李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
01.Hive基本概念
Leefs
2021-11-27 PM
1299℃
0条
[TOC] ### 一、Hive简介 + 最初,Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下Apache Hive为一个开源项目。 + Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。 + Hive数据仓库工具能**将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行**。 + Hive定义了简单的类SQL查询语言,称为 **HiveQL**,它允许熟悉 SQL的用户查询数据。 官网地址:https://hive.apache.org/ ### 二、Hive本质 **HQL转换MP流程** 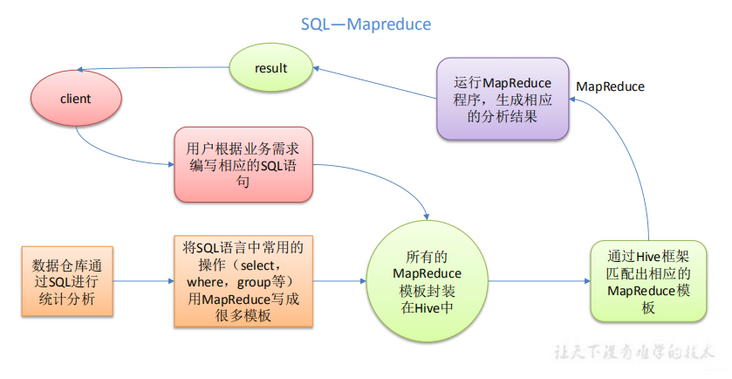 **说明** + Hive本质是将HQL转换为MapReduce程序 + sql分析 -> 将sql封装成为MapReduce模板 -> 通过hive框架匹配相应的模板 + 执行**程序运行在yarn**上 + Hive 处理的数据存储在HDFS + 简单的说hive就是hdfs的简单一种映射 + 比如:hive的一张表映射hdfs上的一个文件,hive的一个数据库就映射为hdfs上的文件夹 + Hive分析数据底层默认实现是MapReduce,可以手动修改为spark + Hive相当于Hadoop的一个客户端 + Hive不是分布式 ### 三、Hive使用场景 + Hive构建在基于静态批处理的Hadoop之上,Hadoop通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive在几百MB的数据集上执行查询一般有分钟级的时间延迟。 + Hive查询操作过程严格遵守Hadoop MapReduce的作业执行模型,Hive将用户的HiveQL语句通过解释器转换为MapReduce作业提交到Hadoop集群上,Hadoop监控作业执行过程,然后返回作业执行结果给用户。 + Hive的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。 ### 四、Hive优缺点 #### 4.1 优点 (1)操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。 (2)避免了去写MapReduce,减少开发人员的学习成本。 (3)Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。 (4)Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。 (5)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。 #### 4.2 缺点 (1)**Hive 的 HQL 表达能力有限** + 迭代式算法无法表达 + 数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。 (2)**Hive 的效率比较低** + Hive自动生成的 MapReduce 作业,通常情况下不够智能化 + Hive调优比较困难,粒度较粗 ### 总结 在大数据应用场景下,Hive更多是作为Hadoop的一个数据仓库工具,并不直接存储数据,但是却不可或缺。 *附文章来源:* *参考《尚硅谷大数据技术之Hive》*
标签:
Hadoop
,
Hive
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1653.html
上一篇
MySQL高级应用窗口函数(四)
下一篇
02.Hive架构原理
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Redis
正则表达式
JavaWEB项目搭建
Flink
SpringBoot
持有对象
字符串
SQL练习题
Java阻塞队列
Azkaban
GET和POST
高并发
工具
Spark Streaming
Yarn
Elasticsearch
二叉树
JavaSE
随笔
Java工具类
Jenkins
Spark
nginx
SpringCloudAlibaba
锁
FileBeat
Ubuntu
MySQL
Jquery
Git
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭