
13.Flink流处理API之Source
[TOC]前言flink支持从文件、socket、集合中读取数据。同时也提供了一些接口类和抽象类来支撑实现自定义Source。版本:flink 1.14.2scala 2.12一、基于本地集合的source引入pom.xml依赖<properties> <flink.version>1.14.2</flink.version> <scala.binary.version>2.12</scala.binary.version> <scala.version>${flink.version}<...

12.Flink流处理API之Environment
前言流处理基本步骤:(1)创建环境(类似于spark里的上下文SparkContext);(2)添加数据来源Source;(3)对数据进行Transform处理;(4)添加输出Sink。一、Environment分类1、批处理ExecutionEnvironmentLocalEnvironment:本地模式执行RemoteEnvironment :提交到远程集群执行CollectionEnvironment :集合数据集模式执行OptimizerPlanEnvironment: 不执行作业,仅创建优化的计划PreviewPlanEnvironment: 提取预先优化的执行计划Contex...
11.Flink并行度和任务链
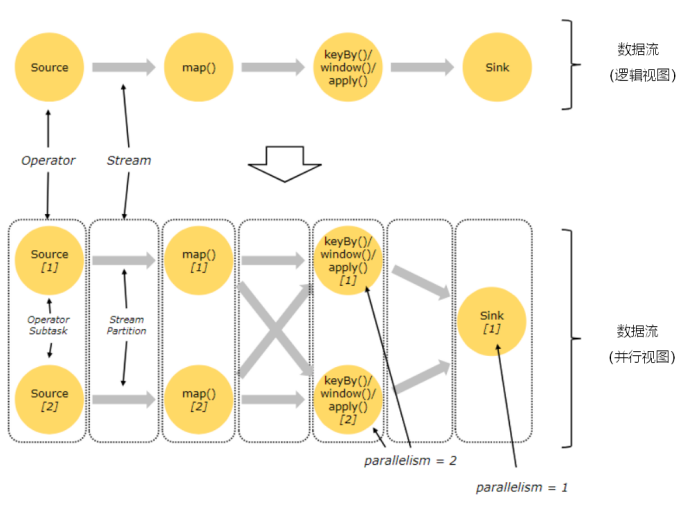
[TOC]一、并行度(Parallelism)1.1 概念 Flink程序的执行具有并行、分布式的特性。 在执行过程中,一个流(stream)包含一个或多个分区(stream partition),而每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中彼此互不依赖地执行。 一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可...
10.Flink数据流和执行图介绍
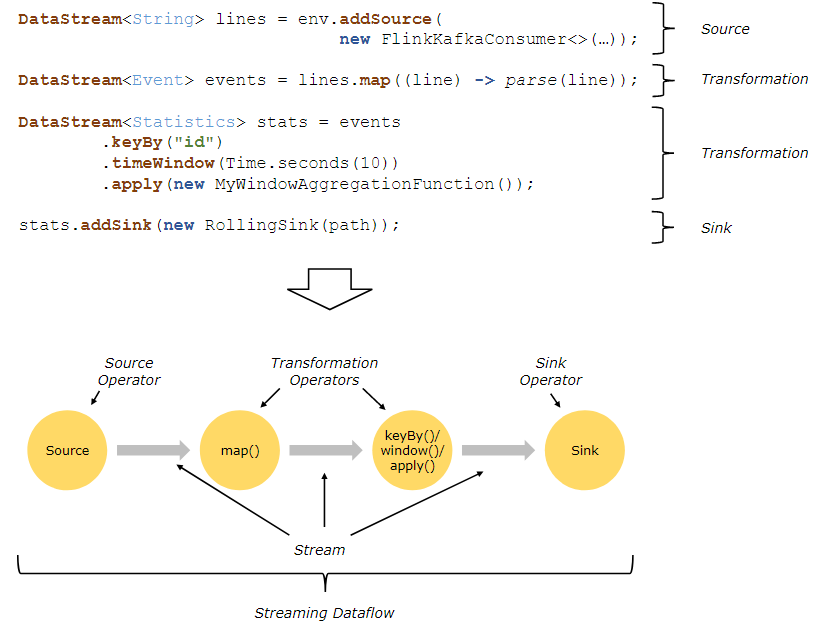
[TOC]一、数据流(Dataflow)1.1 概述数据流(Dataflow):描述了数据如何在不同操作之间流动,Dataflow程序通常表现为有向无环图(DAG)。1.2 分类Flink程序由三部分组成:Source(数据源):负责获取输入数据;Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、A...

ELK生命周期管理使用详解
[TOC]前言一般在使用ELK对日志进行收集时,为了避免单个索引文件过大,通常按日期来对日志做切割,根据日期对产生的日志生成相应的索引。索引名称通常如下方所示:nginx_log-2022.01.01 nginx_log-2022.01.02 nginx_log-2022.01.03 nginx_log-2022.01.04 nginx_log-2022.01.05上方是从nginx采集过来的数据以天为单位来生成索引文件,从而避免索引过大影响查询效率。该方案虽然解决了单个索引文件过大的问题,但是对于日志文件在ES中只需保留15到30天,时间再长的数据也没有多大的应用价值,同时创建大量的索...
09.Flink任务调度原理
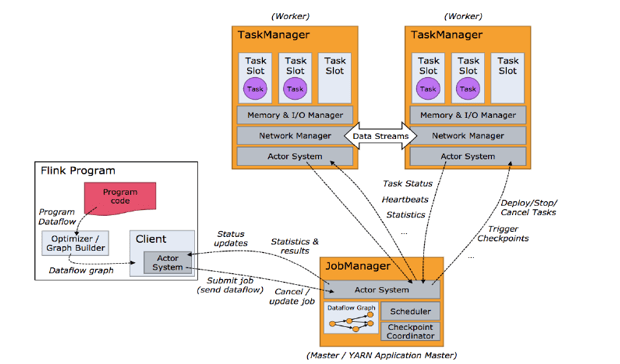
[TOC]一、任务调度原理客户端不是运行时和程序执行的一部分 , 但它用于准备并发送dataflow(JobGraph)给 Master(JobManager),然后,客户端断开连接或者维持连接以等待接收计算结果。当Flink集群启动后,首先会启动一个JobManger和一个或多个的TaskManager。由Client提交任务给JobManager,JobManager再调度任务到各个TaskManager去执行,然后TaskManager将心跳和统计信息汇报给JobManager。TaskManager之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。Client为提交...
08.Flink任务提交流程
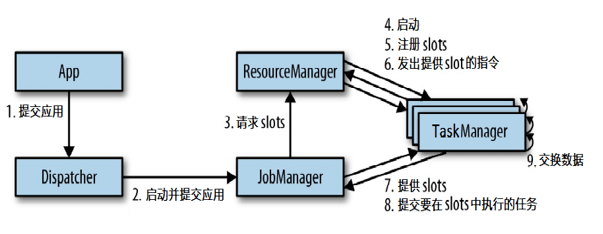
[TOC]一、Flink运行时架构Flink 客户端提交Flink作业到Flink集群Stream Graph 和 Job Graph构建JobManager资源申请任务调度应用容错TaskManager接收JobManager 分发的子任务,管理子任务任务处理(消费数据、处理数据)二、Standalone模式任务提交流程说明(1)App程序通过rest接口将应用提交给Dispatcher;(2)分发器就会启动并将应用提交给一个JobManager;(3)JobManager获得提交过来的应用后,向ResourceManager申请资源(slots),ResouceManager会启动对...
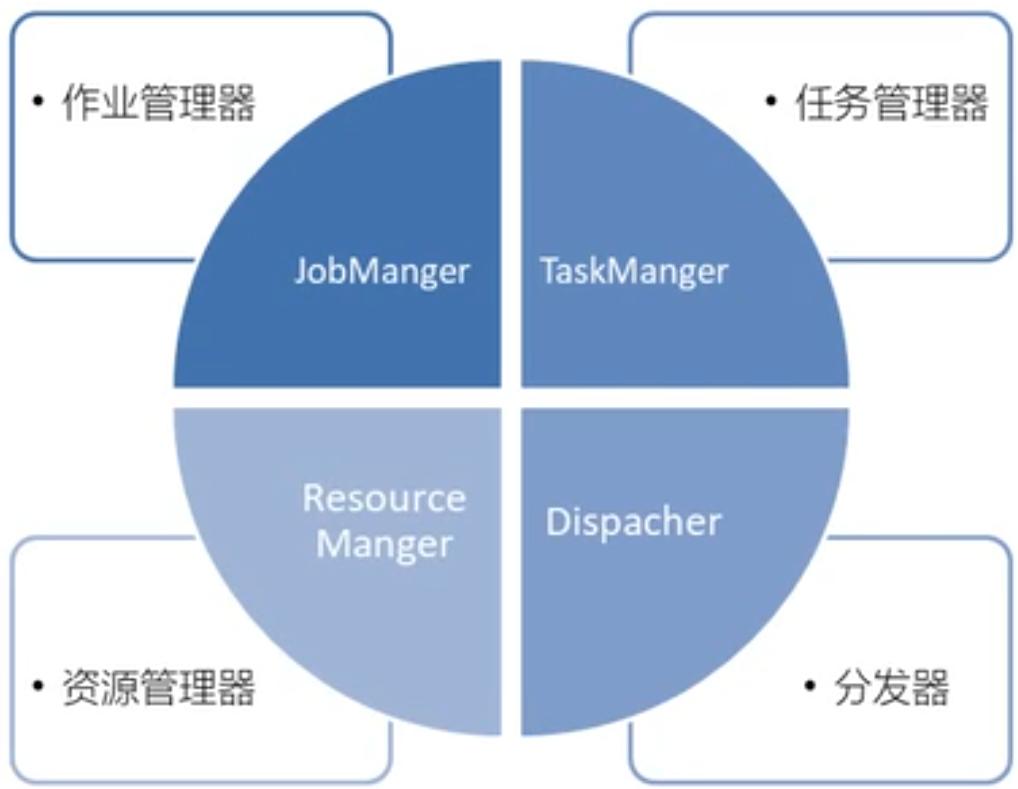
07.Flink运行时组件
[TOC]前言本篇将介绍Flink的四大组件,先在开头做一个简单的概要总结:JobManager:分配任务,调度checkpoint做快照TaskManager:执行任务ResourceManager:资源管理器,分配资源,管理资源Dispacher:方便提交任务的接口,WebUI一、概述Flink 运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作:作业管理器(JobManager)资源管理器(ResourceManager)任务管理器(TaskManager)分发器(Dispatcher)因为 Flink 是用 Java 和 Scala 实现的,所以所有组件都会运...
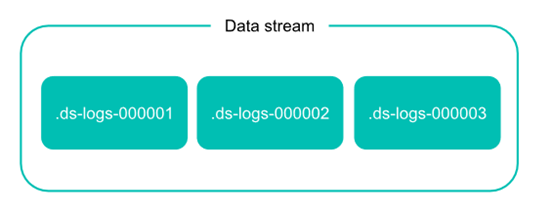
【转载】Elastic Stack之Data Stream的概念
[TOC]时序性数据时间序列数据( time series data )是在不同时间上收集到的数据,用于所描述现象随时间变化的情况。这类数据反映了某一事物、现象等,随时间的变化状态或程度。总的来说,这类数据主要基于时间特性明显,随着时间的流逝,往往过去时间的数据没有现在时间的重要或者敏感。对于 Elastisearch 处理时序性数据,有人总结了主要有以下特点:由时间戳 + 数据组成。基于时间的事件,可以是服务器日志或者社交媒体流。通常搜索最近事件,旧文件变得不太重要。索引的使用主要基于时间,但是数据并不一定随着时间均衡分布。时序性数据一旦存入后很少修改。时序性数据随着时间的增加,数据量...
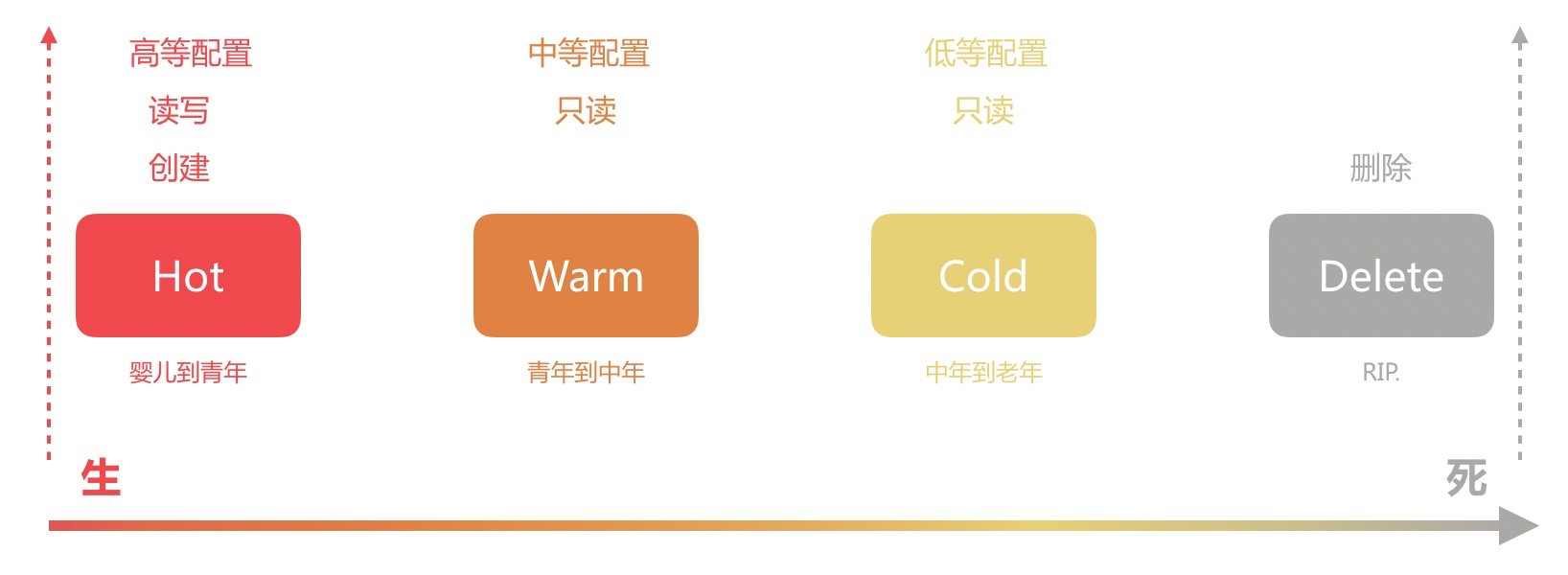
Elasticsearch索引生命周期管理
[TOC]前言在ELK架构中,使用Elasticsearch来存储系统日志时,有如下典型的特点:数据量非常大经常访问新增的数据,随着时间的推移,数据的价值也在逐渐降低随着数据量的增大,Elasticsearch创建索引的数量也在不断增长,这个时候就需要对 索引 进行一定策略的维护管理甚至是删除清理,否则随着数据量越来越多除了浪费磁盘与内存空间之外,还会严重影响 Elasticsearch 的性能。为了对Elasticsearch中的索引进行更好的管理,Elasticsearch在6.6版本中引入了Index Lifecycle Management(索引生命周期管理),简称ILM,并在 ...