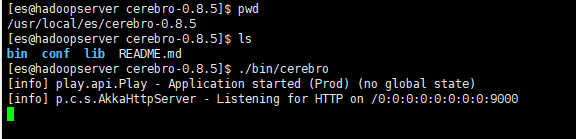
Cerebro安装教程
[TOC]前言准备环境:JDK1.8CentOS 7.X一、介绍Cerebro是以前的 Elasticsearch插件Elasticsearch Kopf 的演变,这不适用于 Elasticsearch 版本5.x或更高版本,这是由于删除了site plugins。Cerebro 是查看分片分配和最有用的界面之一通过图形界面执行常见的索引操作。 完全开放源,并且它允许您添加用户,密码或 LDAP 身份验证问网络界面。Cerebro 是对先前插件的部分重写,并且可以作为自运行工具使用应用程序服务器,基于 Scala 的Play 框架。Cerebro 是一种现代反应性应用程序; 它使用 Sc...
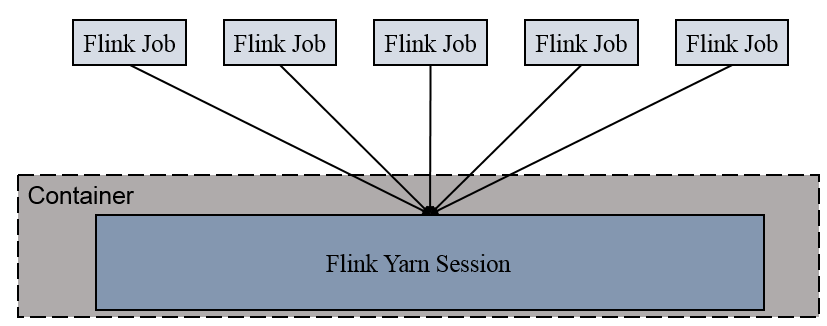
06.Flink Yarn模式介绍
[TOC]前言Flink的Standalone和on Yarn模式都属于集群运行模式,但是有很大的不同,在实际环境中,使用Flink on Yarn模式者居多。Standalone和on Yarn模式的最大不同点是管理资源的不同:Standalone模式通过Flink自身来管理集群资源on Yarn模式通过Hadoop Yarn来对集群资源进行管理一、概述 以Yarn模式部署Flink任务时,要求Flink是有Hadoop支持的版本,Hadoop环境需要保证版本在 2.2以上,并且集群中安装有HDFS服务。Flink on YarnFlink提供了两种在yarn上运行的模...
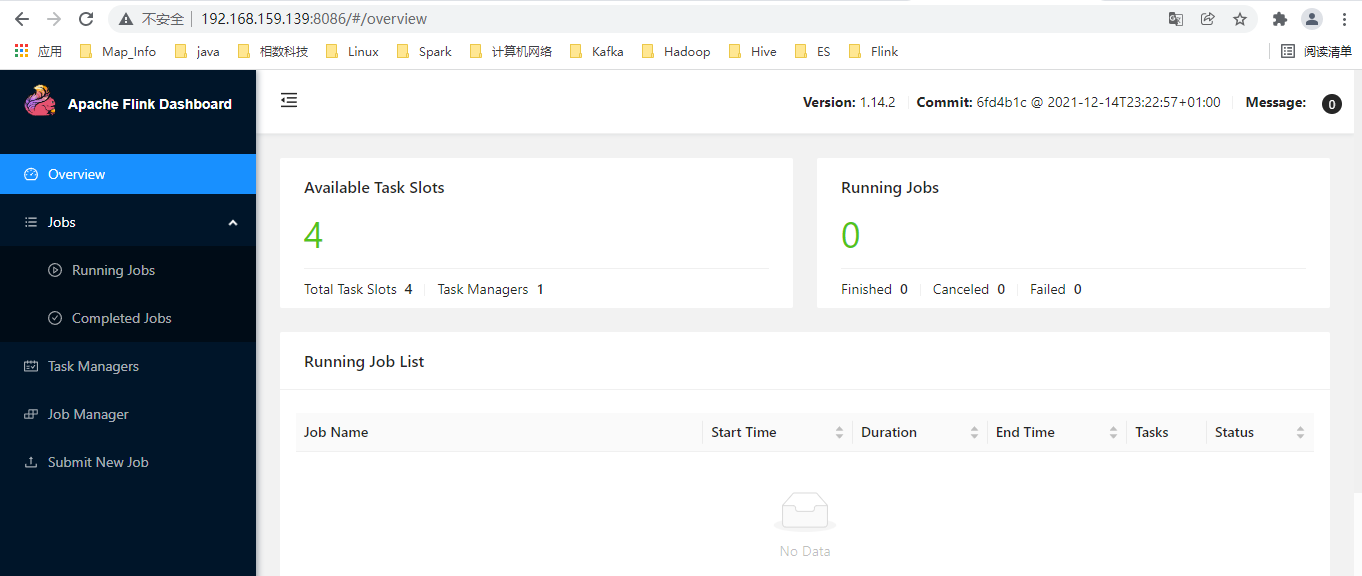
05.Flink Standalone模式单机版安装
[TOC]一、概述1.1 介绍flink的 standalone(standalone deploy mode)部署模式,指的是flink直接在操作系统上启动flink相关服务如client, jobmanager, taskmanager,而不依赖其它资源管理框架如yarn, mesos, k8s进行资源管理。此时是由flink直接来进行集群资源管理的,比如监控和重启失败的服务进程,分配和释放资源等等。1.2 Standalone单机版说明JobManager 和 TaskMananger 全部在一个 node 上运行仅适用于本地测试,不适用于生产环境仅支持 Session Mode ...
04.Flink本地模式部署
[TOC]前言Flink提供了多种部署方式,常用方式主要有三种:local、standalone、yarn。local就是单机模式,一般来说用于本地开发测试;Standalone跟yarn模式都可以支撑集群部署、实现HA,但是两者在任务分配机制、内存管理等内容上有比较大的差异。一般在处理计算数据量级非常大的生产环境,使用flink on yarn的模式更多一些。一、Local模式介绍在local模式下,不需要启动任何的进程,仅仅是使用本地线程来模拟flink的进程,适用于测试开发调试等,这种模式下,不用更改任何配置,只需要保证jdk8安装正常即可。二、安装过程介绍2.1 环境准备Cent...
03.Flink入门案例
[TOC]前言本篇将通过两个案例来入门Flink流式处理和批处理编程。准备环境:Scala 2.12版本创建一个Maven工程项目一、准备1.1 引入依赖pom.xml<dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_2.12</artifactId> <version>1.10.1</version> &...
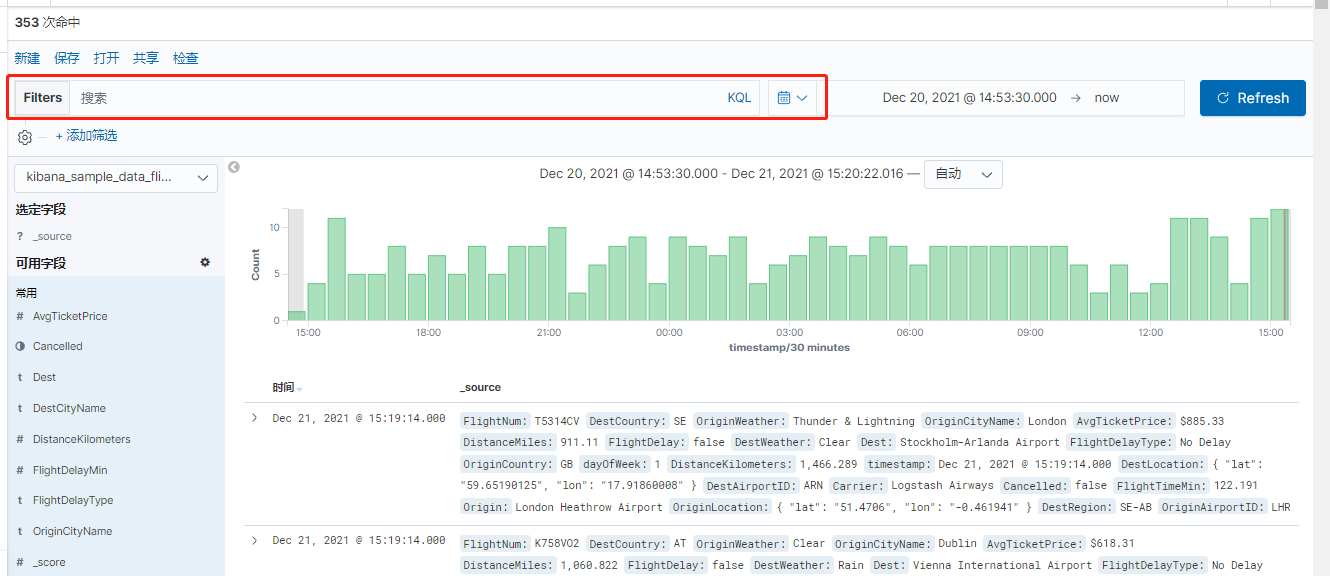
Kibana中的KQL语法
[TOC]一、简介KQL:(Kibana Query Language )查询语法是Kibana为了简化ES查询设计的一套简单查询语法,Kibana支持索引字段和语法补全,可以非常方便的查询数据。如果关闭 KQL,Kibana 将使用 Lucene。在Kibana中使用Filters对数据进行过滤使用KQL语法来完成。二、查询语法2.1 等值匹配(equals)用于查询字段值语法字段名:匹配值示例一response:200 # 匹配到的结果 200 hello world 200 hello 200 world查询出response字段中包含200的文档对象,注意是包含,包含的是200...
ELK启动查看状态等常用命令
[TOC]前言本篇都以7.2.0版本为例。一、ElasticsearchElasticsearch (ES)是一个分布式的 Restful 风格的搜索和数据分析引擎,它具有以下特点:查询:允许执行和合并多种类型的搜索 — 结构化、非结构化、地理位置、度量指标 — 搜索方式随心而变。分析:Elasticsearch 聚合让您能够从大处着眼,探索数据的趋势和模式。速度:很快,可以做到亿万级的数据,毫秒级返回。可扩展性:可以在笔记本电脑上运行,也可以在承载了 PB 级数据的成百上千台服务器上运行。弹性:运行在一个分布式的环境中,从设计之初就考虑到了这一点。灵活性:具备多个案例场景。支持数字、文...
02.Flink应用场景
[TOC]前言本篇文章摘自Flink官网https://flink.apache.org/zh/usecases.html一、概述Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多...
01.Flink简介
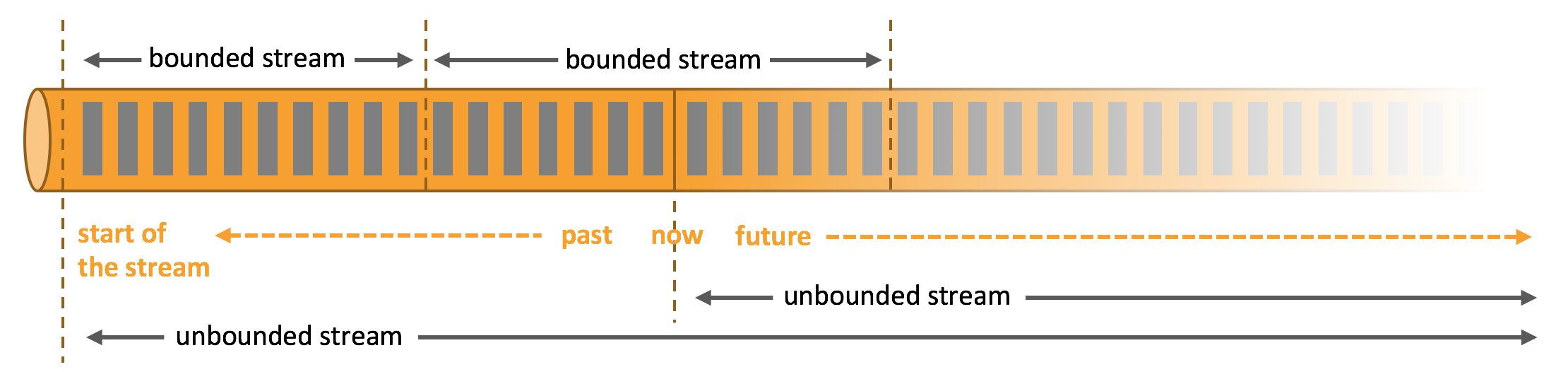
[TOC]一、概念1.1 介绍Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。Flink的理念Apache Flink是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架。1.2 有界流和无界流无界流:有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺...
21.Hive案例实操
[TOC]一、需求统计某视频网站的常规指标,各种 TopN 指标:统计视频观看数 Top10统计视频类别热度 Top10统计出视频观看数最高的 20 个视频的所属类别以及类别包含 Top20 视频的个数统计视频观看数 Top50 所关联视频的所属类别排序统计每个类别中的视频热度 Top10,以 Music 为例统计每个类别视频观看数 Top10统计上传视频最多的用户 Top10 以及他们上传的视频观看次数在前20的视频二、数据准备2.1 数据结构视频表(video_orc)字段备注详细描述videoId视频唯一id(STRING)11位字符串uploader视频上传者(STRING)上传...