李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
Hbase存储结构
Leefs
2021-02-12 PM
2974℃
0条
# 03.Hbase存储结构 ### 一、HBase逻辑结构 先从一个逻辑结构模型图开始看起: 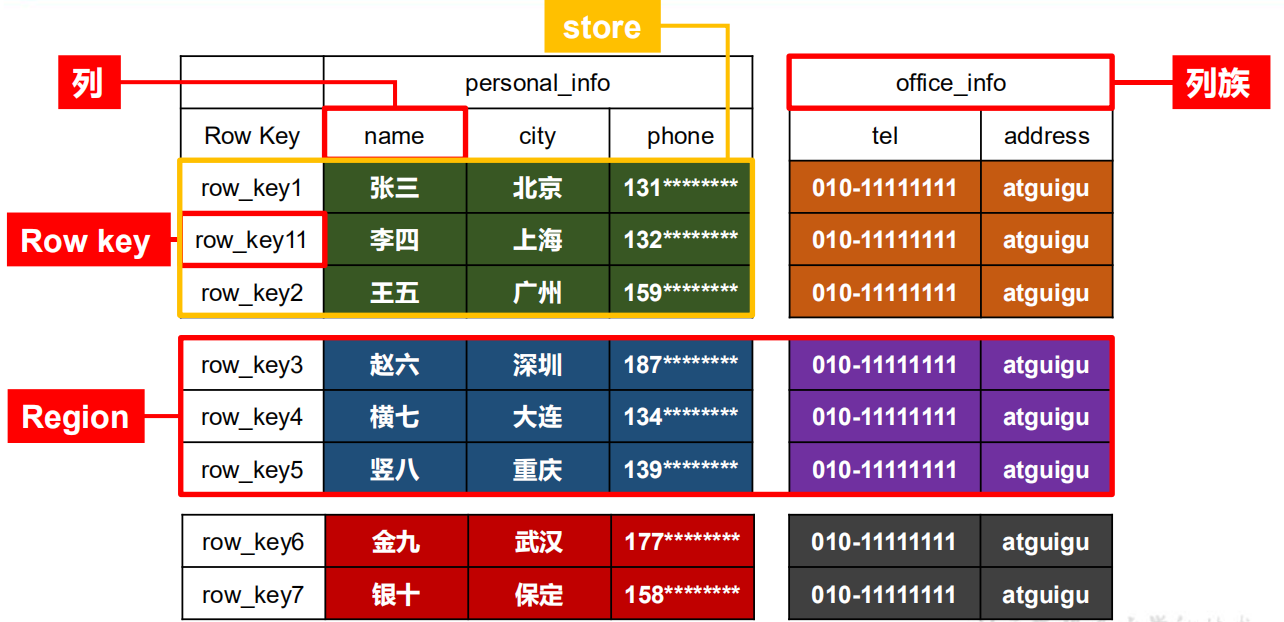 + **Table(表):**一个表由一个或者多个列族构成。。数据的属性。比如:name、age、TTL(超时时间)等等都在列族里边定义。定义完列族的表是个空表,只有添加了数据行以后,表才有数据。 + **Column Family(列族):**在HBase里,可以将多个列组合成一个列族。建表的时候不用创建列,因为列是可增减变化的,非常灵活。唯一需要确定的就是列族,也就是说一个表有几个列族是一开始就定好的。此外表的很多属性,比如数据过期时间、数据块缓存以及是否使用压缩等都是定义在列族上的,而不是定义在表上或者列上。这一点与以往的关系型数据库有很大的差别。列族存在的意义是:HBase会把相同列族的列尽量放在同一台机器上,所以说想把某几个列放在一台服务器上,只需要给他们定义相同的列族。 + **Row(行):**一个行包含多个列,这些列通过列族来分类。行中的数据所属的列族从该表所定义的列族中选取,不能选择这个表中不存在的列族。由于HBase是一个面向列存储的数据库,所以一个行中的数据可以分布在不同的服务器上。 + **RowKey(行键):**rowkey和MySQL数据库的主键比起来简单很多,rowkey必须要有,如果用户不指定的话,会有默认的。rowkey完全是由用户指定的一串不重复的字符串,另外,rowkey按照字典序排序。**一个rowkey对应的是一行数据** + **Region:**Region就是一段数据的集合。之前提到过高表的概念,把高表进行水平切分,假设分成两部分,那么这就形成了两个Region。 注意一下Region的几个特性: - Region不能跨服务器,一个RegionServer可以有多个Region。 - 数据量小的时候,一个Region可以存储所有的数据;但是当数据量大的时候,HBase会拆分Region。 - 当HBase在进行负载均衡的时候,也有可能从一台RegionServer上把Region移动到另一服务器的RegionServer上。 - Region是基于HDFS的,它的所有数据存取操作都是调用HDFS客户端完成的。 + **RegionServer:**RegionServer就是存放Region的容器,直观上说就是服务器上的一个服务,负责管理维护Region。 ### 二、物理存储结构 以上是一个基本的逻辑结构,底层的物理存储结构才是重中之重的内容,看下图,并且将尝试换个角度解释上边的几个概念:  具体来说: + **NameSpace:**命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default 表是用户默认使用的命名空间。 + **Row:**HBase 表中的每行数据都由一个 **RowKey** 和多个 **Column**(列)组成,数据是按照 RowKey 的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。 + **Column:**列,HBase 中的每个列都由 **Column Family(列族)**和 **Column Qualifier(列限定符)**进行限 定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。 + **TimeStamp:**时间戳,时间戳,用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入 HBase 的时间。 + **Cell:**单元格,由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮。 ### 三、HBase与关系型数据库的对比 传统关系型数据库的表结构图如下:  其中每行都是不可分割的,也正是体现了数据库第一范式的原子性,也就是说三个列必须在一起,而且要被存储在同一台服务器上,甚至是同一个文件里面。 HBase的表架构如图所示:  HBase的每一个行都是离散的,因为列族的存在,所以一个行里不同的列甚至被分配到了不同的服务器上。行的概念被减弱到了一个抽象的存在。在实体上,把多个列定义为一个行的关键词rowkey,也就是行这个概念在HBase中的唯一体现。 HBase的存储语句中必须精确的写出要将数据存放到哪个单元格,单元格由表:列族:行:列来唯一确定。需要写清楚数据要被存储在哪个表的哪个列族的哪个行的哪个列。如果一行有10列,那么存储一行的数据就需要写明10行的语句。 *附:* [参考文章链接](https://www.cnblogs.com/simon-1024/archive/2004/01/13/12161970.html)
标签:
Hbase
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1115.html
上一篇
Hbase架构
下一篇
CentOS7 Hadoop安装教程
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
正则表达式
人工智能
Spark Streaming
Kafka
Git
前端
序列化和反序列化
Filter
持有对象
gorm
Elastisearch
并发编程
Jquery
Flume
容器深入研究
Java
Spring
LeetCode刷题
锁
Ubuntu
JavaSE
RSA加解密
Java工具类
JVM
Sentinel
JavaWEB项目搭建
栈
Spark SQL
数据结构和算法
二叉树
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭