
Scala总结(三)
15.Scala总结(三)一、字符串操作object Scala_String_Test { def main(args: Array[String]): Unit = { val s1 = "Hello" val s2 = "Scala" //拼接、合并字符串 println(s1 + " "...
Scala总结(二)--函数
14.Scala总结(二)--函数一、函数的声明和调用1.1 函数的声明格式权限修饰符 函数名 (参数列表) : 返回值类型 = { 函数体 }案例:def func(i:Int) : Unit = { println(i) }1.2 函数的调用函数名(形参类表)二、函数的定义一共有如下6种情况:无参 --> 无返回值、有返回值 有参 --> 无返回值、有...
Scala总结(一)
13.Scala总结(一)一、基础1.1 数据类型Scala 与 Java有着相同的数据类型,下表列出了 Scala 支持的数据类型:数据类型描述Byte8位有符号补码整数。数值区间为 -128 到 127Short16位有符号补码整数。数值区间为 -32768 到 32767Int32位有符号补码整数。数值区间为 -2147483648 到 2147483647Long64位有符号补码整...
Spark核心概念
12.Spark核心概念一、Executor与Core Spark Executor 是集群中运行在工作节点(Worker)中的一个 JVM 进程,是整个集群中 的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资 源。这里的资源一般指的是工作节点 Executor 的内存大小和使用的虚拟 CPU 核(Core)数量。应用程序相关启动参数如下:名称说明--...
Spark运行架构
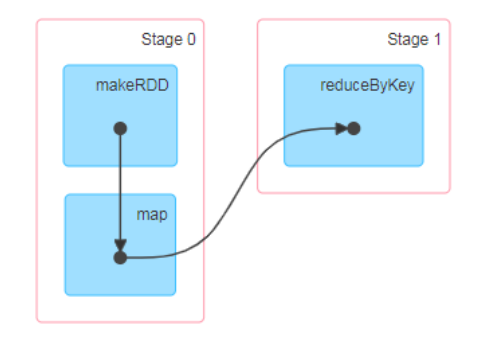
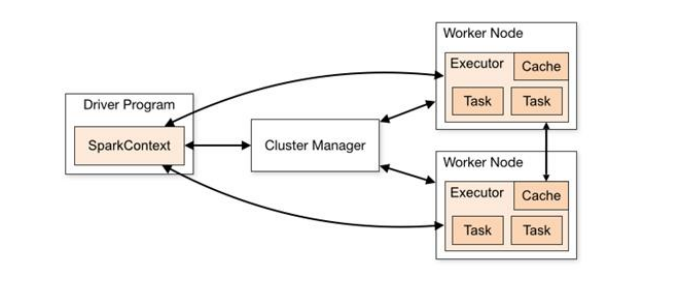
11.Spark运行架构一、运行架构Spark框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。 如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。二、核心组件由上图可以看出,对于 Spark 框架有两个核心组件...
Spark Standalone模式搭建
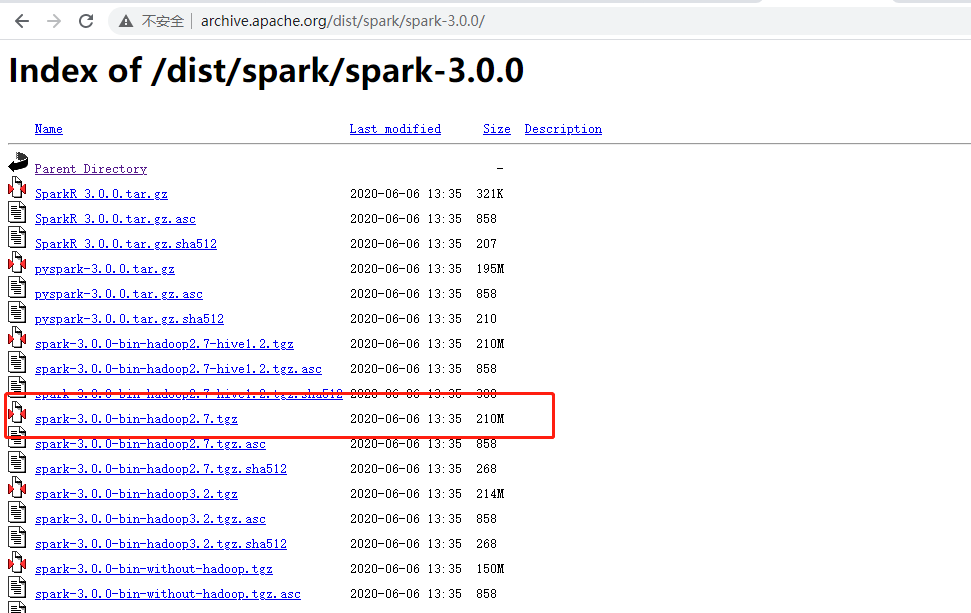
10.Spark Standalone模式搭建前言搭建 Spark 集群前,需要保证 JDK 环境、Zookeeper 集群和 Hadoop 集群已经搭建,相关步骤可以参阅:Zookeeper集群环境搭建Hadoop集群环境搭建一、集群介绍这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Maste...

Zookeeper集群环境搭建
09.Zookeeper集群环境搭建前言本次安装Zookeeper集群是为Spark Standalone集群搭建做准备工作。为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里演示搭建一个三个节点的集群。这里我使用三台主机进行搭建,主机名分别为 hadoop001,hadoop002,hadoop003。一、安装步骤1. 下载下载对应版本 Zookeepe...
CentOS7安装Hadoop3.2集群
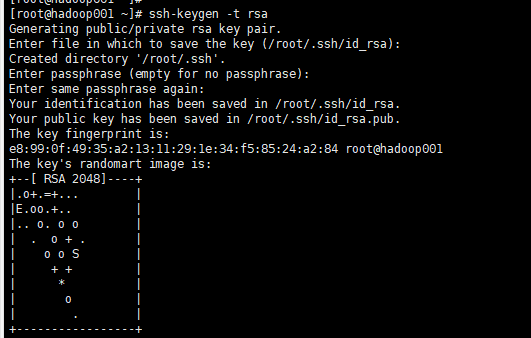
08.CentOS7安装Hadoop3.2集群前言虚拟机网络配置通过ip addr命令未查询到虚拟机IP地址1、修改网络配置[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-eno16777736将ONBOOT=no改为ONBOOT=yesONBOOT的意思是,开机时是否启动2、重启网络服务[root@localhost ...