Spark运行架构
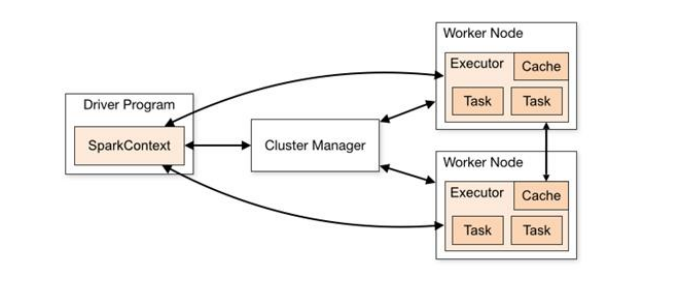
11.Spark运行架构一、运行架构Spark框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。 如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。二、核心组件由上图可以看出,对于 Spark 框架有两个核心组件...
Spark Standalone模式搭建
10.Spark Standalone模式搭建前言搭建 Spark 集群前,需要保证 JDK 环境、Zookeeper 集群和 Hadoop 集群已经搭建,相关步骤可以参阅:Zookeeper集群环境搭建Hadoop集群环境搭建一、集群介绍这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Maste...

Zookeeper集群环境搭建
09.Zookeeper集群环境搭建前言本次安装Zookeeper集群是为Spark Standalone集群搭建做准备工作。为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里演示搭建一个三个节点的集群。这里我使用三台主机进行搭建,主机名分别为 hadoop001,hadoop002,hadoop003。一、安装步骤1. 下载下载对应版本 Zookeepe...
CentOS7安装Hadoop3.2集群
08.CentOS7安装Hadoop3.2集群前言虚拟机网络配置通过ip addr命令未查询到虚拟机IP地址1、修改网络配置[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-eno16777736将ONBOOT=no改为ONBOOT=yesONBOOT的意思是,开机时是否启动2、重启网络服务[root@localhost ...
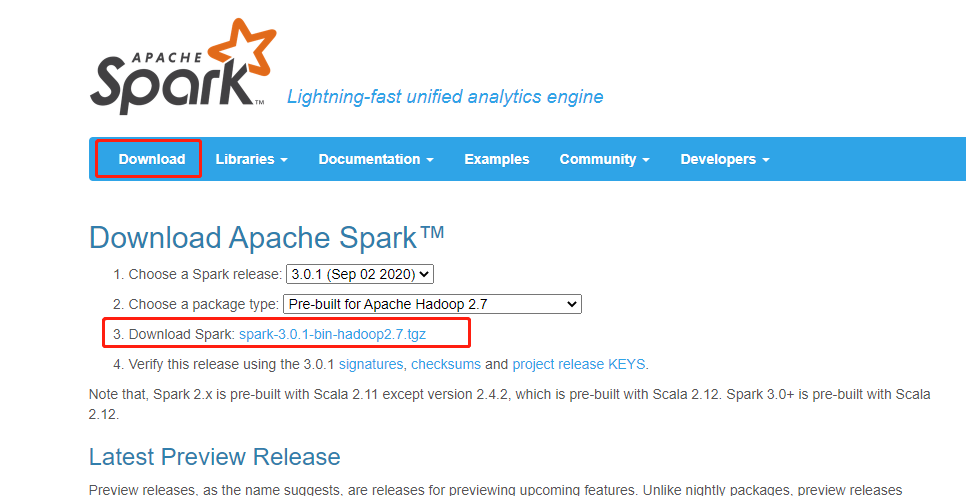
CentOS7 Spark Local模式搭建
07.CentOS7 Spark Local模式搭建前言需要提前准备的环境JDK1.8Hadoop 2.8.5(小编安装的Hadoop环境)系统版本Centos7本次搭建的Spark版本为3.0.1。一、Spark Local环境搭建下载访问官网:http://spark.apache.org/ 点击Download下载最新版本。 下载spark其实是跟hadoop包对应的,但是我看官...

【转载】Spark部署模式介绍
【转载】06.Spark部署模式介绍前言目前Apache Spark支持三种分布式部署方式,分别是standalone、spark on mesos和 spark on YARN,其中,第一种类似于MapReduce 1.0所采用的模式,内部实现了容错性和资源管理,后两种则是未来发展的趋势,部分容错性和资源管理交由统一的资源管理系统完成:让Spark运行在一个通用的资源管理系统之上,这样可以...
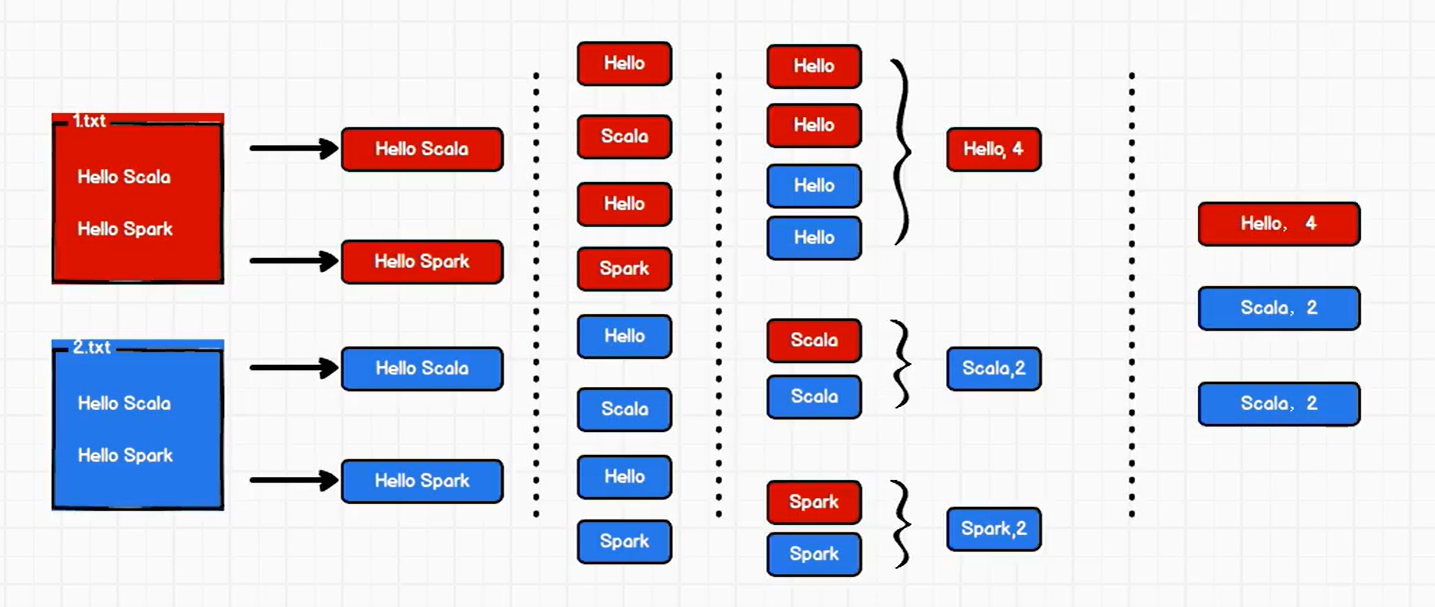
Spark入门程序WordCount
05.Spark入门程序WordCount一、问题描述描述:编写一个Spark应用程序,对1.txt和2.txt文件中的单词进行词频统计通过Spark core进行实现二、方法一1. 思路整行读取1.txt和2.txt文件中所有内容将整行数据拆分,形成一个个单词根据单词进行分组,将相同的单词放在一组当中,方便统计对分组后的数据进行转换将转换结果输出2. 代码实现流程建立和Spark框架的连接...
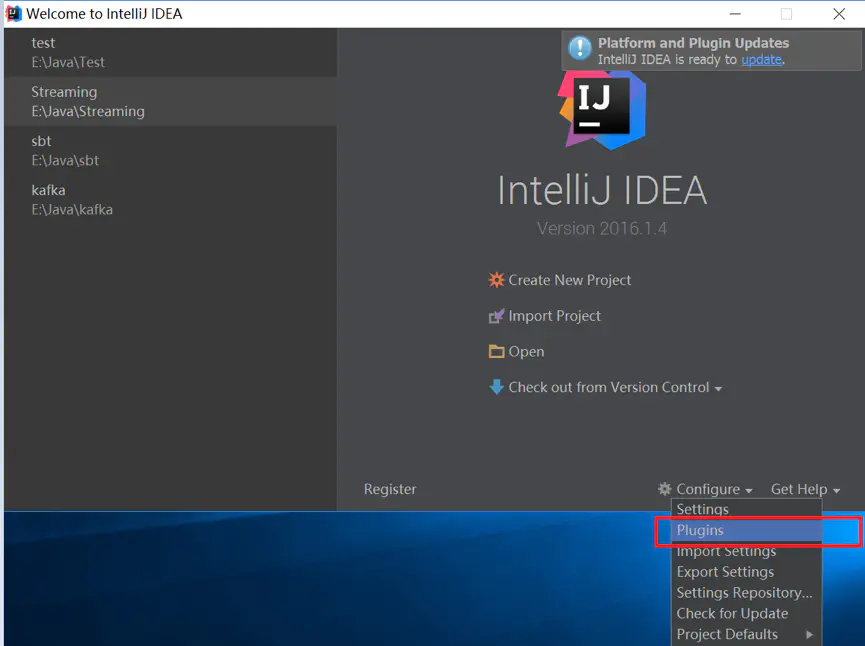
基于IDEA构建spark开发环境
04.基于IDEA构建spark开发环境前言开发环境:1.IDEA版本2018.3.42.JDK版本1.83.Scala版本2.12.11一、IDEA安装Scala插件(1)点击右下角configuration,选择plugins(2)选择Browse repositories(3)输入Scala后搜索,然后安装,安装需要一些时间如果通过install自动下载插件失败,可以选择手动下载sca...

windows10 scala安装
03.windows10 scala安装前言已经安装成功JDK1.8,本次安装的scala版本为2.12.11一、下载下载地址:https://www.scala-lang.org/download/all.html2.下载windows安装版的scala二、scala安装1. 接受协议,下一步2. 选择安装的路径3.进行安装即可三、环境变量配置1、此电脑-->右击选择属性进行环境变量...