IDEA编译运行Spark源码
前言环境准备IDEA 2022.3Scala 2.12.15maven 3.6.3JDK 1.8一、下载Spark源码1.1 官网地址Spark官网地址:https://spark.apache.org/downloads.html本次下载的源码版本为:Spark 3.2.31.2 下载之前版本Spark1.3 选择Spark 3.2.3版本下载地址:https://archive.apac...

【转载】scala spark创建DataFrame的多种方式
[TOC]一、通过RDD[Row]和StructType创建import org.apache.spark.rdd.RDD import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{DataFrame, Row, Spark...
SparkSQL导入导出Excel文件
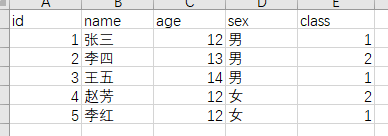
[TOC]前言本篇使用的环境是:spark版本:3.0.0scala版本:2.12一、导入依赖<!--加载Excel--> <dependency> <groupId>com.crealytics</groupId> <artifactId>spark-excel_2.12</artifactId> ...
SparkSQL案例实操(五)
[TOC]一、需求统计用户上网流量统计用户上网流量,如果两次上网的时间小于10min,就可以rollup(合并)到一起二、数据准备merge.dat文件id start_time end_time flow 1 14:20:30 14:46:30 20 1 14:47:20 15:20:30 30 1 15:37:23 16:05:26 40 1 16:06:27 17:20:49 50 1...
SparkSQL案例实操(四)
[TOC]一、需求统计有过连续3天以上销售的店铺,并计算销售额结果示例+-----+----------+----------+-----+-----------+ | sid|begin_date| end_date|times|total_sales| +-----+----------+----------+-----+-----------+ |shop1|2019-02-10|...
SparkSQL案例实操(三)
[TOC]一、需求统计连续登录三天及以上的用户这个问题可以扩展到很多相似的问题:连续几个月充值会员、连续天数有商品卖出、连续打滴滴、连续逾期。示例uidtimesstart_dateend_dateguid0142018-03-042018-03-07guid0232018-03-012018-03-03二、数据准备v_user_login.csvuid,datatime guid01,20...
SparkSQL案例实操(二)
[TOC]一、需求1.1 需求简介各区域热门商品 Top3这里的热门商品是从点击量的维度来看的,计算各个区域前三大热门商品备注上每个商品在主要城市中的分布比例超过两个城市用其他显示示例地区商品名称点击次数城市备注华北商品 A100000北京 21.2%,天津 13.2%,其他 65.6%华北商品 P80200北京 63.0%,太原 10%,其他 27.0%华北商品 M40000北京 63.0...
SparkSQL案例实操(一)
[TOC]一、需求统计每个用户的累计访问次数要求使用SQL统计出每个用户的累积访问次数,如下表所示:用户id月份小计累积u012021-011111u012021-021223u022021-011212u032021-0188u042021-0133说明:累计访问次数按照月份进行排序,根据每个用户逐月进行累加二、数据准备user_access_count.csv文件userid,visit...
SparkCore之广播变量
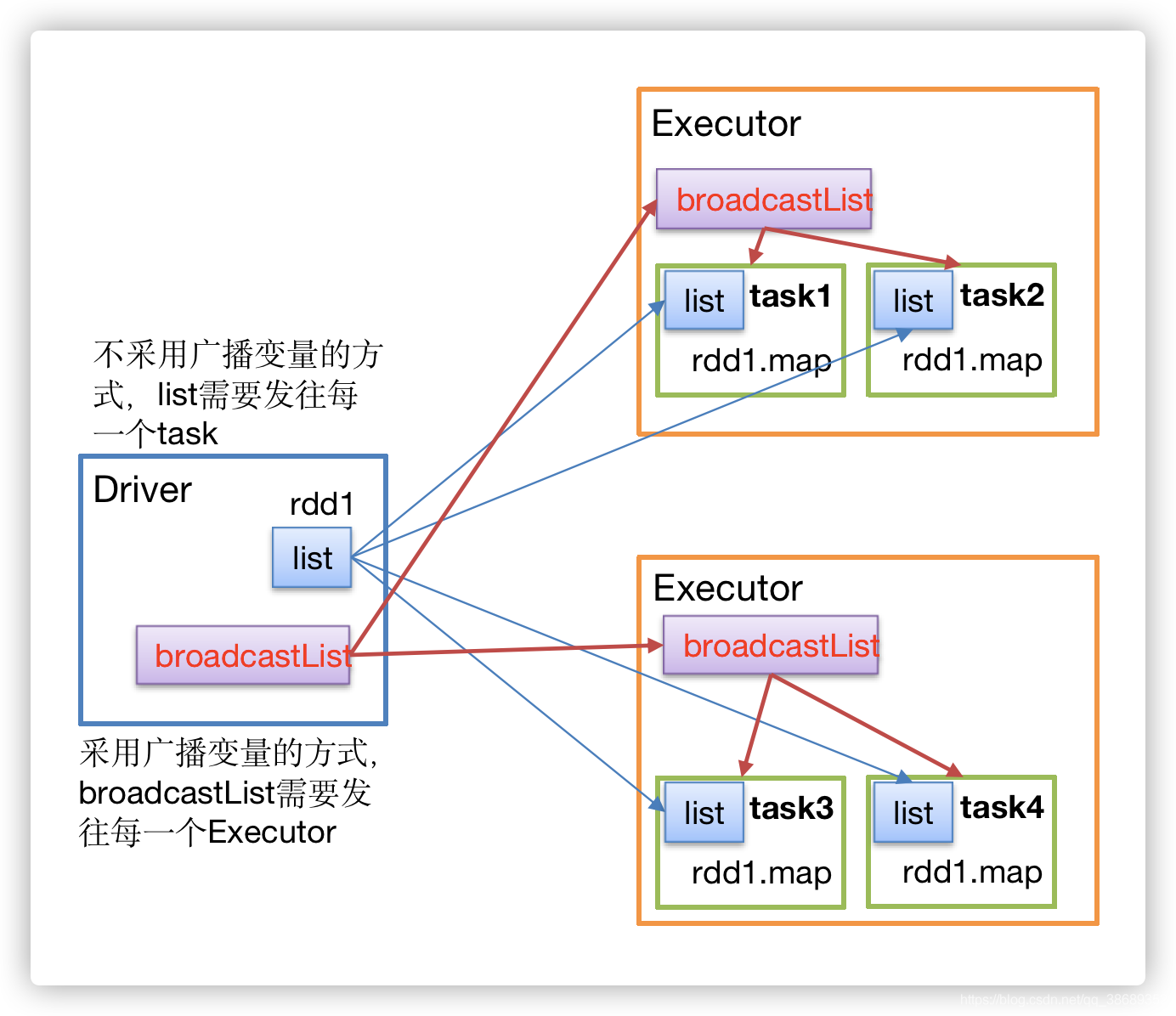
[TOC]一、定义广播变量:分布式共享只读变量二、作用在多个并行操作中(Executor)使用同一个变量,Spark默认会为每个任务(Task)分别发送,这样如果共享比较大的对象,会占用很大工作节点的内存。广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很...