
20.Hive自定义UDTF函数
[TOC]前言之前已经介绍过自定义UDF函数,本篇将继续介绍自定义UDTF函数。一、简介UDTF:即用户定义表生成函数(user-defined table-generating function),作用于单行数据,并且产生多个数据行。UDTF函数的输入与输出值是1:n的关系。UDTF(一进多出)二、自定义UDTF函数2.1 实现步骤(1)引入依赖包;(2)创建自定义类,继承抽象类GenericUDTF;重写initialize方法该方法的入参只有一个,类型是StructObjectInspector,从这里可以取得UDTF作用了几个字段,以及字段类型;initialize的返回值是St...
【转载】scala spark创建DataFrame的多种方式
[TOC]一、通过RDD[Row]和StructType创建import org.apache.spark.rdd.RDD import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{DataFrame, Row, SparkSession} /** * 通过RDD[Row]和StructType创建DataFrame **/ object DataFrameDemo01 { def main(args: ...
19.Hive自定义UDF函数
[TOC]前言本篇使用的版本是Hive 3.1.2。一、UDF函数简介Hive中的用户自定义函数(即User Defined Function,简称UDF),是用户对一些列Hive操作进行封装以实现特定的功能的函数。比如:在Hive的UDF中,可以直接使用select语句,对查询结果按照一定的格式输出。UDF操作作用于单个数据行,并且产生一个数据行作为输出。(一进一出)UDF函数可以直接在方法列进行多层的嵌套使用。二、自定义UDF函数2.1 实现步骤(1)创建Maven项目,引入Hive 3.1.2版本依赖;(2)创建自定义类,继承抽象类GenericUDF,重写抽象方法;(3)打成ja...
SparkSQL导入导出Excel文件
[TOC]前言本篇使用的环境是:spark版本:3.0.0scala版本:2.12一、导入依赖<!--加载Excel--> <dependency> <groupId>com.crealytics</groupId> <artifactId>spark-excel_2.12</artifactId> <version>0.14.0</version> </dependency>注意:如果使用scala 2.11版本需要使用如下依赖,不然会出现依赖版本不匹配&...
18.Hive正则表达式详解
[TOC]前言当真正使用Hive处理数据的时候,往往需要使用正则表达式来对数据做一些过滤操作,本篇将通过一些示例介绍一下Hive中的正则表达式的使用。一、正则匹配LIKE语法A LIKE B操作类型: strings返回类型: boolean或null描述如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合表达式B的正则语法,则为TRUE,否则为FALSE;B中字符"_"表示任意单个字符,而字符"%"表示任意数量的字符。hive> select 'football' like '%ba'; OK false hive> select 'football' ...
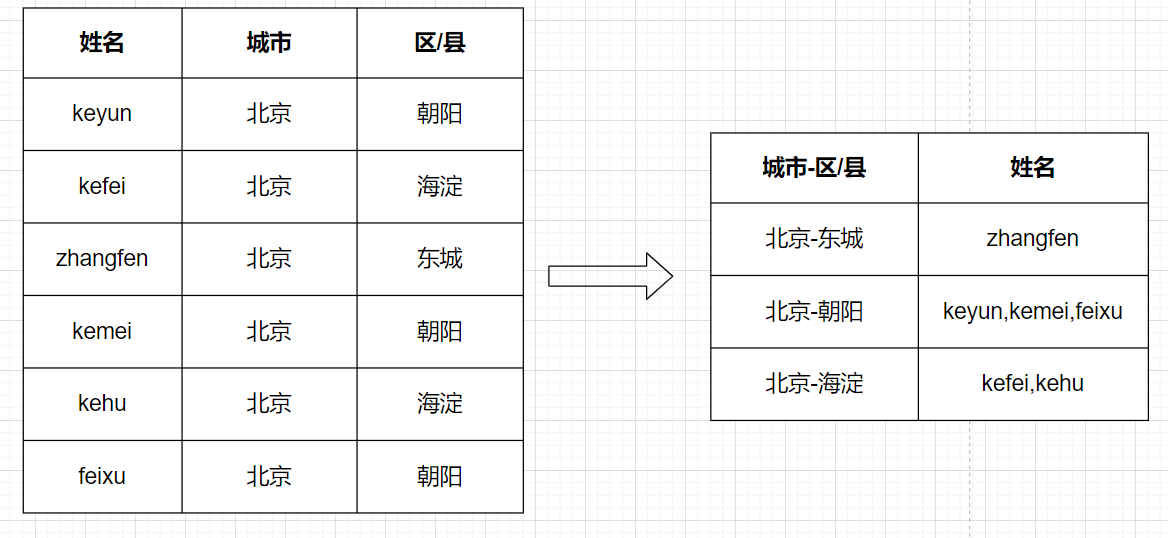
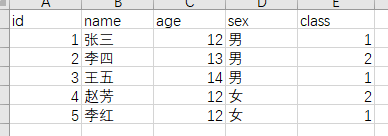
17.Hive行转列和列转行
[TOC]一、行转列1.1 相关函数concatconcat(string A, string B…):用于拼接字符串,返回输入字符串连接后的结果,支持任意个输入字符串concat_wsconcat_ws(string SEP, string A, string B…):与concat类似,返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符;concat_ws(string SEP, array< string>):返回数组连接后的结果;concat_ws(string SEP,string A,string B, array< string>…):可以同...
16.Hive常用内置函数示例
[TOC]一、字符函数示例1.1字符串反转函数语法:reverse(string A)说明:返回字符串A的反转结果0: jdbc:hive2://hadoop001:10000> select reverse("abcdef"); +---------+ | _c0 | +---------+ | fedcba | +---------+1.2 字符串连接函数语法: concat(string A, string B…)说明:返回输入字符串连接后的结果,支持任意个输入字符串0: jdbc:hive2://hadoop001:10000> sele...
15.Hive常用内置函数总结
[TOC]一、查询系统内置函数1.1 查看系统自带的函数show functions;1.2 显示自带的函数的用法语法desc function 【函数名称】;-- 查询upper函数用法 0: jdbc:hive2://hadoop001:10000> desc function upper; -- 运行结果 +----------------------------------------------------+ | tab_name | +-------------------------...
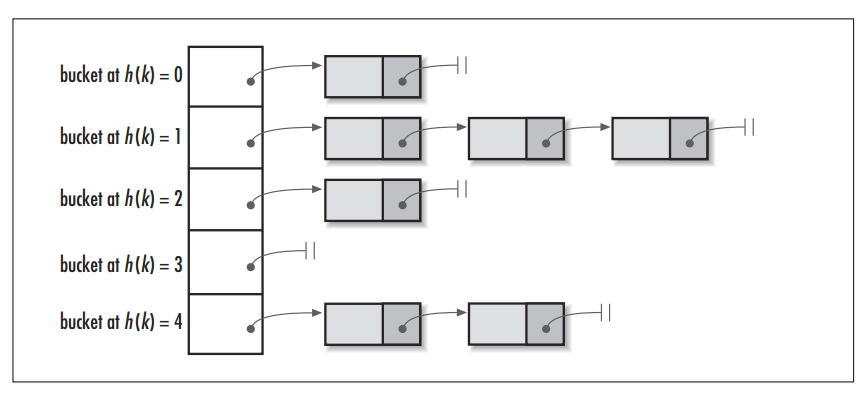
14.Hive分桶表详细介绍
[TOC]一、概述1.1 简介 分区提供了一个隔离数据和优化查询的可行方案,但是并非所有的数据集都可以形成合理的分区,分区的数量也不是越多越好,过多的分区条件可能会导致很多分区上没有数据。 同时Hive会限制动态分区可以创建的最大分区数,用来避免过多分区文件对文件系统产生负担。 鉴于以上原因,Hive还提供了一种更加细粒度的数据拆分方案:分桶表 (bucket Table)。1.2 分桶规则 对分桶字段值进行哈希,哈希值除以桶的个数求余,余数决定了该条记录在哪个桶中,也就是余数相同的在一个桶中。 桶为表加上额...
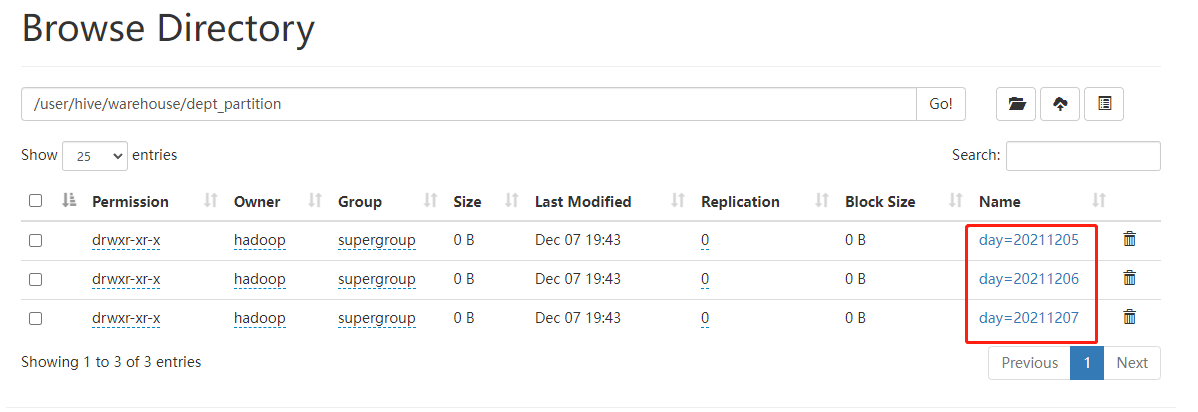
13.Hive分区表详细介绍
[TOC]一、概念简介Hive 中的表对应为HDFS上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大。分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。意义分区的目的是为了就数据,分散到多个子目录中,在执行查询时,可以只选择查询某些子目录中的数据,加快查询效率;只有分区表才有子目录(分区目录);分区目录的名称由两部分确定: 分区列列名=分区列列值;将数...