李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
大数据
正文
Hbase原理
Leefs
2021-02-12 PM
1837℃
0条
# 08.Hbase原理 ### 一、Hbase读流程 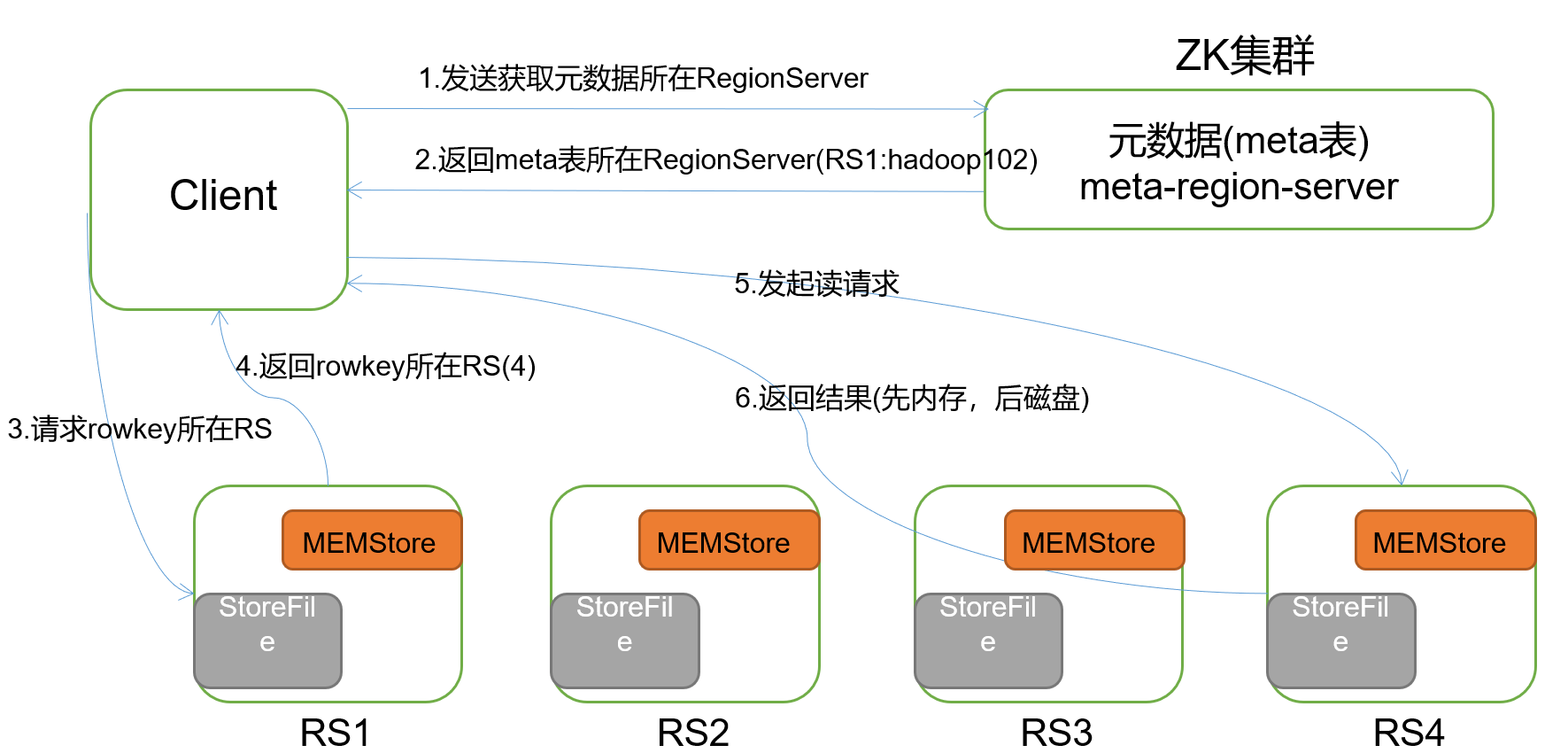 **步骤说明:** 1.Client先访问Zookeeper,从meta表读取region的位置,然后读取meta表中的数据。meta中又存储了用户表的region信息; 2.根据namespace、表名和rowkey在meta表中找到对应的region信息; 3.找到这个region对应的regionserver; 4.查找对应的region; 5.先从MemStore找数据,如果没有,再到BlockCache里面读; 6.BlockCache还没有,再到StoreFile上读(为了读取的效率); 7.如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端。 ### 二、Hbase写流程  (1)Client向HregionServer发送写请求; (2)HregionServer将数据写到HLog(write ahead log)。为了数据的持久化和恢复; (3)HregionServer将数据写到内存(MemStore) (4)反馈Client写成功 ### 三、数据flush过程 (1)当MemStore数据达到阈值(默认是128M,老版本是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据; (2)并将数据存储到HDFS中 (3)在HLog中做标记点 ### 四、数据合并过程 (1)当数据块达到3块,Hmaster触发合并操作,Region将数据块加载到本地,进行合并; (2)当合并的数据超过256M,进行拆分,将拆分后的Region分配给不同的HregionServer管理; (3)当HregionServer宕机后,将HregionServer上的hlog拆分,然后分配给不同的HregionServer加载,修改.META.; (4)注意:HLog会同步到HDFS。
标签:
Hbase
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1131.html
上一篇
Hbase shell操作
下一篇
Linux基础指令
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
DataX
栈
Ubuntu
Yarn
HDFS
稀疏数组
Quartz
GET和POST
序列化和反序列化
Kafka
Golang
VUE
数学
队列
Golang基础
Spark SQL
Spark Streaming
算法
Redis
Tomcat
FastDFS
RSA加解密
Jquery
Azkaban
Hadoop
Filter
数据结构和算法
JavaSE
国产数据库改造
查找
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭