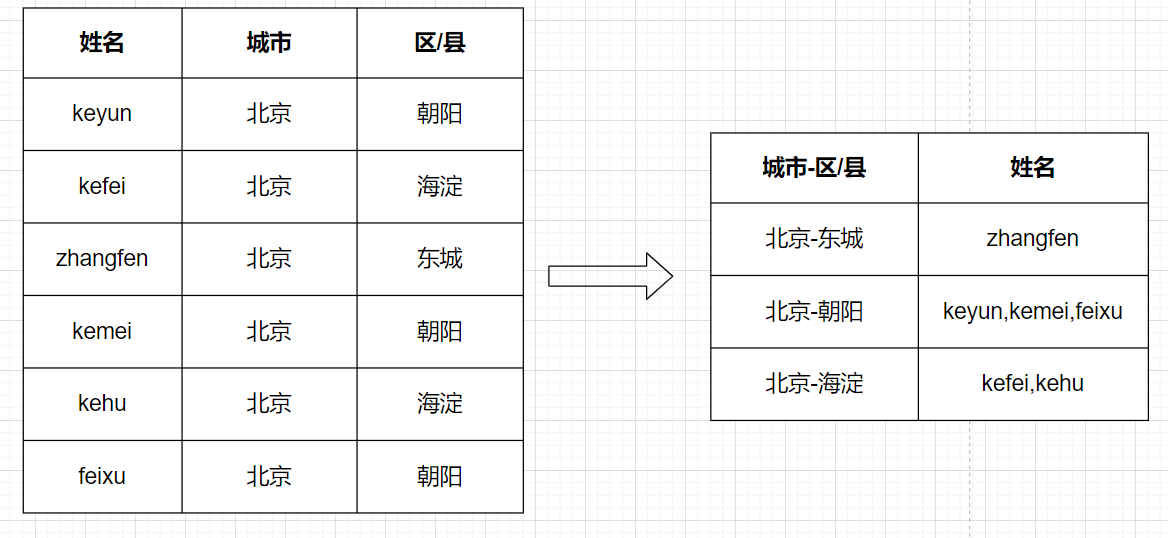
[TOC]一、行转列1.1 相关函数concatconcat(string A, string B…):用于拼接字符串,返回输入字符串连接后的结果,支持任意个输入字符串concat_wsconcat_ws(string SEP, string A, string B…):与concat类似,返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符;concat_ws(string SEP,...
16.Hive常用内置函数示例
[TOC]一、字符函数示例1.1字符串反转函数语法:reverse(string A)说明:返回字符串A的反转结果0: jdbc:hive2://hadoop001:10000> select reverse("abcdef"); +---------+ | _c0 | +---------+ | fedcba | +---------+1.2 字符串连接...
15.Hive常用内置函数总结
[TOC]一、查询系统内置函数1.1 查看系统自带的函数show functions;1.2 显示自带的函数的用法语法desc function 【函数名称】;-- 查询upper函数用法 0: jdbc:hive2://hadoop001:10000> desc function upper; -- 运行结果 +-----------------------------------...
14.Hive分桶表详细介绍
[TOC]一、概述1.1 简介 分区提供了一个隔离数据和优化查询的可行方案,但是并非所有的数据集都可以形成合理的分区,分区的数量也不是越多越好,过多的分区条件可能会导致很多分区上没有数据。 同时Hive会限制动态分区可以创建的最大分区数,用来避免过多分区文件对文件系统产生负担。 鉴于以上原因,Hive还提供了一种更加细粒度的数据拆分方案:分桶表...