李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
Spark入门介绍
Leefs
2021-02-15 AM
2232℃
0条
# 01.Spark入门介绍 ### 一、简介 Spark是一种基于内存的快速、通用、可扩展的**大数据分析计算引擎**。同Hadoop的MapReduce计算框架类似,但是相对于MapReduce,Spark凭借其可伸缩、基于内存计算等特点,以及可以直接读写Hadoop上任何格式数据的优势,进行批处理时更加高效,并有更低的延迟。 ### 二、历史 + 2009 年,Spark 诞生于伯克利大学的 AMPLab 实验室 + 2010 年,伯克利大学正式开源了 Spark 项目 + 2013 年 6 月,Spark 成为了 Apache 基金会下的项目 + 2014 年 2 月,Spark 以飞快的速度成为了 Apache 的顶级项目 + 2015 年至今,Spark 变得愈发火爆,大量的国内公司开始重点部署或者使用 Spark ### 三、Spark特点 基于Hadoop的资源管理器YARN实际上是一个弹性计算平台,作为统一的计算资源管理框架,不仅仅服务于MapReduce计算框架,而且已经实现了多种计算框架进行统一管理。这种共享集群资源的模式带来了很多好处。 **1. 快速** + Spark有先进的DAG执行引擎,支持循环数据流和内存计算;Spark程序在内存中的运行速度是Hadoop MapReduce运行速度的100倍,在磁盘上的运行速度是Hadoop MapReduce运行速度的10倍。 **2. 易用** + Spark支持使用Java、Scala、Python语言快速编写应用,提供超过80个高级运算符,使得编写并行应用程序变得容易。 **3. 通用** + Spark可以与SQL、Streaming以及复杂的分析良好结合。基于Spark,有一系列高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX和Spark Streaming,支持在一个应用中同时使用这些架构。 **4. 有效集成Hadoop** + Spark可以指定Hadoop,YARN的版本来编译出合适的发行版本,Spark也能够很容易地运行在EC2、Mesos上,或以Standalone模式运行,并从HDFS、HBase、Cassandra和其他Hadoop数据源读取数据。 **5. 资源利用率高** + 多种框架共享资源的模式有效解决了由于应用程序数量的不均衡性导致的高峰时段任务比较拥挤,空闲时段任务比较空闲的问题;同时均衡了内存和CPU等资源的利用。 **6. 实现了数据共享** + 随着数据量的增加,数据移动成本越来越高,网络带宽、磁盘空间、磁盘IO都会成为瓶颈,在分散数据的情况下,会造成任务执行的成本提高,获得结果的周期变长,而数据共享模式可以让多种框架共享数据和硬件资源,大幅度减少数据分散带来的成本。 **7. 有效降低运维和管理成本** + 相比较一种计算框架需要一批维护人员,而运维人员较多又会带来的管理成本的上升;共享模式只需要少数的运维人员和管理人员即可完成多个框架的统一运维管理,便于运维优化和运维管理策略统一执行。 ### 四、Spark核心模块介绍 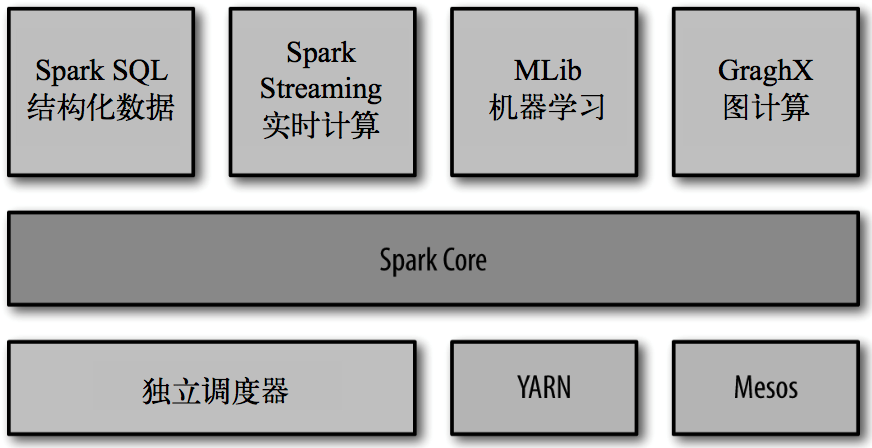 **模块介绍:** **Spark Core:** 实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统 交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的 API 定义。 **Spark SQL:** 是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 语言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。 **Spark Streaming:** 是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。 **Spark MLlib:** 提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。 **集群管理器:** Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度器,叫作独立调度器。 ### 五、Spark应用场景 Spark使用了内存分布式数据集,除了能够提供交互式查询外,还优化了迭代工作负载,在Spark SQL、Spark Streaming、MLlib、GraphX都有自己的子项目。在互联网领域,Spark在快速查询、实时日志采集处理、业务推荐、定制广告、用户图计算等方面都有相应的应用。国内的一些大公司,比如阿里巴巴、腾讯、Intel、网易、科大讯飞、百分点科技等都有实际业务运行在Spark平台上。下面简要说明Spark在各个领域中的用途。 **1. 快速查询系统** + 基于日志数据的快速查询系统业务构建于Spark之上,利用其快速查询以及内存表等优势,能够承担大部分日志数据的即时查询工作;在性能方面,普遍比Hive快2~10倍,如果使用内存表的功能,性能将会比Hive快百倍。 **2. 实时日志采集处理** + 通过Spark Streaming实时进行业务日志采集,快速迭代处理,并进行综合分析,能够满足线上系统分析要求。 **3. 业务推荐系统** + 使用Spark将业务推荐系统的小时和天级别的模型训练转变为分钟级别的模型训练,有效优化相关排名、个性化推荐以及热点点击分析等。 **4. 定制广告系统** + 在定制广告业务方面需要大数据做应用分析、效果分析、定向优化等,借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,支持上亿的请求量处理;模拟广告投放计算效率高、延迟小,同MapReduce相比延迟至少降低一个数量级。 **5. 用户图计算** + 利用GraphX解决了许多生产问题,包括以下计算场景:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等 *附:* [参考文章链接](https://blog.csdn.net/u011204847/article/details/51010205)
标签:
Spark
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1156.html
上一篇
Linux高级指令
下一篇
Spark和Hadoop比较
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
JVM
Netty
Nacos
高并发
JavaWEB项目搭建
国产数据库改造
Hbase
Spark
Redis
Ubuntu
ClickHouse
SQL练习题
BurpSuite
数学
链表
FastDFS
Thymeleaf
Zookeeper
Tomcat
Sentinel
排序
二叉树
nginx
查找
设计模式
MyBatis
Spark SQL
RSA加解密
Git
数据结构
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭