李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
05.HDFS之NameNode和SecondaryNameNode
Leefs
2021-09-17 PM
1652℃
0条
[TOC] ### 一、NameNode元数据存储位置 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。**因此产生在磁盘中备份元数据的FsImage**。 这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。**因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。**这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。 但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。**因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。** ### 二、NameNode工作机制 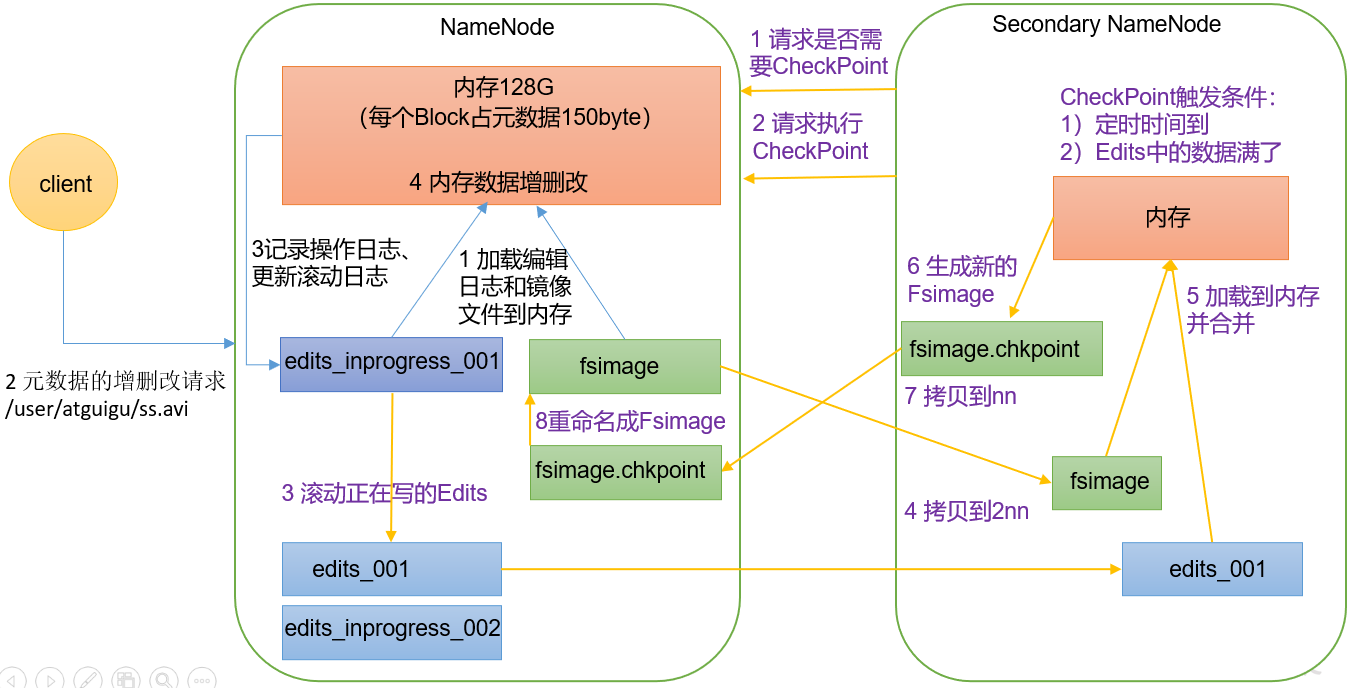 #### 第一阶段:NameNode启动 (1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。 (2)客户端对元数据进行增删改的请求。 (3)NameNode记录操作日志,更新滚动日志。 (4)NameNode在内存中对元数据进行增删改。 #### 第二阶段:Secondary NameNode工作 (1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。 (2)Secondary NameNode请求执行CheckPoint。 (3)NameNode滚动正在写的Edits日志。 (4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。 (5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。 (6)生成新的镜像文件fsimage.chkpoint。 (7)拷贝fsimage.chkpoint到NameNode。 (8)NameNode将fsimage.chkpoint重新命名成fsimage。 ### 三、Fsimage和Edits解析 #### 3.1 概念 NameNode被格式化之后,将在`/opt/module/hadoop-3.1.3/data/tmp/dfs/name/current`目录中产生如下文件 ```xml fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION ``` (1)Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目 录和文件inode的序列化信息。 (2)Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先 会被记录到Edits文件中。 (3)seen_txid文件保存的是一个数字,就是最后一个edits_的数字 (4)每次NameNode启动的时候都会将Fsimage文件读入内存,加 载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。 #### 3.2 实操 ##### 1、oiv查看Fsimage文件 (1)查看oiv和oev命令 ```shell [root@hadoop102 current]# hdfs oiv apply the offline fsimage viewer to an fsimage oev apply the offline edits viewer to an edits file ``` (2)基本语法 > hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径 ```shell [root@hadoop102 current]# hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xml ``` (4)查询`fsimage.xml`文件配置 ```shell [root@hadoop102 current]# cat /opt/module/hadoop-3.1.3/fsimage.xml ``` **结果展示** ```xml <inode> <id>16386</id> <type>DIRECTORY</type> <name>user</name> <mtime>1512722284477</mtime> <permission>atguigu:supergroup:rwxr-xr-x</permission> <nsquota>-1</nsquota> <dsquota>-1</dsquota> </inode> <inode> <id>16387</id> <type>DIRECTORY</type> <name>atguigu</name> <mtime>1512790549080</mtime> <permission>atguigu:supergroup:rwxr-xr-x</permission> <nsquota>-1</nsquota> <dsquota>-1</dsquota> </inode> <inode> <id>16389</id> <type>FILE</type> <name>wc.input</name> <replication>3</replication> <mtime>1512722322219</mtime> <atime>1512722321610</atime> <perferredBlockSize>134217728</perferredBlockSize> <permission>atguigu:supergroup:rw-r--r--</permission> <blocks> <block> <id>1073741825</id> <genstamp>1001</genstamp> <numBytes>59</numBytes> </block> </blocks> </inode > ``` 在集群启动后,要求 DataNode上报数据块信息,并间隔一段时间后再次上报。 ##### 2、oev查看Edits文件 (1)基本语法 > hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径 ```xml [root@hadoop102 current]# hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xml ``` (2)查看`edits.xml`配置文件 ```shell [root@hadoop102 current]# cat /opt/module/hadoop-3.1.3/edits.xml ``` **展示结果** ```xml <?xml version="1.0" encoding="UTF-8"?> <EDITS> <EDITS_VERSION>-63</EDITS_VERSION> <RECORD> <OPCODE>OP_START_LOG_SEGMENT</OPCODE> <DATA> <TXID>129</TXID> </DATA> </RECORD> <RECORD> <OPCODE>OP_ADD</OPCODE> <DATA> <TXID>130</TXID> <LENGTH>0</LENGTH> <INODEID>16407</INODEID> <PATH>/hello7.txt</PATH> <REPLICATION>2</REPLICATION> <MTIME>1512943607866</MTIME> <ATIME>1512943607866</ATIME> <BLOCKSIZE>134217728</BLOCKSIZE> <CLIENT_NAME>DFSClient_NONMAPREDUCE_- 1544295051_1</CLIENT_NAME> <CLIENT_MACHINE>192.168.10.102</CLIENT_MACHINE> <OVERWRITE>true</OVERWRITE> <PERMISSION_STATUS> <USERNAME>atguigu</USERNAME> <GROUPNAME>supergroup</GROUPNAME> <MODE>420</MODE> </PERMISSION_STATUS> <RPC_CLIENTID>908eafd4-9aec-4288-96f1- e8011d181561</RPC_CLIENTID> <RPC_CALLID>0</RPC_CALLID> </DATA> </RECORD> <RECORD> <OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE> <DATA> <TXID>131</TXID> <BLOCK_ID>1073741839</BLOCK_ID> </DATA> </RECORD> <RECORD> <OPCODE>OP_SET_GENSTAMP_V2</OPCODE> <DATA> <TXID>132</TXID> <GENSTAMPV2>1016</GENSTAMPV2> </DATA> </RECORD> <RECORD> <OPCODE>OP_ADD_BLOCK</OPCODE> <DATA> <TXID>133</TXID> <PATH>/hello7.txt</PATH> <BLOCK> <BLOCK_ID>1073741839</BLOCK_ID> <NUM_BYTES>0</NUM_BYTES> <GENSTAMP>1016</GENSTAMP> </BLOCK> <RPC_CLIENTID></RPC_CLIENTID> <RPC_CALLID>-2</RPC_CALLID> </DATA> </RECORD> <RECORD> <OPCODE>OP_CLOSE</OPCODE> <DATA> <TXID>134</TXID> <LENGTH>0</LENGTH> <INODEID>0</INODEID> <PATH>/hello7.txt</PATH> <REPLICATION>2</REPLICATION> <MTIME>1512943608761</MTIME> <ATIME>1512943607866</ATIME> <BLOCKSIZE>134217728</BLOCKSIZE> <CLIENT_NAME></CLIENT_NAME> <CLIENT_MACHINE></CLIENT_MACHINE> <OVERWRITE>false</OVERWRITE> <BLOCK> <BLOCK_ID>1073741839</BLOCK_ID> <NUM_BYTES>25</NUM_BYTES> <GENSTAMP>1016</GENSTAMP> </BLOCK> <PERMISSION_STATUS> <USERNAME>atguigu</USERNAME> <GROUPNAME>supergroup</GROUPNAME> <MODE>420</MODE> </PERMISSION_STATUS> </DATA> </RECORD> </EDITS > ``` ### 四、CheckPoint时间设置 (1)通常情况下,SecondaryNameNode 每隔一小时执行一次。 配置文件`hdfs-default.xml` ```xml <property> <name>dfs.namenode.checkpoint.period</name> <value>3600s</value> </property> ``` (2)一分钟检查一次操作次数,当操作次数达到 1 百万时,SecondaryNameNode 执行一次。 ```xml <property> <name>dfs.namenode.checkpoint.txns</name> <value>1000000</value> <description>操作动作次数</description> </property> <property> <name>dfs.namenode.checkpoint.check.period</name> <value>60s</value> <description> 1 分钟检查一次操作次数</description> </property> ``` *附:* *文章来源《尚硅谷大数据之Hadoop》*
标签:
Hadoop
,
HDFS
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1495.html
上一篇
04.HDFS之API操作
下一篇
06.HDFS之DataNode介绍
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
正则表达式
RSA加解密
nginx
队列
Docker
Azkaban
哈希表
并发线程
Jquery
Zookeeper
Scala
Flink
数据结构和算法
MySQL
微服务
字符串
LeetCode刷题
前端
二叉树
Java编程思想
Nacos
设计模式
国产数据库改造
pytorch
Shiro
SpringCloudAlibaba
Map
人工智能
Elasticsearch
VUE
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭