李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
Java
正文
ElasticSearch核心概念
Leefs
2021-02-10 PM
2058℃
0条
# 08.ElasticSearch核心概念 ### 一、概述 **1、近实时** 从写入数据到可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级(倒排索引)。 **2、Cluster(集群)** 每个集群包含一个或者多个节点,具备green、yellow和red三种健康值,具有唯一名字,分布式系统,具备高可用和可扩展性。 **3、Node(节点)** 集群中的单个节点,其实Elasticsearch实例,java的一个进程。一台服务器随可以部署多个es节点,但建议一台服务器只运行一个ES实例。用于存储和提供集群的搜索和索引功能,具备唯一名字,默认启动时会生成一个uuid,名字也可以单独指定。 **4、Index(索引)** 一类相同或者相似的document集合。 + 索引名词:相当于关系型数据库中的**数据库**,其名称必须为全小写字符。 + 索引动词:保存一个文档到索引(名词)的过程。类似关系型数据库的insert或者update,保存数据到datebase。 **5、document(文档)** ES最小的数据单元,等同于关系数据库中的行。 **6、Type(类型)** 可以理解为关系数据库中的表,6.x开始单个索引中只能有一个类型,在7.x版本之后,不建议使用,8.x以后完全不支持。 **废弃原因:**虽然通常将index理解为database,type理解为table,但是是非常不准确的,关系型数据库中table之间相互独立、毫无关系,两个表同名字段更加毫无关联。而在ES中,相同index不同type下,如果有相同名称字段,字段定义必须相同。 **7、field(数据字段)** 与index和type一起,可以定位一个文档。 **8、shards(分片)** ES可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。 分片有两个好处,一是可以水平扩展,另一个是可以并发提高性能。 **9、replicas(副本)** 代表索引副本,ES可以设置多个索引副本,副本的作用: 1. 提高系统的容错性,实现高可用(HA),当某个节点某个分片损坏或丢失时可以从副本中恢复 2. 提高ES的查询效率,ES会自动对搜索请求进行负载均衡。 **ES和关系型数据库对比:** | Relational DB | Elasticsearch | | ---------------- | ------------- | | 数据库(database) | 索引(index) | | 表(tables) | types | | 行(rows) | documents | | 字段(columns) | fields | ### 二、倒排索引介绍 **1、正排索引介绍** 在说倒排索引之前我们先说说什么是正排索引。正排索引也称为"前向索引",它是创建倒排索引的基础。 这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档ID对应的文档内容,将其直接删除。 他适合根据文档ID来查询对应的内容。但是在查询一个keyword在哪些文档里包含的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。 比如有几个文档及里面的内容,他正排索引构建的结果如下: | 文档ID | 文档内容 | | ------ | ------------------------------- | | 1 | Elasticsearch是最流行的搜索引擎 | | 2 | Java是世界上最好的语言 | | 3 | 搜索引擎是如何诞生的 | 优点:工作原理非常的简单。 缺点:检索效率太低,只能在一些简单的场景下使用。 **2、倒排索引** 根据字面意思可以知道他和正序索引是反的。在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(文档要除去一些无用的词,比如’的’这些,剩下的词就是关键词,每个关键词都有自己的ID)。例如“文档1”经过分词,提取了3个关键词,每个关键词都会记录它所在在文档中的出现频率及出现位置。 那么上面的文档及内容构建的倒排索引结果会如下: | 单词 | 文档ID列表 | | ------------- | ---------- | | Elasticsearch | 1 | | 流行 | 1 | | 搜索引擎 | 1,3 | | Java | 2 | | 世界 | 2 | | 最好 | 2 | | 语言 | 2 | | 如何 | 3 | | 诞生 | 3 | **如何进行查询?** 比如我们要查询‘搜索引擎’这个关键词在哪些文档中出现过。首先我们通过倒排索引可以查询到该关键词出现的文档位置是在1和3中;然后再通过正排索引查询到文档1和3的内容并返回结果。 **3、倒排索引组成** 倒排索引主要由单词词典(Term Dictionary)和倒排列表(Posting List)及倒排文件(Inverted File)组成。 他们三者的关系如下图: 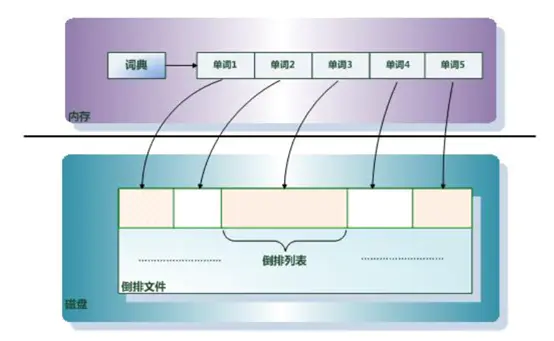 **单词词典(Term Dictionary):**搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。 **倒排列表(PostingList):**倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息及频率(作关联性算分),每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。 **倒排文件(Inverted File):**所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。 **以查找【搜索引擎】查找为例:** | 文档ID | 文档内容 | | ------ | ------------------------------- | | 1 | Elasticsearch是最流行的搜索引擎 | | 2 | Java是世界上最好的语言 | | 3 | 搜索引擎是如何诞生的 | 对应的查找Posting List | 文档ID | 出现次数 | 位置 | 索引坐标 | | ------ | -------- | ---- | -------- | | 1 | 1 | 2 | <18,22> | | 3 | 1 | 0 | <0,4> | *符:* [参考文章链接](https://www.jianshu.com/p/c96576fcbcd9)
标签:
Elasticsearch
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1038.html
上一篇
ElasticSearch安装IK分词器
下一篇
ElasticSearch简单操作
评论已关闭
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
NLP
4
标签云
MyBatis
Filter
Elastisearch
Flume
Java编程思想
Redis
CentOS
锁
Nacos
Linux
栈
人工智能
ajax
pytorch
Livy
Quartz
Spark
Flink
Kibana
Golang基础
ClickHouse
Typora
FileBeat
Hive
并发线程
链表
RSA加解密
Netty
Tomcat
nginx
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞
评论已关闭