李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
Spark Core案例实操(五)
Leefs
2021-11-01 AM
1470℃
0条
### 一、准备 + **数据准备** **agent.log**:时间戳,省份,城市,用户,广告,中间字段使用空格分隔。 + **需求描述** 统计出每一个省份每个广告被点击数量排行的Top3 + **需求分析** 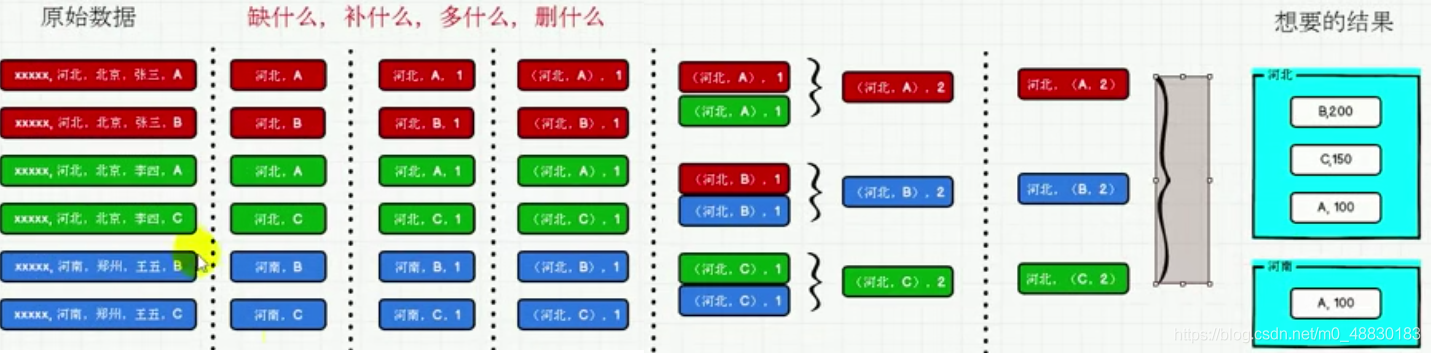 ### 二、实现 #### 2.1 步骤 ``` 1.获取原始数据 2.将原始数据进行结构的转换,方便统计 3.将转换后的数据进行分组聚合 4.将聚合的结果进行结构中转换 5.将转换结构后的数据根据省份进行分组 6.将分组后的数据组内排序(降序),取前3名 7.采集的数据打印到控制台 ``` #### 2.2 代码 ```scala import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @author lilinchao * @date 2021/11/1 * @description 统计出每一个省份每个广告被点击数量排行的Top3 **/ object SparkCoreAgentDemo { def main(args: Array[String]): Unit = { //TODO准备环境 val sparkConf =new SparkConf().setMaster("local[*]").setAppName("RDD") val sc= new SparkContext(sparkConf) //TODO 案例实操 //1.获取原始数据:时间戳,省份,城市,用户,广告 val dataRDD = sc.textFile("datas/agent.log") //2.将原始数据进行结构的转换,方便统计:时间戳,省份,城市,用户,广告 //((省份,广告),1) val mapRDD = dataRDD.map( line => { val datas = line.split(" ") ((datas(1),datas(4)),1) } ) //3.将转换后的数据进行分组聚合 // ((省份,广告),1) => ((省份,广告),sum) val reduceRDD:RDD[((String,String),Int)] = mapRDD.reduceByKey(_+_) //4.将聚合的结果进行结构中转换 //((省份,广告),sum) => (省份,(广告,sum)) val newMapRDD = reduceRDD.map { case ((prv, ad), sum) => { (prv, (ad, sum)) } } //5.将转换结构后的数据根据省份进行分组 // (省份,【(广告A,sumA),(广告B,sumB)】) val groupRDD:RDD[(String,Iterable[(String,Int)])] = newMapRDD.groupByKey() //6.将分组后的数据组内排序(降序),取前3名 val resultRDD = groupRDD.mapValues( iter => { iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(3) } ) //7.采集的数据打印到控制台 resultRDD.collect().foreach(println) //关闭环境 sc.stop() } } ``` **运行结果** ``` (4,List((12,25), (2,22), (16,22))) (8,List((2,27), (20,23), (11,22))) (6,List((16,23), (24,21), (22,20))) (0,List((2,29), (24,25), (26,24))) (2,List((6,24), (21,23), (29,20))) (7,List((16,26), (26,25), (1,23))) (5,List((14,26), (21,21), (12,21))) (9,List((1,31), (28,21), (0,20))) (3,List((14,28), (28,27), (22,25))) (1,List((3,25), (6,23), (5,22))) ``` ### 结尾 因为本篇使用的示例数据`agent.log`文件由于数据量较大将不在下方贴出。 直接在微信公众号【Java和大数据进阶】回复:**sparkdata**,即可获取。
标签:
Spark
,
Spark Core
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1602.html
上一篇
Spark Core案例实操(四)
下一篇
Spark Core案例实操(六)
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Stream流
Spark RDD
Java编程思想
数据结构
Elasticsearch
Nacos
MyBatis-Plus
字符串
MyBatis
Quartz
人工智能
JavaSE
Golang
栈
Map
FileBeat
MySQL
Kafka
随笔
Hbase
微服务
机器学习
国产数据库改造
Spring
设计模式
Spark SQL
BurpSuite
高并发
排序
Shiro
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭