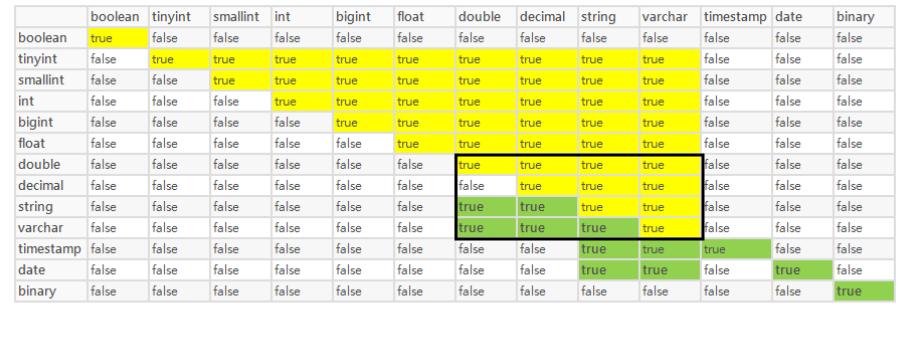
18.Hive正则表达式详解
[TOC]前言当真正使用Hive处理数据的时候,往往需要使用正则表达式来对数据做一些过滤操作,本篇将通过一些示例介绍一下Hive中的正则表达式的使用。一、正则匹配LIKE语法A LIKE B操作类型: strings返回类型: boolean或null描述如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合表达式B的正则语法,则为TRUE,否则为FALSE;B中字符"_"表示...
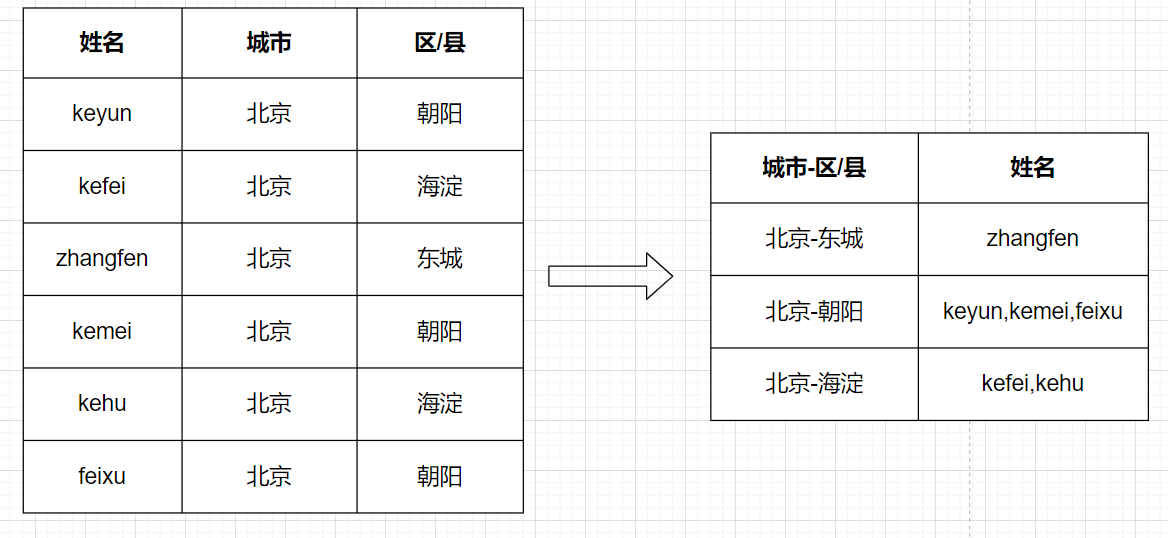
17.Hive行转列和列转行
[TOC]一、行转列1.1 相关函数concatconcat(string A, string B…):用于拼接字符串,返回输入字符串连接后的结果,支持任意个输入字符串concat_wsconcat_ws(string SEP, string A, string B…):与concat类似,返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符;concat_ws(string SEP,...
16.Hive常用内置函数示例
[TOC]一、字符函数示例1.1字符串反转函数语法:reverse(string A)说明:返回字符串A的反转结果0: jdbc:hive2://hadoop001:10000> select reverse("abcdef"); +---------+ | _c0 | +---------+ | fedcba | +---------+1.2 字符串连接...
15.Hive常用内置函数总结
[TOC]一、查询系统内置函数1.1 查看系统自带的函数show functions;1.2 显示自带的函数的用法语法desc function 【函数名称】;-- 查询upper函数用法 0: jdbc:hive2://hadoop001:10000> desc function upper; -- 运行结果 +-----------------------------------...
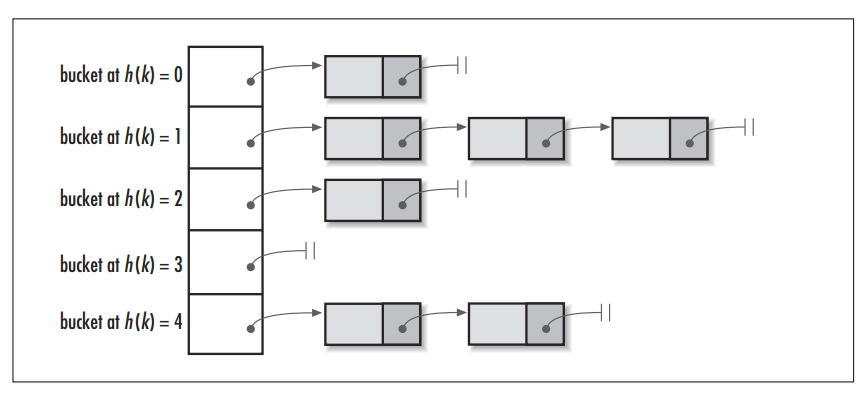
14.Hive分桶表详细介绍
[TOC]一、概述1.1 简介 分区提供了一个隔离数据和优化查询的可行方案,但是并非所有的数据集都可以形成合理的分区,分区的数量也不是越多越好,过多的分区条件可能会导致很多分区上没有数据。 同时Hive会限制动态分区可以创建的最大分区数,用来避免过多分区文件对文件系统产生负担。 鉴于以上原因,Hive还提供了一种更加细粒度的数据拆分方案:分桶表...
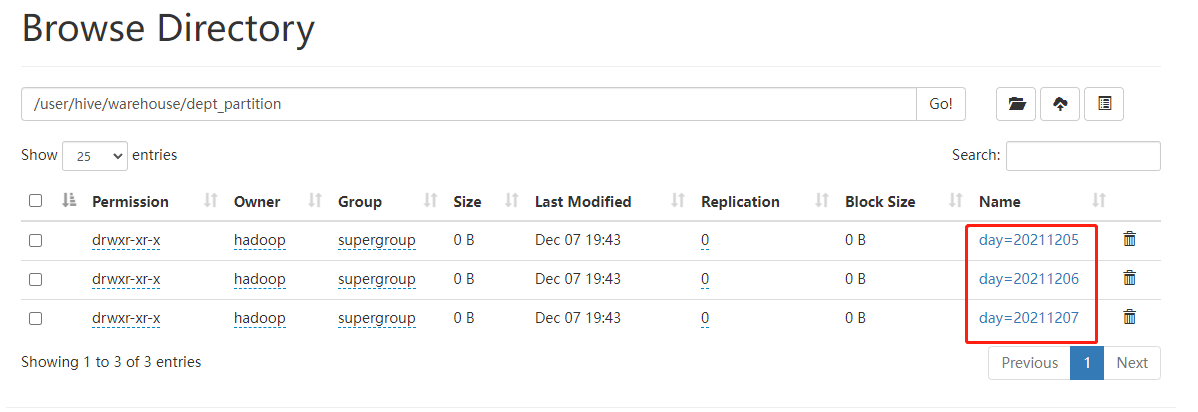
13.Hive分区表详细介绍
[TOC]一、概念简介Hive 中的表对应为HDFS上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大。分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。意...
12.Hive经典练习题
[TOC]前言对于Hive的基础查询操作,因为和其它SQL语句都大同小异,将不在进行详细介绍,小编在网上找了一些Hive查询的练习题,大家可以通过这些练习来更加熟练的掌握Hive的基础查询操作。原文地址:hive 50道经典练习本篇将通过beeline 客户端来运行Hive命令,如果没安装的可参考如下文章:06.使用JDBC方式访问Hive一、数据准备学生表(student)学号(sid)学...

11.Hive DML数据操作
[TOC]前言本篇讲述通过Hive命令实现对数据的导出和导入操作。一、数据导入1.1 向表中装载数据(Load)语法load data [local] inpath 'datapath' [overwrite] into table dbname [partition (partcol1=val1,…)]参数说明load data加载数据local从本地加载数据到hive表;如果不加loc...
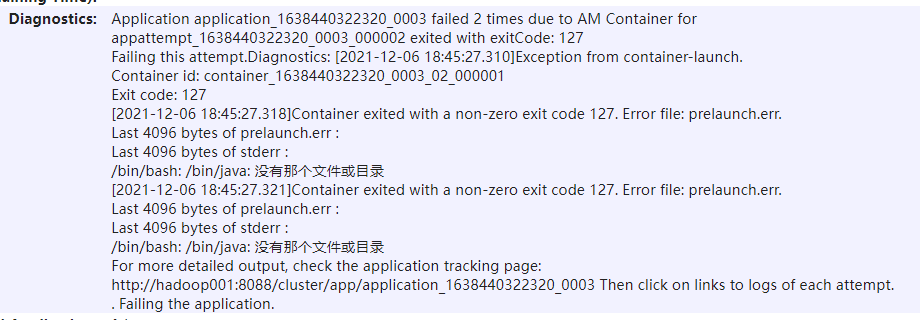
10.Hive DDL数据定义
[TOC]前言本篇讲述Hive语句中对数据库和数据表的操作。一、数据库操作语句1.1 创建数据库语法结构:CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] //关于数据块的描述 [LOCATION hdfs_path] //指定数据库...