李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
基于IDEA构建spark开发环境
Leefs
2021-02-21 PM
1812℃
0条
# 04.基于IDEA构建spark开发环境 ### 前言 开发环境: 1.IDEA版本2018.3.4 2.JDK版本1.8 3.Scala版本2.12.11 ### 一、IDEA安装Scala插件 (1)点击右下角configuration,选择plugins 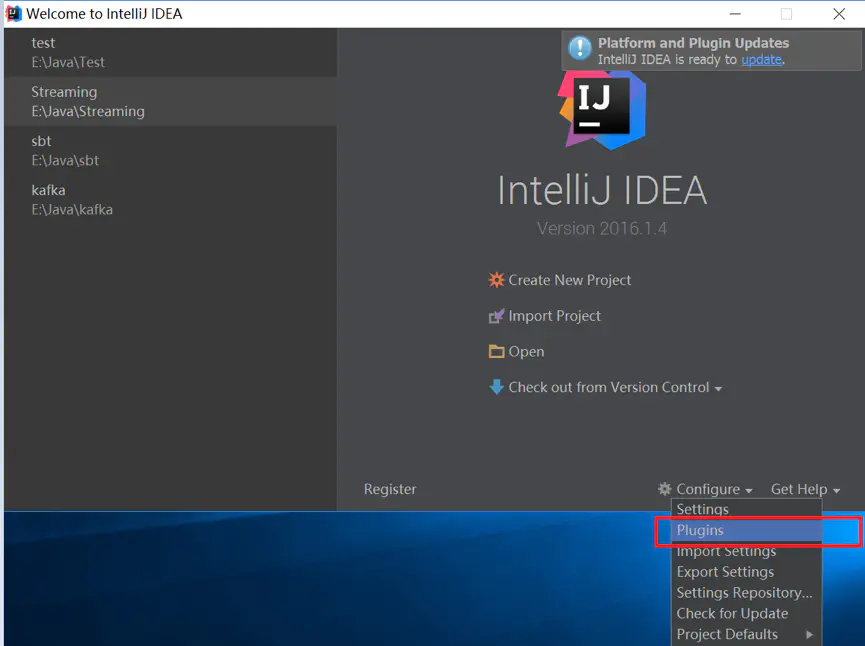 (2)选择Browse repositories  (3)输入Scala后搜索,然后安装,安装需要一些时间 如果通过install自动下载插件失败,可以选择手动下载scala插件,然后通过步骤2中【install plugin from disk】选项,选择手动下载zip包的方式安装插件 ### 二、创建Maven项目 1. 点击File-->New-->Project  2. Maven --> 选择JDK版本 --> Next  3. 命名GroupId和ArtifactId + GroupId是项目所属组织的唯一标识 + ArtifactId是项目的唯一标识,也是项目根目录的名称  4. 选择Project location路径 --> 点击Finish  完成后的目录结构  ### 三、新增scala文件夹 此时源码src目录下面默认是有java文件夹,可以看到颜色还不一样,表示是源码文件,我们需要新增scala文件夹,并且变成源码文件夹。 1. 打开项目设置 File -> Project Structure 或者快捷键Ctrl +Alt +Shift + S  2.选择【Modules】--> 【Sources】--> 【Resources】--> 【main】--> 右击显示【New Folder】  3.输入框填写scala --> 点击OK  4. 此时新建的文件夹还不是源码文件夹,需要选择scala文件夹,点击Source,变成源码文件夹  点击OK ### 四、新建Scala class文件 1. 此时在项目中新建源码文件,会显示如下  会发现列表中没有Scala Class,因为项目中还没有添加Scala SDK 2. 在Project Structure(或者快捷键Ctrl +Alt +Shift + S)中选择Libraries,点击“+”,新增Scala SDK  3. 点击Browse选择自己本地Scala安装路径   加载完Scala SDK之后  4. 新建scala源码 选中scala --> New --> Scala Class  5. 填写class名称,Kind选择【Object】,点击OK  ### 五、运行 1. 在刚创建的demo.scala下填充如下内容 ```scala import org.apache.spark.sql.SparkSession import java.io.File object demo { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .master("local[*]") .appName("Spark SparkSession basic example") .getOrCreate() val peopleDFCsv = spark.read.format("csv") .option("sep", "\t") .option("header", "false") .load("D:\\path\\T.csv") peopleDFCsv.printSchema() peopleDFCsv.show(10) // val a = new File("./data").listFiles() // a.foreach(file => println(file.getPath)) } } ``` 效果如下:  会发现无法识别SparkSession,是因为Spark相关程序依赖没有加入进来。 2.pom.xml中加入如下依赖 ```xml <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.0.0</version> </dependency> ``` 3.运行demo.scala 等待输出结果 ### 六、运行异常解决 如果代码中没有设置master ```scala val spark = SparkSession .builder() .appName("Spark SQL basic example") .getOrCreate() ``` 会有如下错误 ``` ERROR SparkContext: Error initializing SparkContext. org.apache.spark.SparkException: A master URL must be set in your configuration at org.apache.spark.SparkContext.<init>(SparkContext.scala:379) at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2320) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:868) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:860) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:860) at Demo$.main(Demo.scala:10) at Demo.main(Demo.scala) Exception in thread "main" org.apache.spark.SparkException: A master URL must be set in your configuration at org.apache.spark.SparkContext.<init>(SparkContext.scala:379) at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2320) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:868) at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:860) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:860) at Demo$.main(Demo.scala:10) at Demo.main(Demo.scala) ``` 有两种解决方案,第一种 ```scala val spark = SparkSession .builder() .master("local[*]") // 使用所有线程 .appName("Spark SQL basic example") .getOrCreate() ``` 第二种,在运行参数中设置  在VM options中设置-Dspark.master=local 
标签:
Spark
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1192.html
上一篇
windows10 scala安装
下一篇
Spark入门程序WordCount
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
栈
Eclipse
Kibana
FastDFS
Hadoop
DataX
Http
队列
机器学习
Docker
高并发
Spark Core
Flume
pytorch
Java阻塞队列
Flink
DataWarehouse
数据结构
Beego
Python
排序
VUE
JavaWeb
序列化和反序列化
散列
JVM
ClickHouse
SpringCloud
Tomcat
国产数据库改造
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭