李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
02.Hive架构原理
Leefs
2021-11-27 PM
1186℃
0条
[TOC] ### 前言 本篇Hive架构原理在来回顾一下Hive的本质。 **Hive本质:**是将HQL语句转化成MapReduce程序。 在它的底层: + HDFS负责存储数据; + YARN负责进行资源管理; + MapReduce负责数据处理。 ### 一、Hive架构 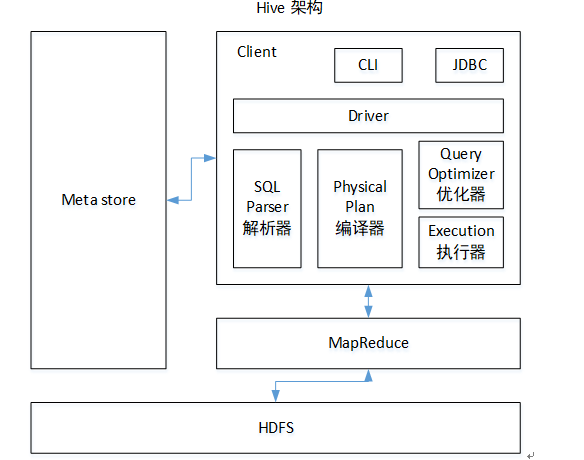 **说明** + **用户接口:Client** CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive) + **元数据:Metastore** 元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、 表的类型(是否是外部表)、表的数据所在目录等; 默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore + **驱动器:Driver** (1)**解析器(SQL Parser):**将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。 (2)**编译器(Physical Plan):**将 AST 编译生成逻辑执行计划。 (3)**优化器(Query Optimizer):**对逻辑执行计划进行优化。 (4)**执行器(Execution):**把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是 MR/Spark。 + **MapReduce** 使用 MapReduce进行计算。 + **HDFS** **通过HDFS 进行存储**,Hive本身不存储数据,Hive虽有表的定义但表是纯的逻辑表,数据是存在HDFS上的。hive中的内容不支持改写和删除,适合读多写少的场景。 **执行过程** (1)通过Hive提供的一系列交互接口(Client),向Hive提交SQL指令(HSQL) + **如果提交的是创建表的DDL语句(数据定义语言):**Hive会通过使用自己的执行引擎(Driver)将数据表的信息记录在Metastore元数据组件中。 正如上面提到的,元数据组件通常用一个关系型数据库实现,其记录着表名,字段名,字段类型以及关联的HDFS文件路径等元信息 + **如果提交的是DQL语句(数据查询分析语句):**Hive的执行引擎(Drive)会结合元数据信息对该语句进行转换,语法分析,语法优化等操作,最后生成一个MapReduce执行计划。 Hive执行引擎(Drive)会将该语句提交给自己的解析器(SQL Parser),解析器接收到语句之后,会将SQL查询字符串转换成抽象语法树,并对抽象语法树进行语法分析,比如检测表是否存在,字段是否存在,SQL语义是否有误等,之后将经过语法分析后的抽象语法树提交给编译器。 (2)编译器将抽象语法树编程成逻辑执行计划(Physical Plan) (3)执行器(Execution)将逻辑执行计划转换成可以运行的物理计划 (4)根据执行计划生成一个MapReduce的作业,提交到Yarn上执行 (5)将执行返回的结果输出到用户交互接口 **总结** Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。 ### 二、Hive运行机制  **执行步骤:** (1)用户提交查询等任务给Driver; (2)编译器获得该用户的任务Plan; (3)编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息; (4)编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略; (5)将最终的计划提交给Driver; (6)Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作; (7)获取执行的结果; (8)取得并返回执行结果; *附参考文章链接:* *《尚硅谷大数据技术之Hive》* *https://www.jianshu.com/p/0b9e1d3cf247*
标签:
Hadoop
,
Hive
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1656.html
上一篇
01.Hive基本概念
下一篇
03.Hive和数据库比较
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Spark SQL
Shiro
Tomcat
持有对象
Flink
MyBatisX
Java阻塞队列
Http
查找
锁
Nacos
散列
微服务
递归
Spark RDD
随笔
Thymeleaf
栈
Netty
Git
JavaWeb
Docker
MyBatis-Plus
Golang基础
Flume
前端
Java工具类
Quartz
Typora
Hive
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭