李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
14.Hive分桶表详细介绍
Leefs
2021-12-08 PM
2110℃
0条
[TOC] ### 一、概述 #### **1.1 简介** 分区提供了一个隔离数据和优化查询的可行方案,但是并非所有的数据集都可以形成合理的分区,分区的数量也不是越多越好,过多的分区条件可能会导致很多分区上没有数据。 同时Hive会限制动态分区可以创建的最大分区数,用来避免过多分区文件对文件系统产生负担。 鉴于以上原因,Hive还提供了一种更加细粒度的数据拆分方案:分桶表 (bucket Table)。 #### **1.2 分桶规则** **对分桶字段值进行哈希,哈希值除以桶的个数求余,余数决定了该条记录在哪个桶中,也就是余数相同的在一个桶中。** 桶为表加上额外结构,链接相同列划分了桶的表,可以使用map-side join更加高效。 #### **1.3 作用** + **进行抽样** 在处理大规模数据集时,在开发和修改查询的阶段,可以使用整个数据集的一部分进行抽样测试查询、修改。可以使得开发更高效。 + **map-side join** 获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。 具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。 比如JOIN操作:对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大减少JOIN的数据量。 **分区针对的是数据的存储路径;分桶针对的是数据文件。** ### 二、分桶表说明 Hive中的分桶概念和 Java 数据结构中的HashMap的分桶概念是一致的。 当调用HashMap的put()方法存储数据时,程序会先对key值调用hashCode()方法计算出hashcode,然后对数组长度取模计算出index,最后将数据存储在数组index位置的链表上,链表达到一定阈值后会转换为红黑树 (JDK1.8+)。 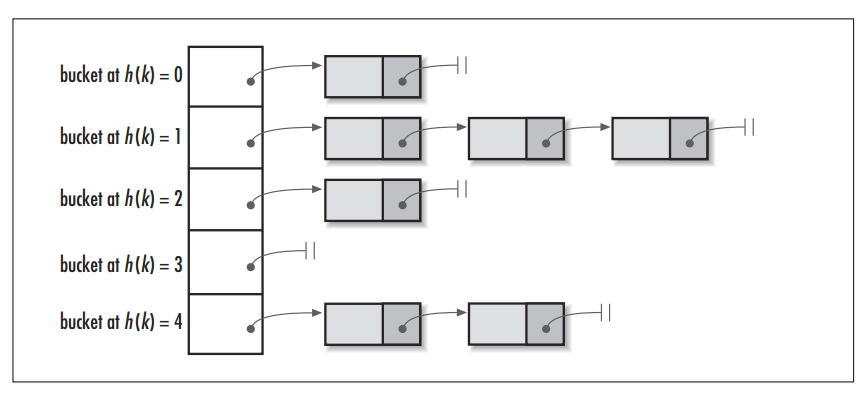 ### 三、分桶表相关操作 **语法结构** ```sql CREATE [EXTERNAL] TABLE <table_name> (<col_name> <data_type> [, <col_name> <data_type> ...])] [PARTITIONED BY ...] CLUSTERED BY (<col_name>) [SORTED BY (<col_name> [ASC|DESC] [, <col_name> [ASC|DESC]...])] INTO <num_buckets> BUCKETS [ROW FORMAT <row_format>] [STORED AS TEXTFILE|ORC|CSVFILE] [LOCATION '<file_path>'] [TBLPROPERTIES ('<property_name>'='<property_value>', ...)]; ``` + `CLUSTERED BY (<col_name>)`:指定分桶的字段 + `SORTED BY <col_name>`:指定数据的排序规则,表示预期的数据就是以这里设置的字段以及排序规则来进行存储 + `INTO num_buckets BUCKETS`:分桶个数 + **数据准备** ```basic 1001 liming1 23 1002 liming2 24 1003 liming3 25 1004 liming4 23 1005 liming5 23 1006 liming6 24 1007 liming7 25 1008 liming8 26 1009 liming9 23 1010 liming10 24 1011 liming11 23 1012 liming12 25 1013 liming13 26 1014 liming14 21 1015 liming15 22 1016 liming16 23 ``` **(1)创建分桶表** ```sql -- 方式一:通过id进行分桶 create table stu_buck(id int, name string,age int) clustered by(id) into 4 buckets row format delimited fields terminated by '\t'; -- 方式二:通过id进行分桶,age进行倒序排序 create table stu_buck2(id int, name string,age int) clustered by(id) sorted by (age desc) into 4 buckets row format delimited fields terminated by '\t'; ``` **(2)查看表结构** ```sql desc formatted stu_buck; ```  **(3)导入数据到分桶表中,load 的方式** ```sql load data inpath '/home/hadoop/datas/stu_buck.txt' into table stu_buck; ``` **(4)查看创建的分桶表中是否分成4个桶**  不难发现虽然分成四个桶,但是每个桶中的Size都是0B,并没有将数据写入到各个桶中 **(5)设置变量** ```sql -- 设置分桶为true set hive.enforce.bucketing = true; -- 设置reduce数量是分桶的数量个数 -- 设置-1,自己根据桶的个数设置reduce个数 set mapreduce.job.reduces=-1; ``` **(6)通过查询的方式导入数据** ```sql -- 创建普通表 create table stu_buck_info(id int, name string,age int) row format delimited fields terminated by '\t'; -- 导入数据 load data local inpath '/home/hadoop/datas/stu_buck.txt' into table stu_buck_info; -- 查询结果是否正确 select * from stu_buck_info; -- 将stu_buck_info表中的数据导入到stu_buck -- 通过id进行分桶 insert into table stu_buck select id,name,age from stu_buck_info cluster by(id); ``` **执行结果**  **其他方式** ```sql insert into table stu_buck select id,name,age from stu_buck_info distribute by(id) sort by(id asc); insert overwrite table stu_buck select id,name,age from stu_buck_info distribute by(id) sort by(id asc); insert overwrite table stu_buck select id,name,age from stu_buck_info cluster by(id); -- 报错:cluster 和 sort 不能共存 insert overwrite table stu_buck select id,name,age from stu_buck_info cluster by(id) sort by(id); ``` **说明** **(1)order by会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。** **(2)sort by不是全局排序,其在数据进入reducer前完成排序。** 因此,如果用sort by进行排序,并且设置`mapred.reduce.tasks>1`,则sort by只保证每个reducer的输出有 序,不保证全局有序。 **(3)distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。** **(4)Cluster by(字段) 除了具有Distribute by的功能外,还会对该字段进行排序。** **(5)创建分桶表并不意味着load进数据也是分桶的,你必须先分好桶,然后再放到表中** **注意:** **排序和分桶的字段相同的时候可以使用Cluster by(字段),此时cluster by 就等同于分桶+排序(sort)** ### 四、抽样查询 对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结 果。Hive 可以通过对表进行抽样来满足这个需求。 **语法** > tablesample(bucket x out of y on id) + x:代表从第几桶开始查询 + y:查询的总桶数,y也可以是总的桶数的倍数或者因子 **具体说明:** ``` y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。 例如,table总共分了4份,当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据。 x表示从哪个bucket开始抽取,如果需要取多个分区,以后的分区号为当前分区号加上y。 例如,table总bucket数为4,tablesample(bucket 1 out of 2),表示总共抽取(4/2=)2个bucket的数据,抽取第1(x)个和第3(x+y)个bucket的数据。 ``` **注意:x不能大于y** **1、查询全部** ```xml select * from stu_buck; select * from stu_buck tablesample(bucket 1 out of 1); ``` **2、查询特定桶** ```sql -- 查询第1个桶的数据 select * from stu_buck tablesample(bucket 1 out of 4 on id); -- 查询结果 +--------------+----------------+---------------+ | stu_buck.id | stu_buck.name | stu_buck.age | +--------------+----------------+---------------+ | 1004 | liming4 | 23 | | 1016 | liming16 | 23 | | 1009 | liming9 | 23 | | 1002 | liming2 | 24 | | 1003 | liming3 | 25 | +--------------+----------------+---------------+ select * from stu_buck tablesample(bucket 1 out of 2 on id); -- 查询结果 +--------------+----------------+---------------+ | stu_buck.id | stu_buck.name | stu_buck.age | +--------------+----------------+---------------+ | 1004 | liming4 | 23 | | 1016 | liming16 | 23 | | 1001 | liming1 | 23 | | 1005 | liming5 | 23 | | 1009 | liming9 | 23 | | 1002 | liming2 | 24 | | 1003 | liming3 | 25 | | 1011 | liming11 | 23 | +--------------+----------------+---------------+ ``` **3、数据块抽样** Hive提供了另外一种按照百分比进行抽样的方式,这种是基于行数的,按照输入路径下的数据块百分比进行的抽样。 ```sql select * from stu_buck tablesample(0.1 percent); -- 执行结果 +--------------+----------------+---------------+ | stu_buck.id | stu_buck.name | stu_buck.age | +--------------+----------------+---------------+ | 1004 | liming4 | 23 | | 1008 | liming8 | 26 | | 1012 | liming12 | 25 | | 1016 | liming16 | 23 | +--------------+----------------+---------------+ ``` 提示:这种抽样方式不一定适用于所有的文件格式。另外,这种抽样的最小抽样单元是一个HDFS数据块。因此,如果表的数据大小小于普通的块大小128M的话,那么将会返回所有行。 ### 五、分桶表操作需要注意的事项 (1)reduce 的个数设置为-1,让 Job 自行决定需要用多少个reduce或者将reduce的个数设置为大于等于分桶表的桶数; (2)从 hdfs 中 load 数据到分桶表中,避免本地文件找不到问题; (3)不要使用本地模式。 附参考文章链接: https://www.bbsmax.com/A/D854rYPVzE/ https://www.jianshu.com/p/004462037557
标签:
Hadoop
,
Hive
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1735.html
上一篇
13.Hive分区表详细介绍
下一篇
15.Hive常用内置函数总结
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
CentOS
Spark Streaming
ajax
Azkaban
Shiro
ClickHouse
Java阻塞队列
Golang基础
HDFS
机器学习
Sentinel
Golang
前端
Flink
Stream流
持有对象
Linux
Tomcat
Elastisearch
Netty
Kibana
Spark SQL
MySQL
nginx
数据结构
gorm
Jenkins
Beego
DataWarehouse
Nacos
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭