李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
DataX介绍
Leefs
2022-03-20 AM
1890℃
0条
[TOC] ### 一、概述 DataX是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的**离线数据同步工具/平台**。 DataX 实现了包括MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS各种异构数据源之间**稳定高效**的数据同步功能。 #### 设计理念 为了解决异构数据源同步问题,DataX将复杂的**网状的同步链路**变成了**星型数据链路**,**DataX作为中间传输载体负责连接各种数据源**。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。 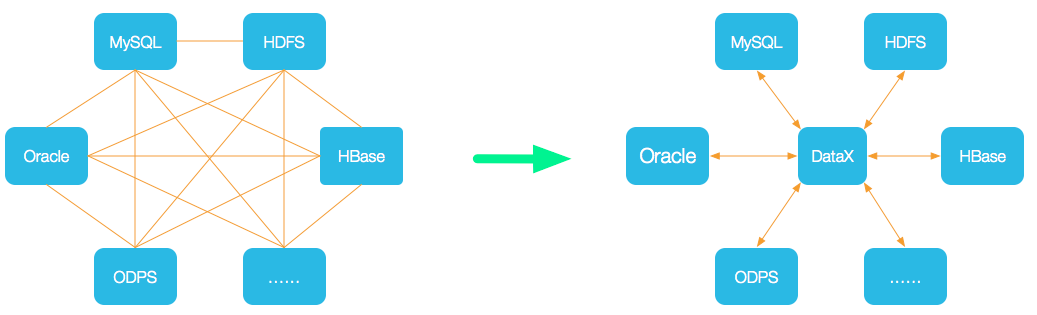 #### 使用 DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。 Github主页地址:https://github.com/alibaba/DataX ### 二、DataX3.0框架设计  DataX本身作为离线数据同步框架,采用**Framework + plugin**架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。 + **Reader**:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。 + **Writer**:Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。 + **Framework**:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。 ### 三、DataX3.0插件体系 经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。 **DataX目前支持数据如下:** | 类型 | 数据源 | Reader(读) | Writer(写) | | :----------------- | :------------------------------ | :--------- | :--------- | | RDBMS 关系型数据库 | MySQL | √ | √ | | | Oracle | √ | √ | | | SqlServer | √ | √ | | | PostgreSQL | √ | √ | | | 达梦 | √ | √ | | | 通用RDBMS(支持所有关系型数据库) | √ | √ | | 阿里云数仓数据存储 | ODPS | √ | √ | | | ADS | | √ | | | OSS | √ | √ | | | OCS | √ | √ | | NoSQL数据存储 | OTS | √ | √ | | | Hbase0.94 | √ | √ | | | Hbase1.1 | √ | √ | | | MongoDB | √ | √ | | 无结构化数据存储 | TxtFile | √ | √ | | | FTP | √ | √ | | | HDFS | √ | √ | DataX Framework提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源。 ### 四、DataX3.0核心架构 DataX 3.0 开源版本支持**单机多线程模式**完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。  **核心模块介绍** + DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。 + DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行**。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作**。 + 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,**默认单个任务组的并发数量为5**。 + 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动**Reader—>Channel—>Writer**的线程来完成任务同步工作。 + DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0。 #### DataX调度流程 举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 **DataX的调度决策思路是:** 1. DataXJob根据分库分表切分成了100个Task。 2. 根据20个并发,DataX计算共需要分配4个TaskGroup。 3. 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。 ### 五、DataX与Sqoop对比 | 功能 | DataX | Sqoop | | --------- | ---------------------------- | ---------------------------- | | 运行模式 | 单进程多线程 | MR | | MySQL读写 | 单机压力大;读写粒度容易控制 | MR模式重,写出错处理麻烦 | | Hive读写 | 单机压力大 | 很好 | | 文件格式 | orc支持 | orc不支持,可添加 | | 分布式 | 不支持,可以通过调度系统规避 | 支持 | | 流控 | 有流控功能 | 需要定制 | | 统计信息 | 已有一些统计,上报需定制 | 没有,分布式的数据收集不方便 | | 数据校验 | 在core部分有校验功能 | 没有,分布式的数据收集不方便 | | 监控 | 需要定制 | 需要定制 | | 社区 | 开源不久,社区不活跃 | 一直活跃,核心部分变动很少 | *附参考原文链接地址:* *https://developer.aliyun.com/article/59373?spm=5176.24320532.content1.2.6d4a2ff47ipb5s*
标签:
DataX
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1939.html
上一篇
12.Table API和Flink SQL之函数
下一篇
Flume概述
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
查找
Shiro
RSA加解密
Netty
ClickHouse
二叉树
链表
SpringCloudAlibaba
SpringCloud
Tomcat
JVM
NIO
VUE
Thymeleaf
并发线程
排序
pytorch
工具
LeetCode刷题
递归
GET和POST
Livy
Java
设计模式
随笔
人工智能
持有对象
Hadoop
Sentinel
Jquery
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭