李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
01.Table API和Flink SQL介绍
Leefs
2022-02-17 PM
1526℃
0条
[TOC] ### 前言 前面我们介绍过,Flink的API是分层的,而Table API与SQL就位于最顶层。也就是说Table API和SQL是Flink中封装程度最高的API。 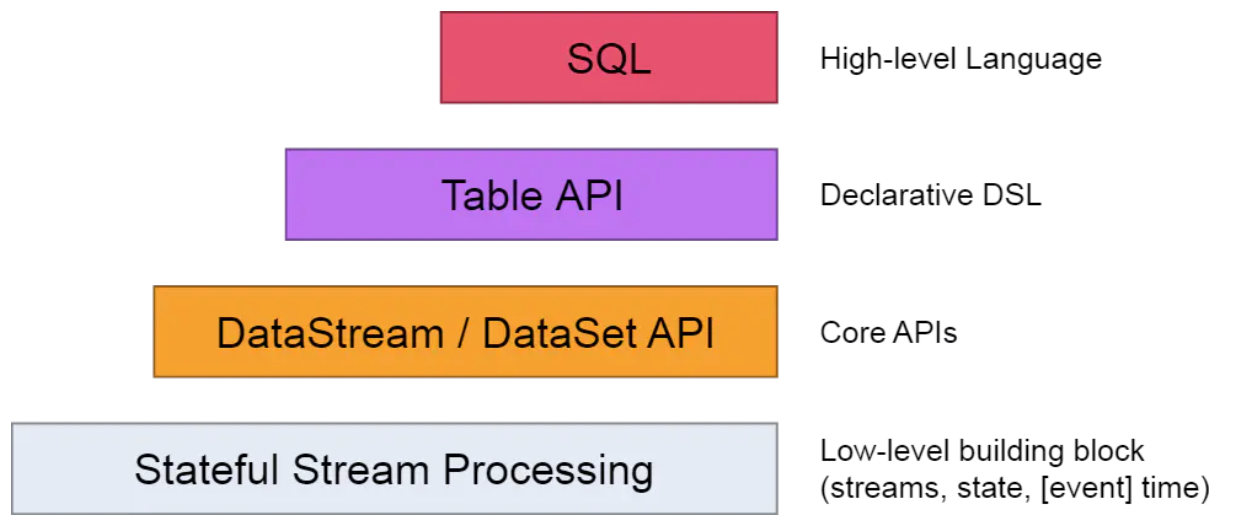 Flink 自从 0.9 版本开始支持 Table & SQL 功能一直处于完善开发中,且在不断进行迭代。 ### 一、概述 **Flink 本身是批流统一的处理框架,所以 Table API 和 SQL,就是批流统一的上层处理 API。** 目前功能尚未完善,处于活跃的开发阶段。 **Table API**:是一套内嵌在 Java 和 Scala 语言中的查询 API,它允许我们以非常直观的方式, 组合来自一些关系运算符的查询(比如 select、filter 和 join)。 **Flink SQL**:就是直接可以在代码中写 SQL,来实现一些查询(Query)操作。Flink 的 SQL 支持,基于实现了 SQL 标准的 Apache Calcite(Apache 开源SQL解析工具)。 无论输入是批输入还是流式输入,在这两套 API 中,指定的查询都具有相同的语义,得到相同的结果。 **注意** Table API和SQL对有些算子还没有支持。所以在使用Flink原生Table API和SQL时最好要明确其是否支持业务场景。若现有的Table API和SQL无法满足业务需求,那么我们就需要使用DataStream API或DataSet API来实现了。 ### 二、需要引入的依赖 Table API 和 SQL 需要引入的依赖有两个:**planner 和 bridge**。 ```xml <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner_2.12</artifactId> <version>1.10.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-scala-bridge_2.12</artifactId> <version>1.10.1</version> </dependency> ``` **注意** + 本次使用的Scala版本为2.12,Flink版本为1.10.1 **说明** + **flink-table-planner**:planner 计划器,是 table API 最主要的部分,提供了运行时环境和生成程序执行计划的planner; + **flink-table-api-scala-bridge**:bridge 桥接器,主要负责 table API 和 DataStream/DataSet API 的连接支持,按照语言分 java 和 scala。 这里的两个依赖,是 IDE 环境下运行需要添加的;如果是生产环境,lib 目录下默认已经有了planner,就只需要有 bridge 就可以了。 当然,如果想使用用户自定义函数,或是跟 kafka 做连接,需要有一个 SQL client,这个包含在 flink-table-common 里。 ### 三、两种 planner(old & blink)的区别 1. **批流统一**:Blink 将批处理作业,视为流式处理的特殊情况。所以,blink 不支持表和 DataSet 之间的转换,批处理作业将不转换为 DataSet 应用程序,而是跟流处理一样,转换为 DataStream 程序来处理。 2. 因为批流统一 , `Blink planner` 也不支持 `BatchTableSource` , 而使用有界的 `StreamTableSource` 代替。 3. `Blink planner` 只支持全新的目录,不支持已弃用的 `ExternalCatalog`。 4. 旧 planner 和 `Blink planner` 的 `FilterableTableSource` 实现不兼容。旧的 planner 会把 `PlannerExpressions` 下推到 `filterableTableSource` 中,而 `blink planner` 则会把 Expressions 下推。 5. 基于字符串的键值配置选项仅适用于 `Blink planner`。 6. `PlannerConfig` 在两个 planner 中的实现不同。 7. `Blink planner` 会将多个 sink 优化在一个 DAG 中(仅在 TableEnvironment 上受支持,而在 StreamTableEnvironment 上不受支持)。而旧 planner 的优化总是将每一个 sink 放在一个新的 DAG 中,其中所有 DAG 彼此独立。 8. 旧的 planner 不支持目录统计,而 `Blink planner` 支持。 ### 四、使用示例 #### 4.1 准备数据 + **sensor.txt** ```basic sensor_1,1547718199,35.8 sensor_6,1547718201,15.4 sensor_7,1547718202,6.7 sensor_10,1547718205,38.1 sensor_1,1547718206,32 sensor_1,1547718208,36.2 sensor_1,1547718210,29.7 ``` #### 4.2 需求 > 筛选出id为sensor_1的温度值并打印到控制台 #### 4.3 引入依赖 直接引入上方二中的两个依赖 #### 4.4 代码实现 ```java import org.apache.flink.streaming.api.scala._ import org.apache.flink.table.api.{EnvironmentSettings, Table} import org.apache.flink.table.api.scala._ /** * @author lilinchao * @date 2022/2/17 * @description 筛选出id为sensor_1的温度值并打印到控制台 **/ object TableApiDemo { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) val inputStream: DataStream[String] = env.readTextFile("./datas/sensor.txt") val dataStream: DataStream[SensorReading] = inputStream.map(data => { val dataArray: Array[String] = data.split(",") SensorReading(dataArray(0).trim, dataArray(1).trim.toLong, dataArray(2).trim.toDouble) }) //基于env创建tableEnv val settings: EnvironmentSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build() val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env,settings) //从一条流创建一张表 val dataTable: Table = tableEnv.fromDataStream(dataStream) //从表里选取特定的数据 val selectedTable: Table = dataTable.select('id, 'temperature) .filter("id = 'sensor_1'") //进行控制台打印 val selectedStream: DataStream[(String, Double)] = selectedTable.toAppendStream[(String,Double)] selectedStream.print() env.execute("TableApiDemo") } } // 定义样例类,传感器 id,时间戳,温度 case class SensorReading(id: String, timestamp: Long, temperature: Double) ```
标签:
Flink
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1902.html
上一篇
35.Flink和Kafka实现端到端exactly-once语义详解
下一篇
02.Table API和Flink SQL程序的结构
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Spark
MyBatis
Netty
稀疏数组
JavaWEB项目搭建
Golang
RSA加解密
Java阻塞队列
微服务
JavaWeb
并发线程
Spark Streaming
锁
Elasticsearch
VUE
Zookeeper
CentOS
线程池
并发编程
SQL练习题
Azkaban
Spark SQL
FastDFS
pytorch
Sentinel
Hive
Java工具类
Git
Hadoop
Scala
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭