SparkCore之广播变量
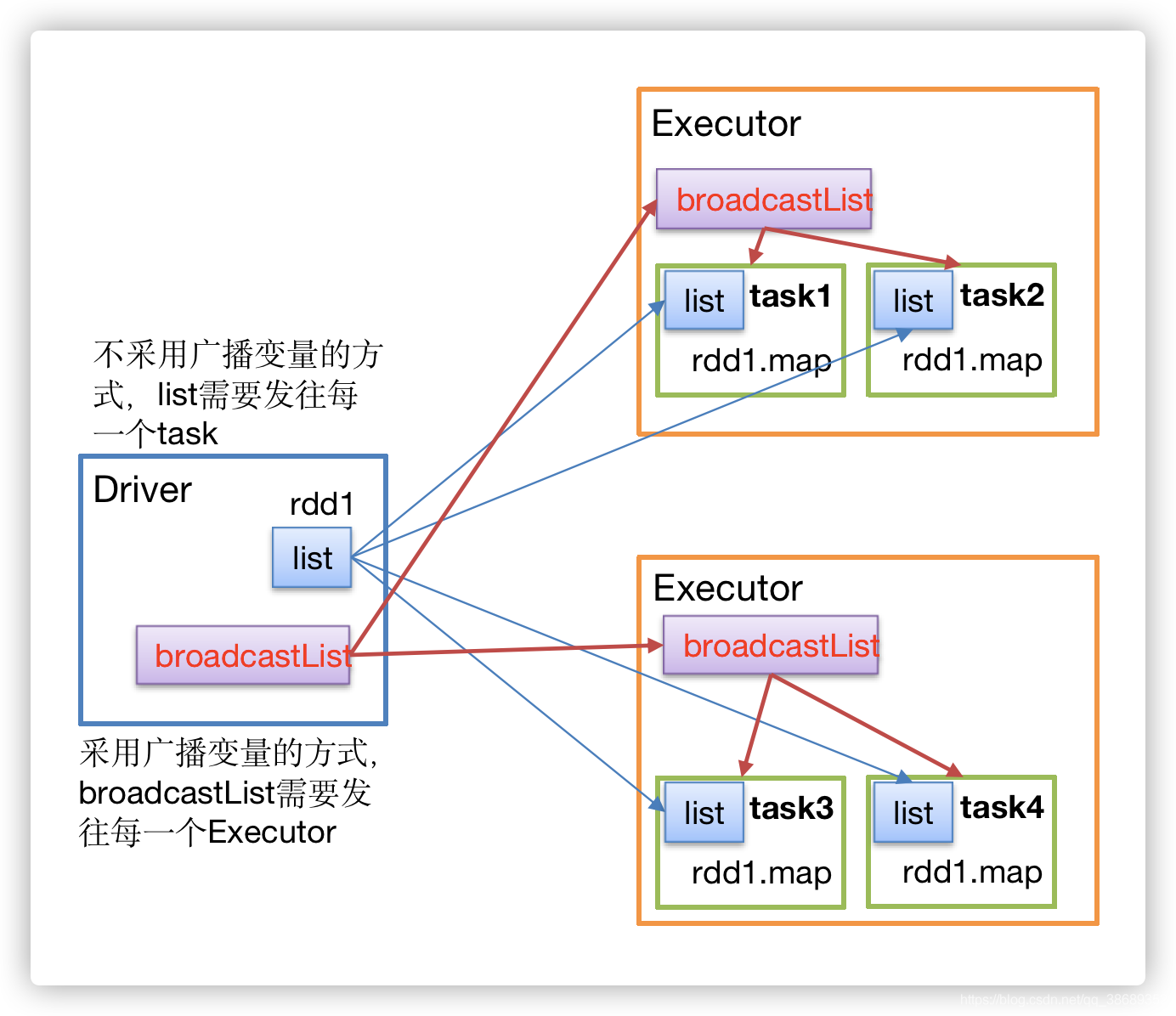
[TOC]一、定义广播变量:分布式共享只读变量二、作用在多个并行操作中(Executor)使用同一个变量,Spark默认会为每个任务(Task)分别发送,这样如果共享比较大的对象,会占用很大工作节点的内存。广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很...
SparkCore之累加器
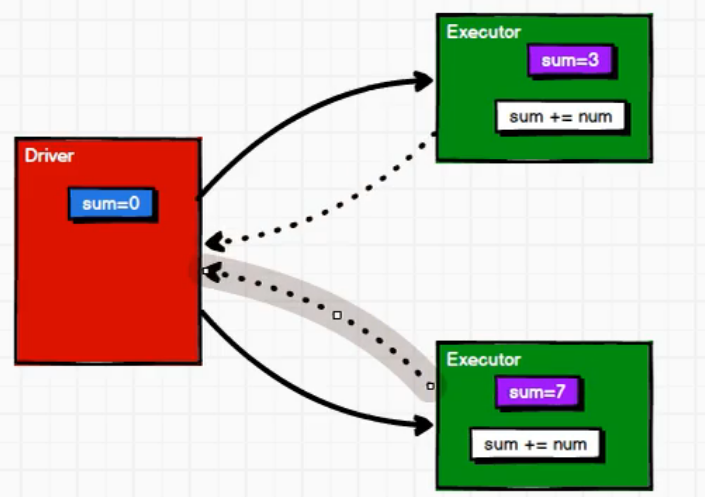
[TOC]前言本篇将先从一个案例入手,对Driver端和Executer端执行过程进行一个简单了解,在深入讲解累加器。一、累加操作案例案例需求将1,2,3,4进行累加求和操作代码import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @author lilinchao...

Spark Core案例实操(十)
[TOC]一、需求影评分析:按照年份进行分组。计算每部电影的平均评分,平均评分保留小数点后一位,并按评分大小进行排序。评分一样,按照电影名排序。相同年份的输出到一个文件中。结果展示形式(年份,电影id,电影名字,平均评分)要求:尝试使用自定义分区、自定义排序和缓冲。二、数据说明说明:以::对数据进行分隔movies.dat电影列表文件第一列:电影ID第二列:电影名称第三列:电影类型ratin...

Spark Core案例实操(九)
一、需求分析CDN日志统计出访问PV、UV、IP地址:计算独立ip数统计每个视频独立ip数统计一天中每个小时的流量(统计每天24小时中每个小时的流量)说明PV(page view): 页面浏览量,页面点击率;通常衡量一个网站或者新闻频道一条新闻的指标;UV(unique visitor ): 指访问某个站点或者点击某条新闻的不同的ip的人数二、数据说明100.79.121.48 HIT 33...

Spark Core案例实操(八)
[TOC]一、需求基站停留时间TOPN:根据用户产生的日志信息,分析在哪个基站停留的时间最长在一定范围内,求所有用户经过的所有基站所停留时间最长的TOP2二、数据说明19735E1C66.log:存储的日志信息第一列:手机号码第二列:时间戳第三列:基站ID第四列:连接状态(1连接,0断开)lac_info.txt:存储基站信息第一列:基站id第二列:经度第三列:纬度三、实现3.1 实现步骤1...

Spark Core案例实操(七)
[TOC]一、需求根据访问日志的ip地址做如下操作:计算出访问者的归属地按照省份,计算出访问次数将计算好的结果输出到控制台二、数据分析access.log日志文件第一列:ID第二列:访问者IP第三列:访问网址后面没用到就不详细介绍了ip.txtIP规则文件第一列和第二列:开始IP和结束IP(一个范围)第三列和第四列:开始IP和结束IP十进制第五、六、七、八列:对应地区分别是洲、国家、省/直辖...

Spark Core案例实操(六)
[TOC]一、HanLP介绍HanLP中文分词,面向生产环境的自然语言处理工具包,HandLP是由一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环境中的应用。官方网址:http://www.hanlp.com/添加Maven依赖<dependency> <groupId>com.hankcs</groupId> <...
Spark Core案例实操(五)
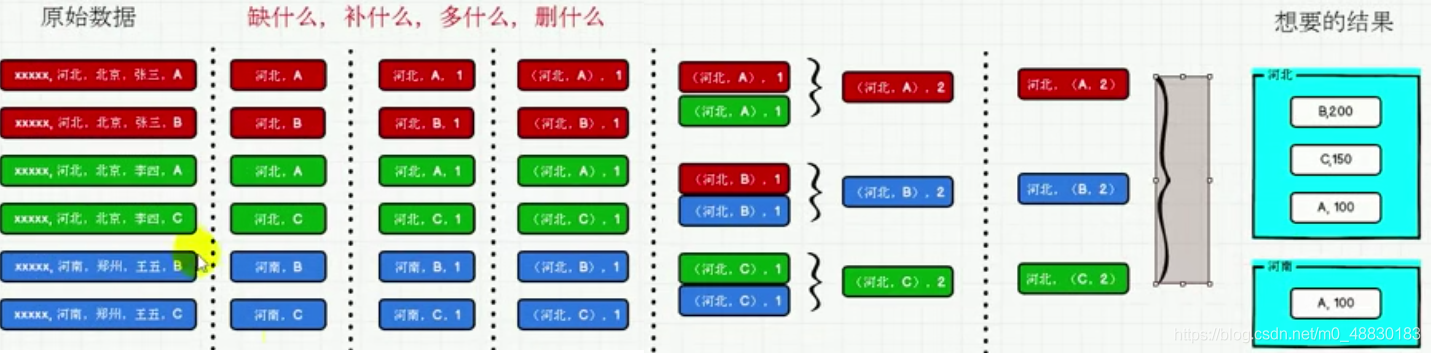
一、准备数据准备agent.log:时间戳,省份,城市,用户,广告,中间字段使用空格分隔。需求描述统计出每一个省份每个广告被点击数量排行的Top3需求分析二、实现2.1 步骤1.获取原始数据 2.将原始数据进行结构的转换,方便统计 3.将转换后的数据进行分组聚合 4.将聚合的结果进行结构中转换 5.将转换结构后的数据根据省份进行分组 6.将分组后的数据组内排序(降序),取前3名 7.采集的数...

Spark Core案例实操(四)
一、需求页面单跳转换率统计需求说明计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session 过程中 访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳, 那么单跳转化率就是要统计页面点击的概率。比如:计算 3-5 的单跳转化率,先获取符合条件的 Session 对于页面 3 的访问次数(PV) 为 A,然后获取符合条件...