李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
17.Hive行转列和列转行
Leefs
2021-12-12 PM
2521℃
0条
[TOC] ### 一、行转列 #### 1.1 相关函数 + **concat** + `concat(string A, string B…)`:用于拼接字符串,返回输入字符串连接后的结果,支持任意个输入字符串 + **concat_ws** + `concat_ws(string SEP, string A, string B…)`:与concat类似,返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符; + `concat_ws(string SEP, array< string>)`:返回数组连接后的结果; + `concat_ws(string SEP,string A,string B, array< string>…)`:可以同时连接任意数量的字符串和数组。 + **collect_set** + `collect_set(col)`:函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。 + **collect_list** + `collect_list(col)`:函数只接受基本数据类型,它的主要作用是将某字段的值进行不去重汇总,产生array类型字段。 #### 1.2 需求 查询出城市和区县下对应的所有人的姓名。 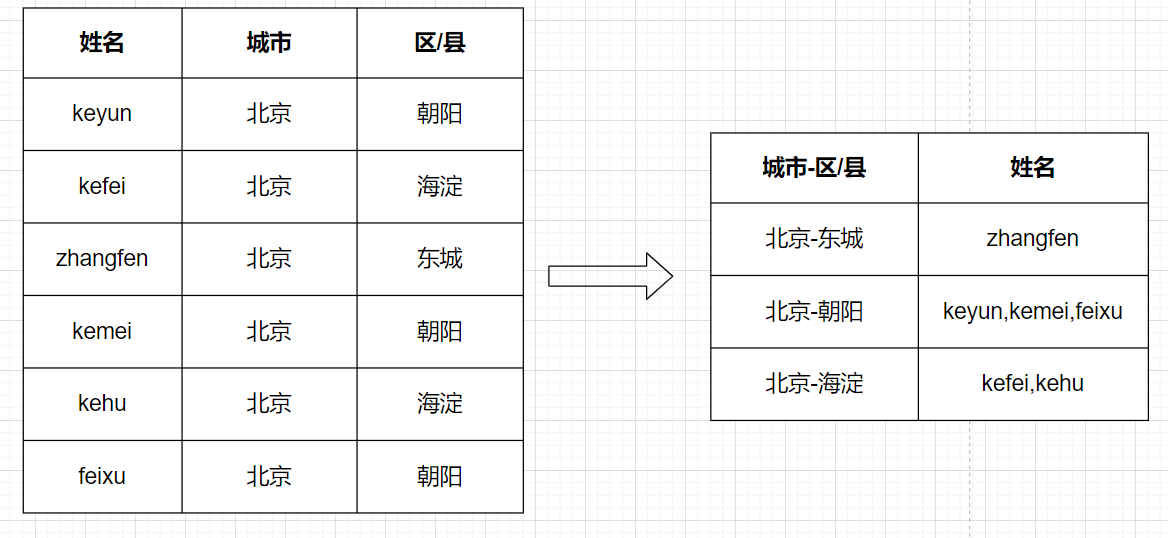 #### 1.3 需求分析  + 第一步:先将城市和区/县字段进行拼接成一个字符串; + 第二步:再根据拼接好的字段进行聚合分组处理。 #### 1.4 数据准备 + 原始数据:city_area_info.txt ```basic name,city,area keyun,北京,朝阳 kefei,北京,海淀 zhangfen,北京,东城 kemei,北京,朝阳 kehu,北京,海淀 feixu,北京,朝阳 ``` + 创建表 ```sql create table row_to_column( name string, city string, area string ) row format delimited fields terminated by ','; ``` + 向表中导入数据 ```sql load data local inpath '/home/hadoop/datas/city_area_info.txt' into table row_to_column; ``` + 验证导入结果 ```sql select * from row_to_column; -- 输出结果 +---------------------+---------------------+---------------------+ | row_to_column.name | row_to_column.city | row_to_column.area | +---------------------+---------------------+---------------------+ | keyun | 北京 | 朝阳 | | kefei | 北京 | 海淀 | | zhangfen | 北京 | 东城 | | kemei | 北京 | 朝阳 | | kehu | 北京 | 海淀 | | feixu | 北京 | 朝阳 | +---------------------+---------------------+---------------------+ ``` #### 1.5 功能实现 + **第一步:**将城市和区县用-进行拼接,连接成一个字符串 ```sql select concat_ws('-',city,area) city_area, name from row_to_column; -- 输出结果 +------------+-----------+ | city_area | name | +------------+-----------+ | 北京-朝阳 | keyun | | 北京-海淀 | kefei | | 北京-东城 | zhangfen | | 北京-朝阳 | kemei | | 北京-海淀 | kehu | | 北京-朝阳 | feixu | +------------+-----------+ ``` + **第二步:**在第一步的基础上根据拼接好的city_area进行分组,通过collect_list或者collect_set将同组多行数据根据name字段聚合成一个数组(array< string>),再通过concat_ws对数组进行拆分拼接 ```sql select t1.city_area, concat_ws(',',collect_list(t1.name)) from ( select concat_ws('-',city,area) city_area, name from row_to_column )t1 group by t1.city_area; -- 输出结果 +---------------+--------------------+ | t1.city_area | _c1 | +---------------+--------------------+ | 北京-东城 | zhangfen | | 北京-朝阳 | keyun,kemei,feixu | | 北京-海淀 | kefei,kehu | +---------------+--------------------+ ``` ### 二、列转行 #### 2.1 相关函数 + **split** + `split(string str,string x)`:将字符串按照后面的分隔符切割,转换成数组array + **explode** + `explode(col)`:将hive一列中复杂的array或者map结构拆分成多行。 + **lateral view** + 用法:`LATERAL VIEW udtf(expression) tableAlias AS columnAlias` + 解释:lateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。 lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。 #### 2.2 需求 将各个同学擅长的学科进行展开  #### 2.3 分析 + **第一步**:用split将擅长学科根据逗号进行分割,用explode函数将切割好的数组炸开; + **第二步**:因为在炸开数组以后需要对姓名进行填充,所以需要用lateral view函数对原表的姓名字段进行侧写。  #### 2.4 数据准备 + 原始数据:good_subjects.txt ```basic name good_subjects 小明 数学,语文,英语 小红 语文,英语 小风 语文,数学 ``` + 创建表 ```sql create table column_to_row( `name` string, good_subjects string ) row format delimited fields terminated by '\t'; ``` + 向表中导入数据 ```sql load data local inpath '/home/hadoop/datas/good_subjects.txt' into table column_to_row; ``` + 验证数据 ```sql select * from column_to_row; -- 查询结果 +---------------------+------------------------------+ | column_to_row.name | column_to_row.good_subjects | +---------------------+------------------------------+ | 小明 | 数学,语文,英语 | | 小红 | 语文,英语 | | 小风 | 语文,数学 | +---------------------+------------------------------+ ``` #### 2.5 功能实现 + **第一步:**用split将good_subjects切分成数组,用explode函数将good_subjects数组炸开 ```sql select explode(split(good_subjects,',')) AS subjects from column_to_row; -- 运行结果 +-----------+ | subjects | +-----------+ | 数学 | | 语文 | | 英语 | | 语文 | | 英语 | | 语文 | | 数学 | +-----------+ ``` + **第二步**:用lateral view函数对原表的name字段对炸开表进行侧写 ```sql select name, subjects from column_to_row lateral view explode(split(good_subjects,',')) name_tmp AS subjects; -- 运行结果 +-------+-----------+ | name | subjects | +-------+-----------+ | 小明 | 数学 | | 小明 | 语文 | | 小明 | 英语 | | 小红 | 语文 | | 小红 | 英语 | | 小风 | 语文 | | 小风 | 数学 | +-------+-----------+ ```
标签:
Hadoop
,
Hive
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1742.html
上一篇
16.Hive常用内置函数示例
下一篇
18.Hive正则表达式详解
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
随笔
容器深入研究
RSA加解密
MyBatisX
DataX
Ubuntu
Shiro
Filter
Spark SQL
数据结构
Java编程思想
Redis
Tomcat
稀疏数组
ajax
Zookeeper
Quartz
SpringCloud
MyBatis-Plus
Spring
持有对象
微服务
Eclipse
gorm
Sentinel
Java阻塞队列
工具
Beego
递归
并发线程
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭