李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
SparkCore之累加器
Leefs
2021-11-09 PM
1516℃
0条
[TOC] #### 前言 本篇将先从一个案例入手,对Driver端和Executer端执行过程进行一个简单了解,在深入讲解累加器。 ### 一、累加操作案例 #### 案例 **需求** > 将1,2,3,4进行累加求和操作 **代码** ```scala import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @author lilinchao * @date 2021/11/9 * @description 1.0 **/ object Spark_WordCount { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("Spark_WordCount").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) val dataRdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) var sum = 0 //foreach:将传入的值进行挨个遍历(属于分布式循环遍历) dataRdd.foreach( num => { sum += num } ) println("sum=" + sum) sc.stop() } } ``` **运行结果** ``` sum=0 ``` #### 结果分析 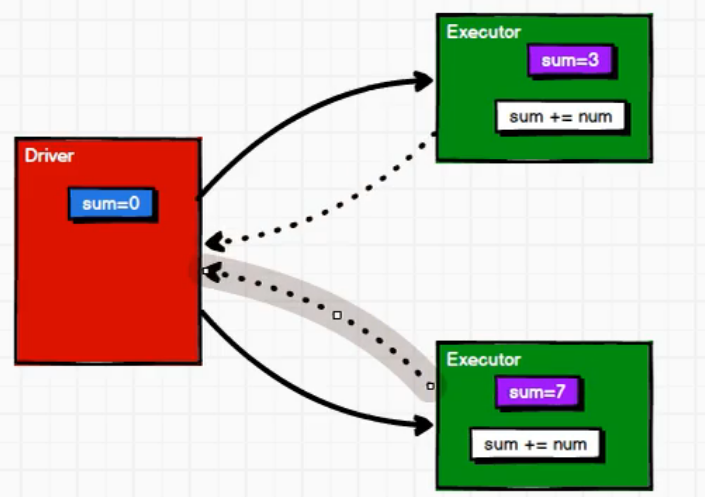 **说明** + Spark在Driver端会进行初始化操作使`sum=0`; + foreach是进行分布式执行,会将Driver端数据传输到多个Executor共同执行累加操作(数据传输的过程Spark中称为闭包检测); + 当Executor将自身的计算任务完成之后,**并不能够将计算后的结果返回到Driver端**; + Driver端传输到Executor端的数据会进行累加操作,但是Executor端并不能将计算好的结果返回给Driver端,导致Driver端的sum并没有发送变化; + 在Driver端输出sum的时候还是初始值0。 **Executor并不能将计算后的结果返回给Driver端** *注:Executor和Executor之间是独立的,不能互相读取数据* #### 结构改进  + Executor端将计算好的结果返回给Driver端; + Driver端再将各个Executor端返回的结果进行一个合并操作,得到最终结果。 *上方描述的也是累加器的主要功能。* ### 二、累加器概念 #### 2.1 定义 + 累加器:分布式共享只写变量。 #### 2.2 实现原理 累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在 Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后, 传回 Driver 端进行 merge。 #### 2.3 累加器分类 + 系统累加器 + 自定义累加器 ### 三、系统累加器 #### 3.1 使用步骤 (1)声明累加器 ```scala val sum: LongAccumulator = sc.longAccumulator("sum") ``` (2)使用累加器 ```scala sum.add(count) ``` (3)获取累加结果 ```scala sum.value ``` #### 3.2 代码示例 **需求** > 对("a", 1), ("a", 2), ("a", 3), ("a", 4)出现次数进行打印 ```scala import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @author lilinchao * @date 2021/11/8 * @description 系统累加器 **/ object accumulator01_system { /** * 需求: * 对("a", 1), ("a", 2), ("a", 3), ("a", 4)出现次数进行打印 * @param args */ def main(args: Array[String]): Unit = { val sparConf = new SparkConf().setMaster("local[*]").setAppName("accumulator01_system") val sc = new SparkContext(sparConf) //创建RDD val dataRDD: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4))) //方式一:通过reduceByKey输出单词出现的次数,代码执行过程中存在shuffle操作,效率较低 // dataRDD.reduceByKey(_ + _).collect().foreach(println) //方式二:通过foreach循环 /*var sum = 0 //输出是在Executor端 dataRDD.foreach{ case (a,count) =>{ sum = sum + count println("sum="+sum) } } //输出是在Driver端 println("a"+sum)*/ //方式三:使用系统自带累加器 val sum = sc.longAccumulator("sum") dataRDD.foreach{ case (a,count) =>{ //调用累加器add()方法 sum.add(count) } } //获取累加结果 println("a="+sum.value) //关闭连接 sc.stop() } } ``` **运行结果** ``` a=10 ``` #### 3.3 累加器放在行动算子中 对于要在行动操作中使用的累加器,Spark只会把每个任务对各累加器的修改应用一次。因此,如果想要一个无论在失败还是重复计算时都绝对可靠的累加器,我们必须把它放在foreach()这样的行动操作中。转化操作中累加器可能会发生不止一次更新。 **代码示例** ```scala import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD import org.apache.spark.util.LongAccumulator /** * @author lilinchao * @date 2021/11/8 * @description 1.0 **/ object accumulator02_updateCount { def main(args: Array[String]): Unit = { val sparConf = new SparkConf().setMaster("local[*]").setAppName("accumulator02_updateCount") val sc = new SparkContext(sparConf) //创建RDD val dataRDD: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4))) //定义累加器 val sum: LongAccumulator = sc.longAccumulator("sum") //统计累加器执行累加次数 val value: RDD[(String, Int)] = dataRDD.map(t => { //累加器添加数据 sum.add(1) t }) //调用两次行动算子,map执行两次,导致最终累加器的值翻倍 value.foreach(println) println("a1:"+sum.value) //收集操作 value.collect() //输出累加器累加次数 println("a2:"+sum.value) //关闭连接 sc.stop() } } ``` **运行结果** ``` (a,3) (a,4) (a,1) (a,2) a1:4 a2:8 ``` **说明** 从结果可以很明显的看出a1被调用了4次,多加了一个收集操作后到a2直接翻了一倍。 ### 四、自定义累加器 #### 4.1 版本 自定义累加器类型的功能在1.X版本中就已经提供了,但是使用起来比较麻烦,在2.0版本后,累加器的易用性有了较大的改进,而且官方还提供了一个新的抽象类:AccumulatorV2来提供更加友好的自定义类型累加器的实现方式。 #### 4.2 实现步骤 ``` (1)继承AccumulatorV2,设定输入、输出泛型 (2)重写方法 ``` #### 4.3 案例 **需求** > 自定义累加器,统计RDD中首字母为“H”的单词以及出现的次数。 **代码** ```scala import org.apache.spark.rdd.RDD import org.apache.spark.util.AccumulatorV2 import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable /** * @author lilinchao * @date 2021/11/8 * @description 自定义累加器 **/ object accumulator03_define { /** * 需求: * 自定义累加器,统计RDD中首字母为“H”的单词以及出现的次数 * List(“Hello”, “Hello”, “Hello”, “Hello”, “Hello”, “Spark”, “Spark”) * @param args */ def main(args: Array[String]): Unit = { val sparConf = new SparkConf().setMaster("local[*]").setAppName("accumulator03_define") val sc = new SparkContext(sparConf) //创建RDD val rdd: RDD[String] = sc.makeRDD(List("Hello", "Hello", "Hello", "Hello", "Spark", "Spark"), 2) //创建累加器 val acc: MyAccumulator = new MyAccumulator() //注册累加器 sc.register(acc,"wordCount") //调用累加器 rdd.foreach( word => { acc.add(word) } ) //获取累加器的累加结果 println(acc.value) //关闭连接 sc.stop() } } /** * 声明累加器: * 1.继承AccumulatorV2,设定输入、输出泛型 * 2.重写方法 */ class MyAccumulator extends AccumulatorV2[String,mutable.Map[String,Long]] { //定义输出数据集合 var map = mutable.Map[String,Long]() //是否为初始化状态 //定义如果集合中数据为空,即为初始化状态 override def isZero: Boolean = map.isEmpty //复制累加器 override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = { new MyAccumulator() } //重置累加器 override def reset(): Unit = map.clear() //增加数据 override def add(v: String): Unit = { //业务逻辑操作 if(v.startsWith("H")){ map(v) = map.getOrElse(v,0L)+1L } } //合并累加器 override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = { other.value.foreach{ case (word,count) => { map(word) = map.getOrElse(word,0L) + count } } } //累加器的返回结果 override def value: mutable.Map[String, Long] = map } ``` **运行结果** ``` Map(Hello -> 4) ``` *附参考文章链接:* *https://blog.csdn.net/weixin_42796403/article/details/111938041*
标签:
Spark
,
Spark Core
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1617.html
上一篇
Spark Core案例实操(十)
下一篇
SparkCore之广播变量
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
Java编程思想
Spark Streaming
国产数据库改造
人工智能
Scala
Beego
Yarn
Netty
JavaSE
SpringBoot
算法
LeetCode刷题
二叉树
Filter
MyBatis-Plus
Eclipse
JavaScript
栈
Linux
RSA加解密
前端
Spring
Http
查找
Redis
NIO
数据结构和算法
数据结构
FileBeat
递归
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭