李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
07.HDFS之Fsimage和Edits详解
Leefs
2021-09-19 PM
2683℃
0条
[TOC] ### 前言 之前在文章[HDFS之NameNode和SecondaryNameNode](https://lilinchao.com/archives/1495.html)中简单介绍过Fsimage和EditLog,但是总结的还是有很多漏洞,小编又查阅一些资料在此进行一下补充。 ### 一、NameNode元数据 #### 1.1 概述 NameNode 的所有操作及整个集群的状态都存储在metadata(元数据)中,metadata通过 Fsimage 和 Eidts 文件保存。 **metadata作用是在集群启动时将集群的状态恢复到关闭前的状态**。 也就是 Hadoop集群因为各种原因需要重新启动,元数据能保证集群启动之后的状态和上次停止前的状态一致。 #### 1.2 数据恢复过程 + 第一次启动 NameNode 前的格式化(`hdfs namenode -format`)操作会创建 fsimage 和 edits 文件。 + 非第一次启动,NameNode 会进行数据恢复:首先把 fsimage 加载到内存中形成文件系统镜像,然后再把 edits 中 **fsimage_txid 之后的、所有事务** 回放到这个文件系统镜像上。这个时候,集群也就恢复到关闭前的状态了。 #### 1.3 配置 通过hdfs-site.xml文件可对Fsimage和Edits文件的位置进行配置 ```xml <!-- NameNode 元数据的存放目录 --> <property> <name>dfs.namenode.name.dir</name> <value>file:/Users/llc/data/hadoop/namenode</value> </property> <!-- NameNode 日志文件的存放目录 --> <property> <name>dfs.namenode.edits.dir</name> <value>file:/Users/llc/data/hadoop/namenode/edits</value </property> ``` ### 二、Fsimage和Edits介绍 #### 2.1 工作原理 + **Fsimage:**fsimage保存了最新的元数据检查点,在HDFS启动时加载fsimage的信息,包含了整个HDFS文件系统的所有目录和文件的信息; + **Edits:**edits主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到edits中 对于更新操作都会记录在edits中,为了避免edits不断增大,secondary namenode会周期性合并fsimage和edits成新的fsimage,新的操作记录会写入新的editlog中(合并过程后面会进行详细介绍)。 #### 2.2 文件介绍 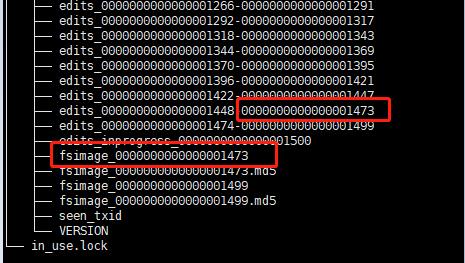 **说明** + edits文件以 edits_ 开头,后面跟一个txid范围段,并且多个edits之间首尾相连; + 正在使用的 edits 名字为 `edits_inprogress_txid`; + 会保存两个fsimage文件,文件格式为fsimage_txid; + fsimage文件和 edits 文件是通过`txid`来进行关联。 在启动HDFS时,只需要读入`fsimage_0000000000000001499`以及`edits_inprogress_0000000000000001500`就可以还原出当前hdfs的最新状况。 ### 三、CheckPoint机制 #### 3.1 作用 HDFS 的每个写操作都会写入 edits 中,如果集群规模非常庞大,操作又很频繁,随着时间的积累 edits 会变的很大,极端情况下会占满整个磁盘。 另外,由于 NameNode 在启动的时候,需要将 edits 中的操作重新执行一遍,过大的 edits 会延长 NameNode 的启动时间。 所以,**通过 CheckPoint 定期对元数据进行合并。** #### 3.2 fsimage和edits文件的合并过程  + 文件合并过程需要消耗io和cpu所以需要将这个过程独立出来,在Hadoop1.x中是由Secondnamenode来完成; + Secondnamenode必须启动在单独的一个节点最好不要和namenode在同一个节点,这样会增加namenode节点的负担,而且维护时也比较方便; + 在HA模式下,checkpoint 则由 StandBy 状态的 NameNode 来进行。 ##### checkpoint合并条件 + `dfs.namenode.checkpoint.preiod`(默认值是3600,即1小时),period参数表示,经过1小时就进行一次checkpoint + `dfs.namenode.checkpoint.txns`(默认值是1000000)来决定,txns参数表示,hdfs经过100万次操作后就要进行checkpoint了。 这两个参数任意一个得到满足,都会触发checkpoint过程。 进行 checkpoint 的节点每隔 `dfs.namenode.checkpoint.check.period`(默认值是60)秒就会去统计一次hdfs的操作次数 #### 3.3 HA模式下Checkpoint 过程  **说明** 1. StandBy NameNode 检查是否达到 checkpoint 条件:离上一次checkpoint操作是否已经有一个小时,或者HDFS已经进行了100万次操作。 2. StandBy NameNode 检查达到 checkpoint 条件后,将该 namespace 以fsimage.ckpt_txid 格式保存到 StandBy NameNode 的磁盘上,并且随之生成一个MD5文件。然后将该fsimage.ckpt_txid文件重命名为fsimage_txid。 3. StandBy NameNode 通过HTTP联系 Active NameNode。 4. Active NameNode 通过HTTP从 StandBy NameNode 获取最新的fsimage_txid文件并保存为fsimage.ckpt_txid,然后也生成一个MD5,将这个MD5与SBNN的MD5文件进行比较,确认ANN已经正确获取到了SBNN最新的fsimage文件。然后将fsimage.ckpt_txid文件重命名为fsimage_txit。 5. 通过上面一系列的操作,StandBy NameNode 上最新的 FSImage 文件就成功同步到了 Active NameNode 上。 *附参考文章链接:* *https://www.cnblogs.com/shoufeng/p/14855242.html*
标签:
Hadoop
,
HDFS
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1503.html
上一篇
06.HDFS之DataNode介绍
下一篇
08.HDFS文件目录介绍
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
算法
二叉树
Linux
Nacos
散列
稀疏数组
JavaWEB项目搭建
数据结构
前端
Spark RDD
Git
Sentinel
SpringCloudAlibaba
Spark Streaming
链表
Kafka
Netty
设计模式
NIO
Spark
nginx
Jquery
JVM
Hive
Hbase
容器深入研究
Kibana
Jenkins
Yarn
锁
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭