李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
02.Table API和Flink SQL程序的结构
Leefs
2022-02-18 PM
1639℃
0条
[TOC] ### 前言 Table API和SQL两者结合非常紧密,它们的API与关系型数据库中查询非常相似,本质上它们都依赖于一个像数据表的结构:`Table`。 在具体执行层面,Flink将Table API或SQL语句使用一个名为执行计划器(Planner)的组件将关系型查询转换为可执行的Flink作业,并对作业进行一些优化。 ### 一、基本程序结构 Table API 和 SQL 集成在同一套API中。 这套 API 的核心概念是Table,用作查询的输入和输出。 所有用于批处理和流处理的 Table API 和 SQL 程序都遵循相同的模式。 下面的代码示例展示了 Table API 和 SQL 程序的通用结构。 ```java val tableEnv = ... // 创建表的执行环境 // 创建一张表,用于读取数据 tableEnv.connect(...).createTemporaryTable("inputTable") // 注册一张表,用于把计算结果输出 tableEnv.connect(...).createTemporaryTable("outputTable") // 通过 Table API 查询算子,得到一张结果表 val result = tableEnv.from("inputTable").select(...) // 通过 SQL查询语句,得到一张结果表 val sqlResult = tableEnv.sqlQuery("SELECT ... FROM inputTable ...") // 将结果表写入输出表中 result.insertInto("outputTable") sqlResult.insertInto("outputTable"); // execute tableEnv.execute("table"); ``` **说明** 目前的`Table API & SQL`要与`DataStream/DataSet API`相结合来使用,主要需要以下步骤: 1. 创建执行环境(ExecutionEnvironment)和表环境(TableEnvironment) 2. 获取数据表`Table` 3. 使用Table API或SQL在`Table`上做查询等操作 4. 将结果输出到外部系统 5. 调用`execute()`,执行作业 ### 二、TableEnvironment `TableEnvironment`是Table API & SQL编程中最基础的类,也是整个程序的入口,它包含了程序的核心上下文信息。`TableEnvironment`的核心功能包括: - 连接外部系统 - 向目录(Catalog)中注册`Table`或者从中获取`Table` - 执行Table API或SQL操作 - 注册用户自定义函数 - 提供一些其他配置功能 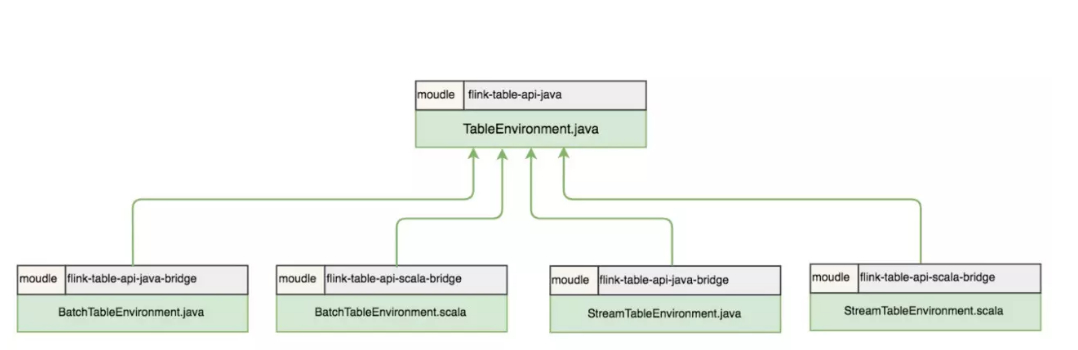 从上图中可以看到,Flink 1.10保留了5个`TableEnvironment`。其中,`TableEnvironment`是最顶级的接口,`StreamTableEnvironment`和`BatchTableEnvironment`都提供了Java和Scala两个实现: + `org.apache.flink.table.api.TableEnvironment`:兼容Java和Scala,统一流批处理,适用于整个作业都使用 Table API & SQL 编写程序的场景。 + `org.apache.flink.table.api.java.StreamTableEnvironment`和`org.apache.flink.table.api.scala.StreamTableEnvironment`:分别用于Java和Scala的流处理场景,提供了`DataStream`和`Table`之间相互转换的接口。如果作业除了基于Table API & SQL外,还有和`DataStream`之间的转化,则需要使用`StreamTableEnvironment`。 + `org.apache.flink.table.api.java.BatchTableEnvironment`和`org.apache.flink.table.api.scala.BatchTableEnvironment`:分别用于Java和Scala的批处理场景,提供了`DataSet`和`Table`之间相互转换的接口。如果作业除了基于Table API & SQL外,还有和`DataSet`之间的转化,则使用`BatchTableEnvironment`。 ### 三、创建TableEnvironment #### 3.1 Old planner & Stream(基于老版本的planner的流处理) 用户使用 Old planner,进行流计算的 Table 程序的开发。这种场景下,用户可以使用 **StreamTableEnvironment** 或 **TableEnvironment** ,两者的区别是 StreamTableEnvironment 额外提供了与 DataStream API 交互的接口。 ```java val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) val settings: EnvironmentSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build() val oldStreamTableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env,settings) ``` #### 3.2 Old planner & Batch(基于老版本的批处理环境) 这种场景下,用户只能使用 BatchTableEnvironment ,因为在使用 Old planner 时,批处理程序操作的数据是 DataSet,只有 BatchTableEnvironment 提供了面向DataSet 的接口实现。 ```java val batchEnv = ExecutionEnvironment.getExecutionEnvironment val oldBatchTableEnv = BatchTableEnvironment.create(batchEnv) ``` #### 3.3 Blink planner & Stream(基于blink planner的流处理) 这种场景下,用户可以使用 **StreamTableEnvironment** 或 **TableEnvironment** ,两者的区别是 StreamTableEnvironment 额外提供与 DataStream API 交互的接口。 ```java val blinkStreamSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build() val blinkStreamTableEnv = StreamTableEnvironment.create(env,blinkStreamSettings) ``` #### 3.4 Blink planner & Batch(基于blink planner的批处理) 这种场景下,用户只能使用 **TableEnvironment** ,因为在使用 Blink planner 时,批处理程序操作的数据已经是 bounded DataStream,所以不能使用 BatchTableEnvironment 。 值得注意的是,TableEnvironment 接口的具体实现中已经支持了 StreamingMode 和 BatchMode 两种模式,而 StreamTableEnvironment 接口的具体实现中目前暂不支持 BatchMode 的配置,所以这种场景不能使用 StreamTableEnvironment。 ```java val blinkBatchSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build() val blinkBatchTableEnv = TableEnvironment.create(blinkBatchSettings) ``` ### 四、代码 + **创建TableEnvironment完整代码** ```java import org.apache.flink.api.scala.ExecutionEnvironment import org.apache.flink.streaming.api.scala._ import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment} import org.apache.flink.table.api.scala._ /** * @author lilinchao * @date 2022/2/18 * @description 1.0 **/ object TableApiDemo02 { def main(args: Array[String]): Unit = { //1 、创建环境 val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env) //1.1、基于老版本的planner的流处理 val settings: EnvironmentSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build() val oldStreamTableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env,settings) //1.2、基于老版本的批处理环境 val batchEnv = ExecutionEnvironment.getExecutionEnvironment val oldBatchTableEnv = BatchTableEnvironment.create(batchEnv) //1.3、基于blink planner的流处理 val blinkStreamSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build() val blinkStreamTableEnv = StreamTableEnvironment.create(env,blinkStreamSettings) //1.4、基于blink planner的批处理 val blinkBatchSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build() val blinkBatchTableEnv = TableEnvironment.create(blinkBatchSettings) } } ```
标签:
Flink
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1904.html
上一篇
01.Table API和Flink SQL介绍
下一篇
03.Flink SQL之在Catalog中注册表
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
DataWarehouse
Map
Netty
Redis
JVM
Eclipse
算法
并发编程
RSA加解密
排序
数学
Flume
Java工具类
gorm
Golang基础
Python
Beego
Yarn
Livy
nginx
随笔
Git
Docker
FileBeat
GET和POST
Zookeeper
NIO
设计模式
MyBatisX
Sentinel
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭