李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
21.Hive案例实操
Leefs
2021-12-18 PM
1639℃
0条
[TOC] ### 一、需求 **统计某视频网站的常规指标,各种 TopN 指标:** + 统计视频观看数 Top10 + 统计视频类别热度 Top10 + 统计出视频观看数最高的 20 个视频的所属类别以及类别包含 Top20 视频的个数 + 统计视频观看数 Top50 所关联视频的所属类别排序 + 统计每个类别中的视频热度 Top10,以 Music 为例 + 统计每个类别视频观看数 Top10 + 统计上传视频最多的用户 Top10 以及他们上传的视频观看次数在前20的视频 ### 二、数据准备 #### 2.1 数据结构 + **视频表**(video_orc) | 字段 | 备注 | 详细描述 | | --------- | --------------------------- | ---------------------- | | videoId | 视频唯一id(STRING) | 11位字符串 | | uploader | 视频上传者(STRING) | 上传视频的用户名STRING | | age | 视频年龄(INT) | 视频在平台上的整数天 | | category | 视频类别(`Array<Stirng>`) | 上传视频指定的视频分类 | | length | 视频长度(INT) | 整形数字标识的视频长度 | | views | 观看次数(INT) | 视频被浏览的次数 | | rate | 视频评分(DOUBLE) | 满分5分 | | Ratings | 流量(INT) | 视频的流量,整型数字 | | conments | 评论数(INT) | 一个视频的整数评论数 | | relatedId | 相关视频id(Array) | 相关视频的id,最多20个 | + **用户表**(video_user_orc) | 字段 | 备注 | 字段类型 | | -------- | ------------ | -------- | | uploader | 上传者用户名 | STRING | | videos | 上传视频数 | INT | | friends | 朋友数量 | INT | #### 2.2 将本地文件上传到服务器 + 视频表三个文件 ```basic 1.txt 2.txt 3.txt ``` + 用户表一个文件 ```basic user.txt ``` + 在服务端单独创建两个文件夹 ```shell [hadoop@hadoop001 datas]$ mkdir video [hadoop@hadoop001 datas]$ mkdir user ``` 分别将视频表文件和用户表文件上传到video和user文件夹下。 #### 2.3 准备表 **(1)需要准备的表** + 创建原始数据表:`video_ori`,`video_user_ori` + 创建最终表:`video_orc`,`video_user_orc` 说明:最终表使用了snappy压缩方式,不能直接通过load命令将数据写入到表中,需要先将数据通过load命令写入到原始表中,然后在通过查询方式将原始表中数据写入到最终表当中。 **(2)创建原始数据表** + video_ori ```sql create table video_ori( videoId string, uploader string, age int, category array<string>, length int, views int, rate float, ratings int, comments int, relatedId array<string>) row format delimited fields terminated by "\t" collection items terminated by "&" stored as textfile; ``` + video_user_ori ```sql create table video_user_ori( uploader string, videos int, friends int) row format delimited fields terminated by "\t" stored as textfile; ``` **(3)创建 orc 存储格式带 snappy 压缩的表** + video_orc ```sql create table video_orc( videoId string, uploader string, age int, category array<string>, length int, views int, rate float, ratings int, comments int, relatedId array<string>) stored as orc tblproperties("orc.compress"="SNAPPY"); ``` + video_user_orc ```sql create table video_user_orc( uploader string, videos int, friends int) row format delimited fields terminated by "\t" stored as orc tblproperties("orc.compress"="SNAPPY"); ``` **(4)向原始数据表插入数据** ```sql load data local inpath "/home/hadoop/datas/video" into table video_ori; load data local inpath "/home/hadoop/datas/user" into table video_user_ori; ``` **(5)向最终数据表插入数据** ```sql insert into table video_orc select * from video_ori; insert into table video_user_orc select * from video_user_ori; ``` ### 三、功能实现 #### 3.1 需求一 > 统计视频观看数 Top10 **思路:**使用order by按照views字段做一个全局排序即可,同时我们设置只显示前10条。 **代码实现** ```sql SELECT videoId, views FROM video_orc ORDER BY views DESC LIMIT 10; -- 运行结果 +--------------+-----------+ | videoid | views | +--------------+-----------+ | dMH0bHeiRNg | 42513417 | | 0XxI-hvPRRA | 20282464 | | 1dmVU08zVpA | 16087899 | | RB-wUgnyGv0 | 15712924 | | QjA5faZF1A8 | 15256922 | | -_CSo1gOd48 | 13199833 | | 49IDp76kjPw | 11970018 | | tYnn51C3X_w | 11823701 | | pv5zWaTEVkI | 11672017 | | D2kJZOfq7zk | 11184051 | +--------------+-----------+ ``` #### 3.2 需求二 > 统计视频类别热度Top10 **思路** (1)即统计每个类别有多少个视频,显示出包含视频最多的前 10 个类别。 (2)我们需要按照类别 group by 聚合,然后 count 组内的 videoId 个数即可。 (3)因为当前表结构为:一个视频对应一个或多个类别。所以如果要 group by 类别,需要先将类别进行列转行(展开),然后再进行 count 即可。 (4)最后按照热度排序,显示前10条。 ```sql SELECT t1.category_name , COUNT(t1.videoId) hot FROM ( SELECT videoId, category_name FROM video_orc lateral VIEW explode(category) video_orc_tmp AS category_name ) t1 GROUP BY t1.category_name ORDER BY hot DESC LIMIT 10; -- 运行结果 +-------------------+-------+ | t1.category_name | hot | +-------------------+-------+ | Music | 5375 | | Entertainment | 4557 | | Comedy | 4443 | | Animation | 2953 | | Film | 2953 | | Blogs | 2208 | | People | 2208 | | Politics | 2070 | | News | 2070 | | Sports | 1710 | +-------------------+-------+ ``` #### 3.3 需求三 > 统计出视频观看数最高的 20 个视频的所属类别以及类别包含Top20 视频的个数 **思路** (1)先找到观看数最高的 20 个视频所属条目的所有信息,降序排列 (2)把这 20 条信息中的 category 分裂出来(列转行) (3)最后查询视频分类名称和该分类下有多少个 Top20 的视频 ```sql SELECT t2.category_name, COUNT(t2.videoId) video_sum FROM ( SELECT t1.videoId, category_name FROM ( SELECT videoId, views , category FROM video_orc ORDER BY views DESC LIMIT 20 ) t1 lateral VIEW explode(t1.category) t1_tmp AS category_name ) t2 GROUP BY t2.category_name; -- 运行结果 +-------------------+------------+ | t2.category_name | video_sum | +-------------------+------------+ | Blogs | 2 | | Comedy | 6 | | Entertainment | 6 | | Music | 5 | | People | 2 | | UNA | 1 | +-------------------+------------+ ``` #### 3.4 需求四 > 统计视频观看数 Top50 所关联视频的所属类别排序 **步骤** **(1)查询视频观看数Top50所关联视频,作为关联表t1** ```sql SELECT videoId,relatedId,views FROM video_orc ORDER BY views DESC LIMIT 50; ``` **(2)炸开关联视频行,作为关联表t2** ```sql SELECT relatedId_id FROM t1 latera VIEW explode(t1.relatedId) video_orc_temp AS relatedId_id; ``` **(3)通过关联video_orc表,找到每个关联视频对应的类别,作为关联表t4** ```sql SELECT t2.relatedId_id,t3.category FROM t2 JOIN video_orc t3 ON t2.relatedId_id = t3.videoId; ``` **(4)炸开类别,作为关联表t5** ```sql SELECT t4.category_name,t4.relatedId_id FROM t4 lateral VIEW explode(t4.category) t4_tmp AS category_name ``` **(5)按照类别分组,求每个类别出现的次数,作为关联表t6** ```sql SELECT t5.category_name,COUNT(t5.relaredId_id) category_count FROM t5 GROUP BY t5.category_name ``` **(6)进行排名** ```sql SELECT t6.category_name,t6.category_count, rank() over(ORDER BY t6.category_count DESC) rk form t6 ``` **最终结果** ```sql SELECT t6.category_name, t6.video_sum, rank() over(ORDER BY t6.video_sum DESC ) rk FROM ( SELECT t5.category_name, COUNT(t5.relatedid_id) video_sum FROM ( SELECT t4.relatedid_id, category_name FROM ( SELECT t2.relatedid_id , t3.category FROM ( SELECT relatedid_id FROM ( SELECT videoId, views, relatedid FROM video_orc ORDER BY views DESC LIMIT 50 )t1 lateral VIEW explode(t1.relatedid) t1_tmp AS relatedid_id )t2 JOIN video_orc t3 ON t2.relatedid_id = t3.videoId ) t4 lateral VIEW explode(t4.category) t4_tmp AS category_name ) t5 GROUP BY t5.category_name ORDER BY video_sum DESC ) t6; -- 运行结果 +-------------------+---------------+-----+ | t6.category_name | t6.video_sum | rk | +-------------------+---------------+-----+ | Comedy | 203 | 1 | | Entertainment | 181 | 2 | | Music | 154 | 3 | | Animation | 65 | 4 | | Film | 65 | 4 | | Blogs | 49 | 6 | | People | 49 | 6 | | UNA | 19 | 8 | | News | 14 | 9 | | Places | 14 | 9 | | Politics | 14 | 9 | | Sports | 14 | 9 | | Travel | 14 | 9 | | Howto | 10 | 14 | | DIY | 10 | 14 | | Games | 9 | 16 | | Gadgets | 9 | 16 | | Animals | 6 | 18 | | Pets | 6 | 18 | | Autos | 2 | 20 | | Vehicles | 2 | 20 | +-------------------+---------------+-----+ ``` #### 3.5 需求五 > 统计每个类别中的视频热度 Top10,以 Music 为例 **思路** (1)要想统计 Music 类别中的视频热度 Top10,需要先找到 Music 类别,那么就需要将 category 展开,所以可以创建一张表用于存放 categoryId 展开的数据。 (2)向 category 展开的表中插入数据。 (3)统计对应类别(Music)中的视频热度。 **代码实现** ```sql SELECT t1.videoId, t1.views, t1.category_name FROM ( SELECT videoId, views, category_name FROM video_orc lateral VIEW explode(category) video_orc_tmp AS category_name )t1 WHERE t1.category_name = "Music" ORDER BY t1.views DESC LIMIT 10; -- 运行结果 +--------------+-----------+-------------------+ | t1.videoid | t1.views | t1.category_name | +--------------+-----------+-------------------+ | QjA5faZF1A8 | 15256922 | Music | | tYnn51C3X_w | 11823701 | Music | | pv5zWaTEVkI | 11672017 | Music | | 8bbTtPL1jRs | 9579911 | Music | | UMf40daefsI | 7533070 | Music | | HSoVKUVOnfQ | 6193057 | Music | | NINJQ5LRh-0 | 3794886 | Music | | FLn45-7Pn2Y | 3604114 | Music | | seGhTWE98DU | 3296342 | Music | | eiiU-Fky18s | 3269875 | Music | +--------------+-----------+-------------------+ ``` #### 3.6 需求六 > 统计每个类别中的视频热度Top10 **步骤** **(1)炸开每个视频的类别,作为关联表t1** ```sql SELECT videoId,category_name,views FROM video_orc lateral VIEW explode(category) video_orc_tmp AS category_name ``` **(2)使用开窗函数,按照类别分区,观看数倒序排序,求排名,作为关联表t2** ```sql SELECT t1.videoId,t1.views,t1.category_name, rank() over(PARTITION BY t1.category_name ORDER BY t1.views DESC) rk FROM t1 ``` **(3)取出每个类别的top10** ```sql SELECT t2.videoId,t2.views,t2.category_name,t2.rk FROM t2 WHERE t2.rk <= 10 ``` **最终结果** ```sql SELECT t2.videoId, t2.views, t2.category_name, t2.rk FROM ( SELECT t1.videoId, t1.views, t1.category_name, rank() over(PARTITION BY t1.category_name ORDER BY t1.views DESC ) rk FROM ( SELECT videoId, views, category_name FROM video_orc lateral VIEW explode(category) video_orc_tmp AS category_name )t1 )t2 WHERE t2.rk <=10; ``` #### 3.7 需求七 > 统计上传视频最多的用户Top10以及他们上传的视频观看次数在前20的视频 **思路** (1)求出上传视频最多的 10 个用户; (2)关联video_orc表,求出这10个用户上传的所有的视频,按照观看数取前20。 **实现代码** ```sql SELECT t2.videoId, t2.views, t2.uploader FROM ( SELECT uploader, videos FROM video_user_orc ORDER BY videos DESC LIMIT 10 ) t1 JOIN video_orc t2 ON t1.uploader = t2.uploader ORDER BY t2.views DESC LIMIT 20; ``` ### 四、报错处理 如果在使用SQL查询的时候报如下错误: 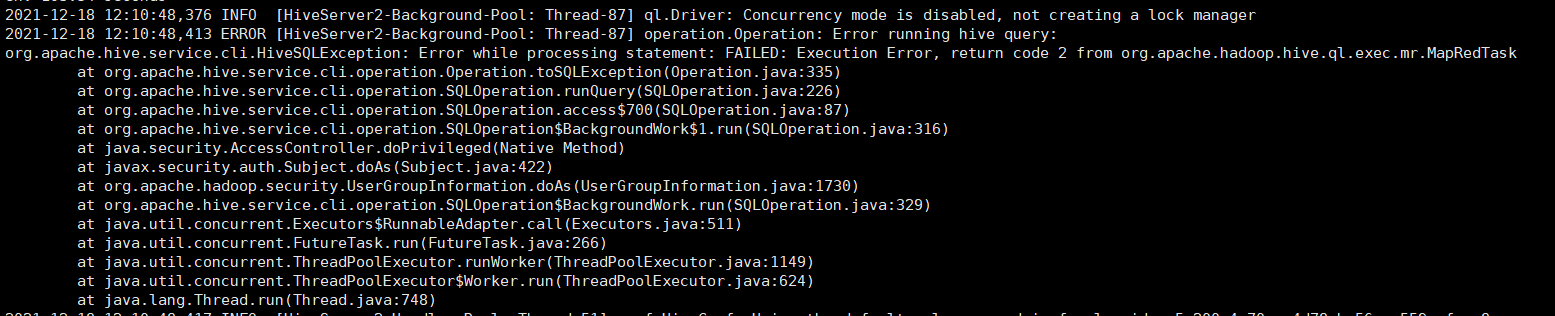 原因是内存不足。 **解决办法:** 修改配置文件: /opt/module/hive-3.1.2/conf/hive-env.sh.template 先修改名字:vim hive-env.sh.template hive-env.sh 然后将里面的 `exprot HADOOP_HEAPSIZE=1024` 打开。  然后把hive服务关掉重新启动即可。 ### 结尾 需要上述文件数据,可以在微信公众号:【Java和大数据进阶】,回复:【hive】即可获取。
标签:
Hadoop
,
Hive
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1752.html
上一篇
20.Hive自定义UDTF函数
下一篇
01.Flink简介
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Netty
Scala
gorm
递归
Java编程思想
JavaWeb
锁
持有对象
正则表达式
Azkaban
Spark
Java
FileBeat
Spark Streaming
BurpSuite
排序
JavaWEB项目搭建
NIO
机器学习
Golang基础
JVM
Flume
pytorch
Eclipse
Docker
队列
Spark SQL
算法
容器深入研究
Shiro
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭