Kibana中的KQL语法
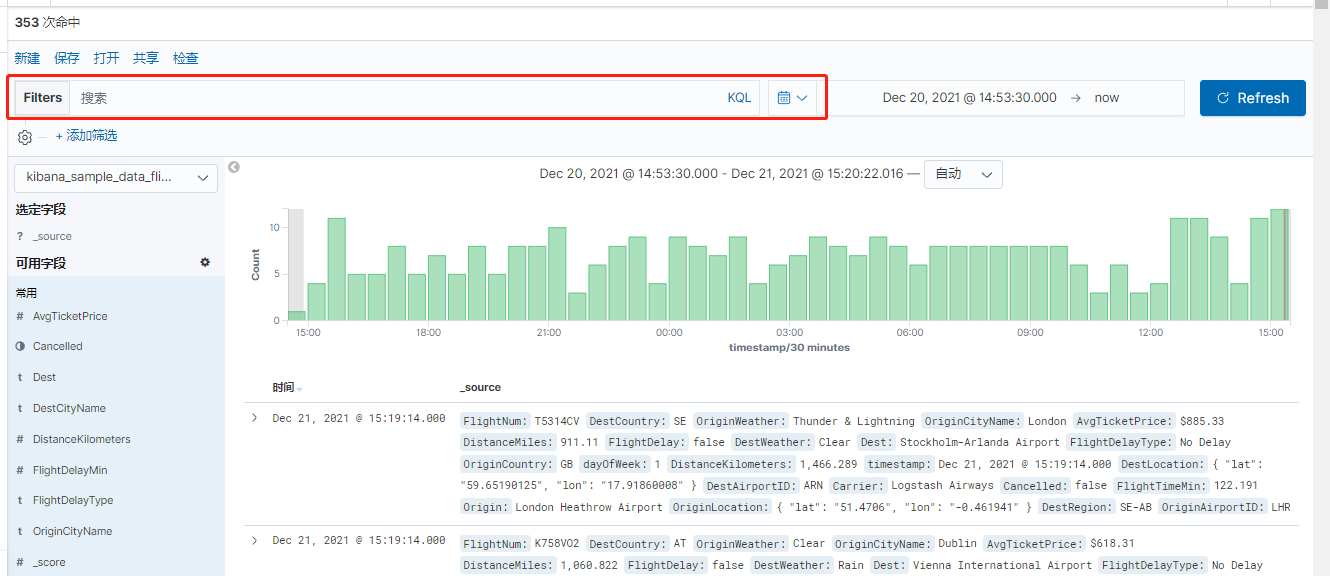
[TOC]一、简介KQL:(Kibana Query Language )查询语法是Kibana为了简化ES查询设计的一套简单查询语法,Kibana支持索引字段和语法补全,可以非常方便的查询数据。如果关闭 KQL,Kibana 将使用 Lucene。在Kibana中使用Filters对数据进行过滤使用KQL语法来完成。二、查询语法2.1 等值匹配(equals)用于查询字段值语法字段名:匹配...
ELK启动查看状态等常用命令
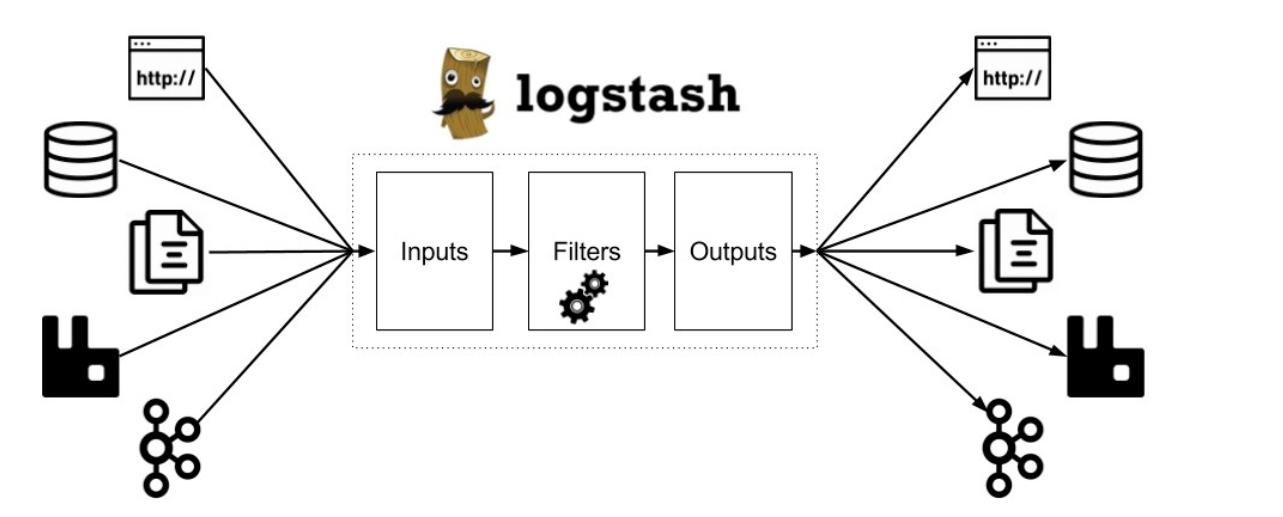
[TOC]前言本篇都以7.2.0版本为例。一、ElasticsearchElasticsearch (ES)是一个分布式的 Restful 风格的搜索和数据分析引擎,它具有以下特点:查询:允许执行和合并多种类型的搜索 — 结构化、非结构化、地理位置、度量指标 — 搜索方式随心而变。分析:Elasticsearch 聚合让您能够从大处着眼,探索数据的趋势和模式。速度:很快,可以做到亿万级的数据...
02.Flink应用场景
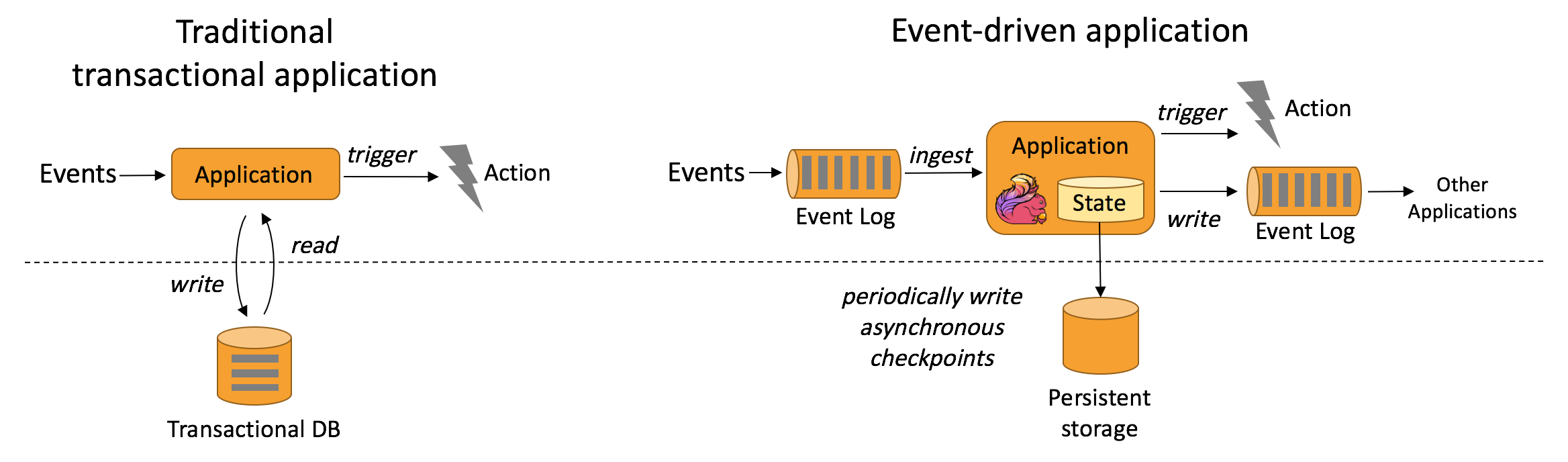
[TOC]前言本篇文章摘自Flink官网https://flink.apache.org/zh/usecases.html一、概述Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架...
01.Flink简介
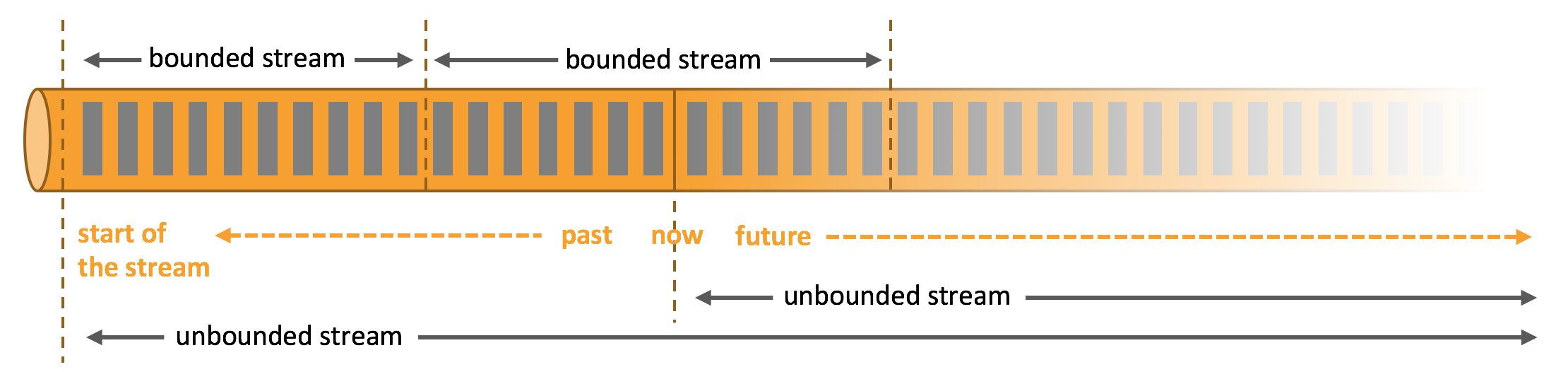
[TOC]一、概念1.1 介绍Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。Flink的理念Apache Flink是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架。1.2 有界流和无界流无界流:有定义流的开始,但没有定义流的结束。它们会无休止...
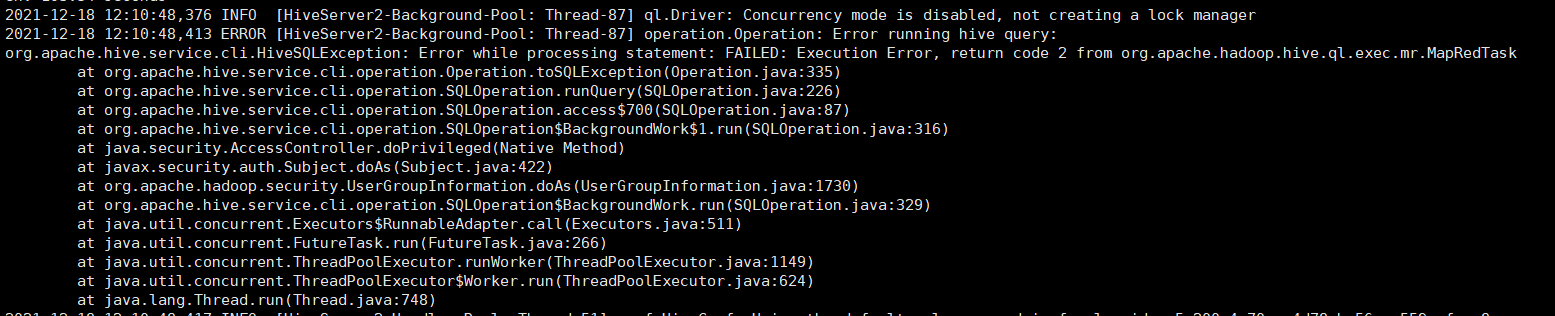
21.Hive案例实操
[TOC]一、需求统计某视频网站的常规指标,各种 TopN 指标:统计视频观看数 Top10统计视频类别热度 Top10统计出视频观看数最高的 20 个视频的所属类别以及类别包含 Top20 视频的个数统计视频观看数 Top50 所关联视频的所属类别排序统计每个类别中的视频热度 Top10,以 Music 为例统计每个类别视频观看数 Top10统计上传视频最多的用户 Top10 以及他们上传...

20.Hive自定义UDTF函数
[TOC]前言之前已经介绍过自定义UDF函数,本篇将继续介绍自定义UDTF函数。一、简介UDTF:即用户定义表生成函数(user-defined table-generating function),作用于单行数据,并且产生多个数据行。UDTF函数的输入与输出值是1:n的关系。UDTF(一进多出)二、自定义UDTF函数2.1 实现步骤(1)引入依赖包;(2)创建自定义类,继承抽象类Gener...
【转载】scala spark创建DataFrame的多种方式
[TOC]一、通过RDD[Row]和StructType创建import org.apache.spark.rdd.RDD import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{DataFrame, Row, Spark...
19.Hive自定义UDF函数
[TOC]前言本篇使用的版本是Hive 3.1.2。一、UDF函数简介Hive中的用户自定义函数(即User Defined Function,简称UDF),是用户对一些列Hive操作进行封装以实现特定的功能的函数。比如:在Hive的UDF中,可以直接使用select语句,对查询结果按照一定的格式输出。UDF操作作用于单个数据行,并且产生一个数据行作为输出。(一进一出)UDF函数可以直接在方...
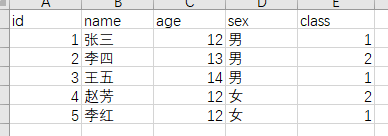
SparkSQL导入导出Excel文件
[TOC]前言本篇使用的环境是:spark版本:3.0.0scala版本:2.12一、导入依赖<!--加载Excel--> <dependency> <groupId>com.crealytics</groupId> <artifactId>spark-excel_2.12</artifactId> ...