李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
13.Hive分区表详细介绍
Leefs
2021-12-07 PM
1875℃
0条
[TOC] ### 一、概念 #### 简介 Hive 中的表对应为HDFS上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大。 分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。**在查询时通过WHERE 子句中的表达式选择查询所需要的指定的分区**,这样的查询效率会提高很多。 #### 意义 + 分区的目的是为了就数据,分散到多个子目录中,在执行查询时,可以只选择查询某些子目录中的数据,加快查询效率; + 只有分区表才有子目录(分区目录); + 分区目录的名称由两部分确定: **分区列列名=分区列列值**; + 将数据导入到指定的分区之后,元信息表中会附加上分区列的信息; + 分区的最终目的是在查询时,使用分区列进行过滤。 ### 二、分类 **Hive分区分为静态分区和动态分区**: + **静态分区:**若分区的值是确定的,那么称为静态分区。新增分区或者是加载分区数据时,已经指定分区名; + **动态分区:**分区的值是非确定的,由输入数据来确定。 ### 三、使用场景 通常,在管理大规模数据集的时候都需要进行分区,比如将日志文件按天进行分区,从而保证数据细粒度的划分,使得查询性能得到提升。 ### 四、分区表基本操作 #### 4.1 静态分区 + 可以根据`PARTITIONED BY`创建分区表,一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。 + 分区是以字段的形式在表结构中存在,通过`describe table`命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。 + 分区建表分为2种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式。 ##### **数据准备** + **dept_01.txt** ```basic 10 ACCOUNTING 1700 20 RESEARCH 1800 ``` + dept_02.txt ``` 30 SALES 1900 40 OPERATIONS 1700 ``` + dept_03.txt ``` 50 TEST 2000 60 DEV 1900 ``` ##### 单级分区 **(1) 创建分区表语法** ```sql create table dept_partition( deptno int, dname string, loc string ) partitioned by (day string) row format delimited fields terminated by '\t'; ``` *注意:分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列。* **(2)查看分区表结构** ```sql describe formatted dept_partition; ``` **(3)加载数据** ```sql 0: jdbc:hive2://hadoop001:10000> load data local inpath '/home/hadoop/datas/dept/dept_01.txt' into table dept_partition partition(day='20211205'); 0: jdbc:hive2://hadoop001:10000> load data local inpath '/home/hadoop/datas/dept/dept_02.txt' into table dept_partition partition(day='20211206'); 0: jdbc:hive2://hadoop001:10000> load data local inpath '/home/hadoop/datas/dept/dept_03.txt' into table dept_partition partition(day='20211207'); ``` *注意:分区表加载数据时,必须指定分区,如果不指定会生成一个默认分区* 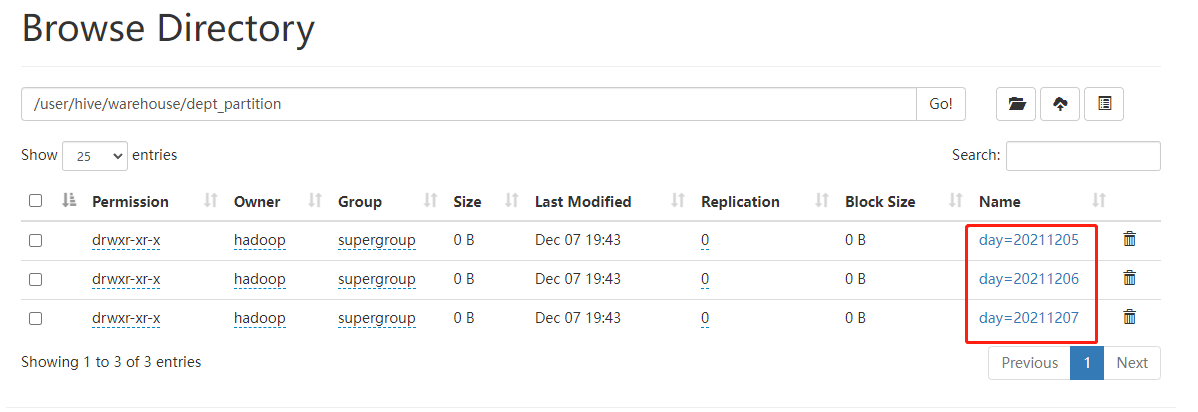 **(4)查询分区表中数据** + 单分区查询 ```sql select * from dept_partition where day='20211205'; ``` + 多分区联合查询 方式一: ```sql select * from dept_partition where day='20211205' union select * from dept_partition where day='20211206' union select * from dept_partition where day='20211207'; ``` 方式二: ```sql select * from dept_partition where day='20211205' or day='20211206' or day='20211207'; ``` **(5)增加分区** + 创建单个分区 ```sql alter table dept_partition add partition(day='20211208'); ```  + 同时创建多个分区 ```sql alter table dept_partition add partition(day='20211209') partition(day='20211210') partition(day='20211211'); ``` *注意:各个分区中间用空格隔开* **(6)删除分区** + 删除单个分区 ```sql alter table dept_partition drop partition (day='20211211'); ``` + 同时删除多个分区 ```sql alter table dept_partition drop partition (day='20211209'),partition (day='20211210'); ``` *注意:各个分区中间用空逗号隔开* **(7)查看分区表中分区数** ```sql show partitions dept_partition; -- 运行结果 +---------------+ | partition | +---------------+ | day=20211205 | | day=20211206 | | day=20211207 | | day=20211208 | +---------------+ ``` **(8)重命名分区** ```sql alter table default.dept_partition partition(day = '20211208') rename to partition(day = '20211209'); ``` ##### 二级分区 **(1)创建二级分区表** ```sql create table dept_partition2( deptno int, dname string, loc string ) partitioned by (day string, hour string) row format delimited fields terminated by '\t'; ``` **(2)加载数据到二级分区表** ```sql load data local inpath '/home/hadoop/datas/dept/dept_01.txt' into table dept_partition2 partition(day='20211205', hour='10'); load data local inpath '/home/hadoop/datas/dept/dept_02.txt' into table dept_partition2 partition(day='20211205', hour='11'); load data local inpath '/home/hadoop/datas/dept/dept_03.txt' into table dept_partition2 partition(day='20211206', hour='10'); ```  **(3)新增分区** ```sql alter table dept_partition2 add partition(day='20211206',hour = '11'); ``` **(4)查询分区数据** ```sql select * from dept_partition2 where day='20211205' and hour='10'; -- 多条件查询 select * from dept_partition2 where (day='20211205' and hour='10') or (day='20211206' and hour='10'); ``` **(5)重命名分区** ``` alter table dept_partition2 partition(day='20211206',hour='11') rename to partition(day='20211206',hour='12'); ``` ##### 修复分区 把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式 **(1)方式一:上传数据后修复** + 上传数据 ```sql -- HDFS中创建目录 dfs -mkdir -p /user/hive/warehouse/dept_partition2/day=20211205/hour=12; -- 将本地数据上传到HDFS dfs -put /home/hadoop/datas/dept/dept_01.txt /user/hive/warehouse/dept_partition2/day=20211205/hour=12; ```  + 查询数据 ```sql 0: jdbc:hive2://hadoop001:10000> select * from dept_partition2 where day='20211205' and hour='12'; -- 查询结果 +-------------------------+------------------------+----------------------+----------------------+-----------------------+ | dept_partition2.deptno | dept_partition2.dname | dept_partition2.loc | dept_partition2.day | dept_partition2.hour | +-------------------------+------------------------+----------------------+----------------------+-----------------------+ +-------------------------+------------------------+----------------------+----------------------+-----------------------+ ``` 查询结果是空的,也就是我们上传上去的数据并没有被查询到 + 执行修复命令 ```sql 0: jdbc:hive2://hadoop001:10000> msck repair table dept_partition2; ``` + 在进行上述查询得到如下结果  **(2)方式二:上传数据后添加分区** + 上传数据 ```sql -- HDFS中创建目录 dfs -mkdir -p /user/hive/warehouse/dept_partition2/day=20211205/hour=13; -- 将本地数据上传到HDFS dfs -put /home/hadoop/datas/dept/dept_02.txt /user/hive/warehouse/dept_partition2/day=20211205/hour=13; ``` + 执行添加分区 ```sql alter table dept_partition2 add partition(day='20211205',hour='13'); ``` + 查询数据 ``` select * from dept_partition2 where day='20211205' and hour='13'; ```  **(3)方式三:创建文件夹后 load 数据到分区** + 创建目录 ```sql dfs -mkdir -p /user/hive/warehouse/dept_partition2/day=20211205/hour=14; ``` + 上传数据 ```sql load data local inpath '/home/hadoop/datas/dept/dept_03.txt' into table dept_partition2 partition(day='20211205',hour='14'); ``` + 查询数据 ```sql select * from dept_partition2 where day='20211205' and hour='14'; ```  #### 4.2 动态分区 上面我们测试静态分区的时候,可以看到操作分区表的时候一定要指定分区,动态分区就解决了这个问题,只不过, 使用 Hive 的动态分区,需要进行相应的配置。 动态分区的值是非确定的,由输入数据来确定。 ##### 1、开启动态分区参数设置 **(1)开启动态分区功能(默认 true,开启)** ```sql 0: jdbc:hive2://hadoop001:10000> set hive.exec.dynamic.partition=true; ``` **(2)指定动态分区模式** ```sql 0: jdbc:hive2://hadoop001:10000> set hive.exec.dynamic.partition.mode=nonstrict; ``` 动态分区模式: + `strict`:表示必须指定至少一个分区为静态分区(默认) + `nonstrict`:模式表示允许所有的分区字段都可以使用动态分区 **其他非必要配置:** + 在所有执行 MR 的节点上,最大一共可以创建多少个动态分区。默认 1000 ```sql hive.exec.max.dynamic.partitions=1000 ``` + 在每个执行 MR 的节点上,最大可以创建多少个动态分区 ```sql hive.exec.max.dynamic.partitions.pernode=100 ``` 该参数需要根据实际 的数据来设定。比如:源数据中包含了一年的数据,即 day 字段有 365 个值,那么该参数就 需要设置成大于 365,如果使用默认值 100,则会报错。 + 整个 MR Job 中,最大可以创建多少个 HDFS 文件。默认 100000 ```sql hive.exec.max.created.files=100000 ``` + 当有空分区生成时,是否抛出异常。一般不需要设置。默认false ```sql hive.error.on.empty.partition=false ``` ##### 2、案例实操 **需求** > 将dept表中的数据按照地区(loc字段),插入到目标表dept_partition的相应分区中。 **(1)创建目标分区表** ```sql create table dept_partition_dy(id int, name string) partitioned by (loc int) row format delimited fields terminated by '\t'; ``` **(2)添加数据** ```sql insert into table dept_partition_dy partition(loc) select deptno, dname, loc from dept_partition; ``` **(3)查看目标分区表的分区情况** ```sql show partitions dept_partition_dy; ```  #### 总结 + 尽量不要用动态分区,因为动态分区的时候,将会为每一个分区分配reducer数量,当分区数量多的时候,reducer数量将会增加,对服务器是一种灾难; + 动态分区和静态分区的区别: + 静态分区不管有没有数据都将会创建该分区; + 动态分区是有结果集将创建,否则不创建。 + hive提供的的严格模式:为了阻止用户不小心提交恶意hql ```sql hive.mapred.mode=nostrict : strict ``` 如果该模式值为strict,将会阻止以下三种查询: + 对分区表查询,where中过滤字段不是分区字段; + 笛卡尔积join查询,join查询语句,不带on条件或者where条件; + 对order by查询,有order by的查询不带limit语句。 *附参考文章链接:* *https://www.boxuegu.com/news/372.html* *https://dunwu.github.io/bigdata-tutorial/hive/hive-table.html* *https://segmentfault.com/a/1190000038348071*
标签:
Hadoop
,
Hive
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1727.html
上一篇
12.Hive经典练习题
下一篇
14.Hive分桶表详细介绍
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Stream流
散列
Java工具类
ajax
Kafka
Java编程思想
ClickHouse
Spring
并发编程
Tomcat
数据结构
RSA加解密
JavaWEB项目搭建
锁
Golang基础
MyBatis-Plus
国产数据库改造
线程池
MyBatis
Sentinel
Jenkins
队列
Nacos
SQL练习题
Kibana
Spark RDD
DataWarehouse
DataX
Flume
SpringBoot
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭