李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
03.IDEA创建SparkSQL环境对象
Leefs
2021-07-16 PM
1502℃
0条
# 03.IDEA创建SparkSQL环境对象 ### 一、引入坐标依赖 ```xml <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.0.0</version> </dependency> ``` 在IDEA的pom.xml文件中引入以上坐标依赖,版本和SparkCore类似。 本次使用的Spark版本是3.0.0 Scala版本是2.12 ### 二、创建SparkSQL程序 ##### 2.1 准备工作 test.json文件数据 ```json {"username": "lisi","age": 18} {"username": "wangwu","age": 20} {"username": "zhangsan","age": 22} ``` 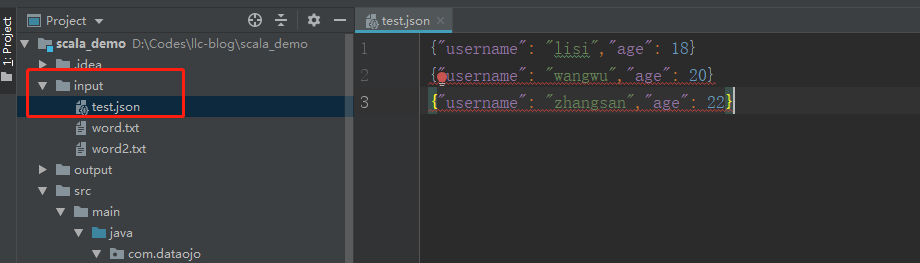 **2.2 搭建SparkSQL运行环境** ```scala import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession /** * @author lilinchao * @date 2021/7/5 * @description 1.0 **/ object Spark01_SparkSQL_Basic { def main(args: Array[String]): Unit = { //TODO 创建SparkSQL的运行环境 val SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL") //创建SparkSession对象 val spark = SparkSession.builder().config(SparkConf).getOrCreate() //TODO 执行逻辑操作 //TODO 关闭环境 spark.stop() } } ``` ### 三、逻辑操作 ##### 3.1 DataFrame展示 ```scala //DataFrame展示 val df:DataFrame = spark.read.json("input/test.json") df.show() ``` **运行结果**  ##### 3.2 DataFrame通过SQL方式 ```scala //创建一个临时视图 df.createOrReplaceTempView("user") //通过SQL操作 //spark.sql("select * from user").show spark.sql("select age,username from user").show //查询平均值 spark.sql("select avg(age) from user").show ``` **运行结果**  ##### 3.3 DataFrame通过DSL方式 ```scala //在使用DataFrame时,如果涉及到转换操作,需要引入转换规则 // spark不是包名,是上下文环境对象名 import spark.implicits._ df.select("age","username").show df.select($"age"+1).show //df.select('age+1).show ``` **运行结果**  ##### 3.4 DataSet ```sql val seq = Seq(1,2,3,4) val ds:Dataset[Int] = seq.toDS() ds.show() ``` **运行结果**  DataFrame其实是特定类型的DataSet DataFrame源码 ```scala type DataFrame = org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] ``` **完整代码** ```scala import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * @author lilinchao * @date 2021/7/5 * @description 1.0 **/ object Spark01_SparkSQL_Basic { def main(args: Array[String]): Unit = { //TODO 创建SparkSQL的运行环境 val SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL") //创建SparkSession对象 val spark = SparkSession.builder().config(SparkConf).getOrCreate() //TODO 执行逻辑操作 //DataFrame展示 val df:DataFrame = spark.read.json("input/test.json") // df.show() //DataFrame => SQL //创建一个临时视图 // df.createOrReplaceTempView("user") // //通过SQL操作 // spark.sql("select * from user").show // spark.sql("select age,username from user").show // //查询平均值 // spark.sql("select avg(age) from user").show //DataFrame => DSL //在使用DataFrame时,如果涉及到转换操作,需要引入转换规则 // spark不是包名,是上下文环境对象名 import spark.implicits._ // df.select("age","username").show // df.select($"age"+1).show // df.select('age+1).show //DataFrame其实是特定类型的DataSet val seq = Seq(1,2,3,4) val ds:Dataset[Int] = seq.toDS() ds.show() //TODO 关闭环境 spark.stop() } } ``` ### 四、转换 完整代码 ```scala import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} /** * @author lilinchao * @date 2021/7/5 * @description 1.0 **/ object Spark01_SparkSQL_Basic2 { def main(args: Array[String]): Unit = { //TODO 创建SparkSQL的运行环境 val SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL") //创建SparkSession对象 val spark = SparkSession.builder().config(SparkConf).getOrCreate() import spark.implicits._ //RDD 和 DataFrame互转 val rdd = spark.sparkContext.makeRDD(List((1,"zhangsan",30),(2,"lisi",40))) val df:DataFrame = rdd.toDF("id","name","age") val rowRDD:RDD[Row] = df.rdd //DataFrame 和 DataSet互转 val ds:Dataset[User] = df.as[User] val df1:DataFrame = ds.toDF() //RDD 和 DataSet互转 val ds1:Dataset[User] = rdd.map{ case(id,name,age) =>{ User(id,name,age) } }.toDS() val userRDD:RDD[User] = ds1.rdd //TODO 关闭环境 spark.stop() } case class User(id:Int,name:String,age:Int) } ```
标签:
Spark
,
Spark SQL
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1334.html
上一篇
02.SparkSQL数据模型DataFrame和DataSet介绍
下一篇
04.DataFrame常用API
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
散列
Java阻塞队列
序列化和反序列化
Elastisearch
gorm
FastDFS
队列
Stream流
Spark SQL
Scala
查找
Docker
SQL练习题
JavaWEB项目搭建
工具
Kafka
Golang基础
Livy
HDFS
DataWarehouse
人工智能
JavaSE
链表
Ubuntu
正则表达式
Spring
RSA加解密
Filter
算法
Spark Streaming
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭