李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
01.Flink简介
Leefs
2021-12-19 PM
1626℃
0条
[TOC] ### 一、概念 #### 1.1 介绍 Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。 **Flink的理念** Apache Flink是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架。 #### 1.2 有界流和无界流 + **无界流:**有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。 我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。 + **有界流:**有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。 **Flink 有界数据流和无界数据流** 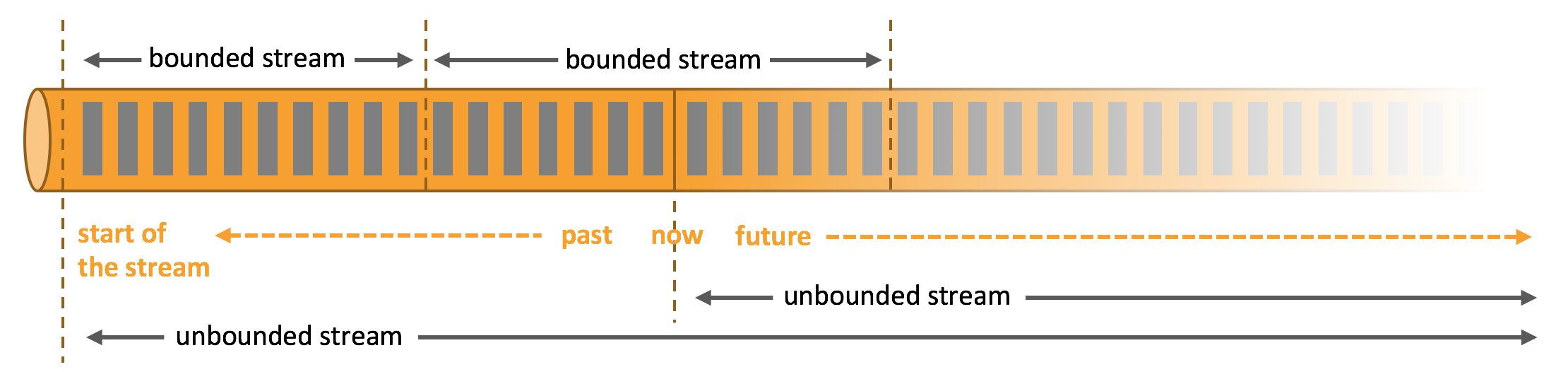 Apache Flink 擅长处理无界和有界数据集,精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。 **Spark Streaming 数据流的拆分**  Spark Streaming将接收到的实时流数据,按照一定时间间隔,对数据进行拆分,交给 Spark Engine 引擎,最终得到一批批的结果。 #### 1.3 批处理和流处理 + **批处理** **特点:**有界、 持久、 大量。 **作用:**批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。 + **流处理** **特点:**无界、 实时。 **作用:**流处理方式无需针对整个数据集执行操作, 而是对通过系统传输的每个数据项执行操作, 一般用于实时统计。 **对比** + **spark:**一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的; + **flink:**一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流。 **这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。** ### 二、Flink和Spark Streaming对比 #### 2.1 数据模型 + spark 采用 RDD 模型,spark streaming的DStream实际上也就是一组组小批数据RDD的集合(微批处理); + flink 基本数据模型是数据流,以及事件(Event)序列。 #### 2.2 运行架构 + spark 是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个; + flink 是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。 ### 三、Flink优点 - Flink 是基于事件驱动 (Event-driven) 的应用,能够同时支持流处理和批处理; - 基于内存的计算,能够保证高吞吐和低延迟,具有优越的性能表现; - 支持精确一次 (Exactly-once) 语意,能够完美地保证一致性和正确性; - 分层 API ,能够满足各个层次的开发需求; - 支持高可用配置,支持保存点机制,能够提供安全性和稳定性上的保证; - 多样化的部署方式,支持本地,远端,云端等多种部署方案; - 具有横向扩展架构,能够按照用户的需求进行动态扩容; - 活跃度极高的社区和完善的生态圈的支持。 ### 四、Flink流处理特性 1. 支持高吞吐、 低延迟、 高性能的流处理 2. 支持带有事件时间的窗口(Window) 操作 3. 支持有状态计算的 Exactly-once 语义 4. 支持高度灵活的窗口(Window) 操作, 支持基于 time、 count、 session,以及 data-driven 的窗口操作 5. 支持具有 Backpressure 功能的持续流模型 6. 支持基于轻量级分布式快照(Snapshot) 实现的容错 7. 一个运行时同时支持 Batch on Streaming 处理和 Streaming 处理 8. Flink 在 JVM 内部实现了自己的内存管理 9. 支持迭代计算 10. 支持程序自动优化: 避免特定情况下 Shuffle、 排序等昂贵操作, 中间结果有必要进行缓存 ### 五、Flink的基石 Flink 之所以能这么流行,离不开它最重要的四个基石:**Checkpoint、 State、 Time、Window**。 首先是 Checkpoint 机制,这是 Flink 最重要的一个特性。 Flink 基于 Chandy-Lamport 算法实现了一个分布式的一致性的快照, 从而提供了一致性的语义。 Chandy-Lamport 算法实际上在 1985 年的时候已经被提出来, 但并没有被很广泛的应用,而 Flink 则把这个算法发扬光大了。Spark 最近在实现 Continue streaming, Continue streaming 的目的是为了降低它处理的延时,其也需要提供这种一致性的语义, 最终采用 Chandy-Lamport 这个算法, 说明 Chandy-Lamport 算法在业界得到了一定的肯定。 提供了一致性的语义之后, Flink 为了让用户在编程时能够更轻松、 更容易地去管理状态,还提供了一套非常简单明了的 State API, 包括里面的有 ValueState、 ListState、MapState,近期添加了 BroadcastState, 使用 State API 能够自动享受到这种一致性的语义。 除此之外,Flink 还实现了 Watermark 的机制,能够支持基于事件的时间的处理,或者说基于系统时间的处理, 能够容忍数据的延时、 容忍数据的迟到、 容忍乱序的数据。另外流计算中一般在对流数据进行操作之前都会先进行开窗, 即基于一个什么样的窗口上做这个计算。 Flink 提供了开箱即用的各种窗口, 比如滑动窗口、 滚动窗口、 会话窗口以及非常灵活的自定义的窗口。 ### 六、Flink的编程模型 Flink提供不同级别的抽象来开发流/批处理应用程序。  + **Stateful Stream Processing:**最底层的API,仅对开发者提供一个有状态的数据流,但是ProcessFunction是Flink提供的最具有表达力的函数接口,该接口提供对事件和状态的细粒度控制。 + **DataStream/DataSet API:**在实际开发中,大多数处理并不需要上述的底层抽象API,而实针对Core API( 无界:DataStream,有界DataSet API)进行编程,它提供了对数据流/集进行各种形式的转换,连接、聚合操作。 + **Table API:**它与之前的API相比表达式更差,使用上却更简捷(编写的代码更少)。开发者可以在Table API 和DataStream/DataSet API之间无缝切换,程序可以混用它们。 + **SQL:**Flink提供的最高级抽象,在语义和表达方面与Table API 类似,但是它将流/批处理表示为SQL查询表达式。 *附参考文章链接:* *https://www.kancloud.cn/willseecloud/bigdata/2276965*
标签:
Flink
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1756.html
上一篇
21.Hive案例实操
下一篇
02.Flink应用场景
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
JavaWEB项目搭建
Nacos
Tomcat
Java编程思想
SQL练习题
排序
HDFS
Stream流
CentOS
Spark Streaming
MyBatis-Plus
散列
Java
Kibana
Eclipse
工具
Typora
Scala
算法
Spark Core
Jquery
VUE
稀疏数组
查找
Hadoop
Zookeeper
Hive
正则表达式
Spark RDD
微服务
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭