李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
35.Flink和Kafka实现端到端exactly-once语义详解
Leefs
2022-02-16 PM
1689℃
0条
[TOC] ### 一、概念 我们知道,端到端的状态一致性的实现,需要每一个组件都实现,对于 Flink + Kafka 的数据管道系统(Kafka 进、Kafka 出)而言,各组件怎样保证 exactly-once 语义呢? + **内部**:利用 checkpoint 机制,把状态存盘,发生故障的时候可以恢复, 保证内部的状态一致性; + **source**:kafka consumer 作为 source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据, 保证一致性; + **sink**:kafka producer 作为 sink,采用两阶段提交sink,需要实现一个TwoPhaseCommitSinkFunction ### 二、source和sink执行过程 我们知道Flink由JobManager协调各个TaskManager进行checkpoint存储,checkpoint保存在**StateBackend**中,默认**StateBackend**是内存级的,也可以改为文件级的进行持久化保存。 **本例中的Flink应用包含以下组件,如下图所示:** + 一个source,从Kafka中读取数据(即KafkaConsumer); + 一个时间窗口化(window)的聚会操作; + 一个sink,将结果写回到Kafka(即KafkaProducer) 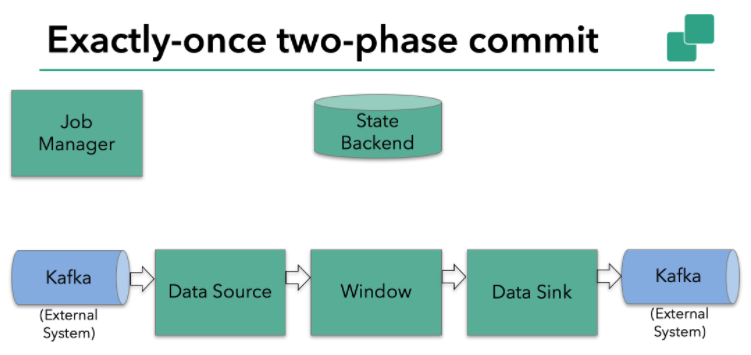 当 checkpoint 启动时,JobManager 会将检查点分界线(barrier)注入数据流; barrier s会在算子间传递下去。  每个算子会对当前的状态做个快照,保存到状态后端。对于 source 任务而言, 就会把当前的offset作为状态保存起来。下次从checkpoint恢复时,source任务可以重新提交偏移量,从上次保存的位置开始重新消费数据。  每个内部的transform任务遇到barrier时,都会把状态存到checkpoint里。 sink 任务首先把数据写入外部 kafka,这些数据都属于预提交的事务(还不能被消费);当遇到 barrier 时,把状态保存到状态后端,并开启新的预提交事务。  当所有算子任务的快照完成,也就是这次的 checkpoint 完成时,JobManager会向所有任务发通知,确认这次 checkpoint完成。 当 sink 任务收到确认通知,就会正式提交之前的事务,kafka 中未确认的数据就改为“已确认”,数据就真正可以被消费了。  所以我们看到,执行过程实际上是一个两段式提交,每个算子执行完成,会进 行“预提交”,直到执行完 sink 操作,会发起“确认提交”,如果执行失败,预提 交会放弃掉。 ### 三、总结 **具体的两阶段提交步骤总结如下:** + 第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”; + jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager; + sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据; + jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成; + sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据; + 外部 kafka 关闭事务,提交的数据可以正常消费了。 所以我们也可以看到,如果宕机需要通过 StateBackend 进行恢复,只能恢复所 有确认提交的操作。 *附参考文章来源:* *《尚硅谷大数据之flink教程》*
标签:
Flink
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1900.html
上一篇
34.Flink保存点(Savepoints)介绍
下一篇
01.Table API和Flink SQL介绍
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
MyBatis
Quartz
排序
ClickHouse
Redis
容器深入研究
Spark RDD
持有对象
随笔
Spark Streaming
SQL练习题
Jenkins
序列化和反序列化
Spark
哈希表
Http
Netty
Kibana
数据结构和算法
Java编程思想
工具
Java阻塞队列
Python
Flink
Livy
字符串
FastDFS
Hadoop
FileBeat
CentOS
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭