李林超博客
首页
归档
留言
友链
动态
关于
归档
留言
友链
动态
关于
首页
Java
正文
ElasticSearch简单操作
Leefs
2021-02-10 PM
1238℃
0条
### 一、Rest风格说明 一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交 互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。 基本Rest命令说明: | 方法 | url地址 | 描述 | | ------ | ----------------------------------------------- | ---------------------- | | PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) | | POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) | | POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 | | DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 | | GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id | | POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 | ### 二、索引基本操作 **1、初始化索引(也就是创建一个数据库)** ```json PUT my_index #设置索引名称 { "settings": { #设置 "index": { #索引 "number_of_shards":5, #设置分片数 "number_of_replicas":1 #设置副本数 } } } #获取指定索引的设置信息 GET my_index/_settings #获取所有索引的设置信息 GET _all/_settings #获取多个索引的设置信息 #GET 索引名称,索引名称/_settings GET my_index,my_store/_settings ``` 注意:索引一旦创建,分片数量不可修改,副本数量可以修改的 **2、创建一个索引** ```json PUT /my_index/user/1 { "name":"李林超博客", "age": 12 } #创建第二个索引,用于后面测试 PUT /test_find/it_job/1 { "post_name":"Java开发攻城狮", "address":"北京" } ``` 索引名称有以下限制: > 1. 必须是小写 > 2. 不能包含:`\`,`/`,`*`, `?`, `"`, `<`, `>`, `|`, (空格),`,`, `#` > 3. 在ES7.0以前索引名可以包含冒号,但是7.0之后不支持了 > 4. 不能以`-`,`_`和`+`开头 > 5. 不能是`.`或`..` > 6. 长度不能超过255字节 **3、索引查询操作** ```json #获取整个索引下的数据 GET /my_index #获取某个文档的数据 GET /my_index/user/1 #获取某个文档的数据的某个字段 GET /my_index/user/1?_source=name #只获取文档内容不要元数据 GET /my_index/user/1/_source #查询指定索引的全部信息 GET /my_index/_search ``` **多索引,多type搜索** > `/_search`:在所有的索引中搜索所有的类型 > > `/my_index/_search`:在 `school` 索引中搜索所有的类型 > > `/my_index,test_find/_search`:在 `my_index` 和`test_find`索引中搜索所有的类型 > > `/m*,t*/_search`:在所有以`m`和`t`开头的索引中搜索所有的类型 > > `/my_index/user/_search`:在`my_index`索引中搜索`user`类型 > > `/my_index,test_find/user,it_job/_search`:在`my_index`和`test_find`索引上搜索`user`和`it_job`类型 > > `/_all/user,it_job/_search`:在所有的索引中搜索`user`和`it_job`类型 **4、索引修改操作** ```json #方法一:在原有PUT创建索引时直接进行覆盖操作 PUT /my_index/user/1 { "name":"李林超博客-123" } #缺陷:相当于再次创建没有传入的参数会为空 #方法二 POST /my_index/user/1/_update { "doc":{ "name": "李林超博客-123" } } #没有传入的参数不会制空 ``` **5、索引删除操作** ```json #根据Id删除指定文档 DELETE /my_index/user/1 #删除索引(删除整个索引库) DELETE /my_index ``` ### 三、复杂查询操作 **1、添加多条数据方便进行查询** ```json #添加数据 POST /my_index2/user/_bulk { "index": { "_id": 1 }} { "name" : "李林超博客", "age" :20,"desc":"菜鸟一个","tages":["程序猿","菜鸟","爱学习"] } { "index": { "_id": 2 }} { "name" : "李林超博客—Test2", "age" :5,"desc":"李林超博客测试","tages":["程序猿","攻城狮","直男"] } { "index": { "_id": 3 }} { "name" : "张三", "age" :38,"desc":"金融行业大佬","tages":["理财","金融","暖男"] } { "index": { "_id": 4 }} { "name" : "李四", "age" :59,"desc":"快要退休的计算机老师","tages":["教学","计算机","直男"] } ``` `bulk`批量操作可以在单次API调用中实现多个文档的`create`、`index`、`update`或`delete`。这可以大大提高索引速度 **`bulk`请求体如下** ```json { action: { metadata }}\n { request body }\n { action: { metadata }}\n { request body }\n ``` **action**必须是以下几种: | 行为 | 解释 | | ------ | ------------------------ | | create | 当文档不存在时创建 | | index | 创建新文档或替换已有文档 | | update | 局部更新文档 | | delete | 删除一个文档 | 在索引、创建、更新或删除时必须指定文档的`_index`、`_type`、`_id`这些元数据(`metadata`) *注:`bulk`请求不是原子操作,它们不能实现事务。每个请求操作是分开的,所以每个请求的成功与否不干扰其它操作* **2、带条件的简单查询** ```json #带条件的简单条件查询 GET /my_index2/user/_search?q=name:李林超博客 ``` 多个参数用&分开 更多查询参数: 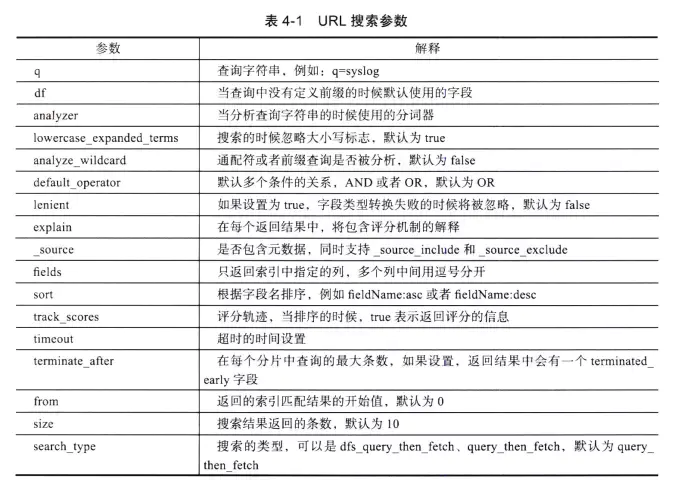 **3、查询DSL** elasticsearch提供了基于JSON的完整查询DSL来定义查询,DSL拥有一套查询组件,这些组件可以以无限组合的方式进行搭配,构建各种复杂的查询 **4、叶子语句** 叶子语句:就像match语句,被用于将查询的字符串与一个字段或多个字段进行对比(单个条件) ```json GET /my_index2/user/_search { "query": { "match": { "name": "李林超博客" } } } ``` **5、复合查询** 可以多个查询条件进行合并,比如一个`bool`语句,允许你在需要的时候组合其他语句,包括`must`,`must_not`,`should`和`filter`语句(多条件组合查询): ```json GET /my_index2/user/_search { "query": { "bool": { "must": [ { "match": { "name": "李林超博客" } } ], "must_not": [ { "match": { "age": "5" } } ], "should": [ { "match": { "desc": "金融" } } ], "filter": { "term": { "tages": "教学" } } } } } ``` **说明** > `must`:表示文档一定要包含查询的内容,相当于SQL语句中的`and` > > `must_not`:表示文档一定不要包含查询的内容,相当于SQL语句中的`not` > > `should`:表示如果文档匹配上可以增加文档相关性得分,相当于SQL语句中的`or` 事实上我们可以使用两种结构化语句: + 结构化查询`query DSL` 用于检查内容与条件是否匹配,内容查询中使用的bool和match字句,用于计算每个文档的匹配得分,元字段_score表示匹配度,查询的结构中以query参数开始来执行内容查询 + 结构化过滤`Filter DSL` 只是简单的决定文档是否匹配,内容过滤中使用的term和range字句,会过滤掉不匹配的文档,并且不影响计算文档匹配得分 使用过滤查询会被es自动缓存用来提高效率 ### 四、关键词详解 **1、match_all查询** 查询匹配所有文档 ```json GET /my_index2/user/_search { "query": { "match_all": {} } } ``` **2、match查询** 支持全文搜索和精确查询,取决于字段是否支持全文检索 全文检索: ```json GET /my_index2/user/_search { "query": { "match": { "name": "李林超博客 张三" } } } ``` 全文检索会将查询的字符串先进行分词,然后在倒排索引中进行匹配 精确查询: ```json GET /my_index2/user/_search { "query": { "match": { "age": "38" } } } ``` 对于精确值的查询,可以使用 filter 语句来取代 query,因为 filter 将会被缓存 `operator`操作: `match` 查询还可以接受 `operator` 操作符作为输入参数,默认情况下该操作符是 `or` 。我们可以将它修改成 `and` 让所有指定词项都必须匹配 ```json GET /my_index2/user/_search { "query": { "match": { "tages": { "query": "程序猿 菜鸟", "operator": "and" } } } } ``` 精确度匹配: `match` 查询支持 `minimum_should_match` 最小匹配参数, 可以指定必须匹配的词项数用来表示一个文档是否相关。我们可以将其设置为某个具体数字(指需要匹配倒排索引的词的数量),更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量 ```json GET /my_index2/user/_search { "query": { "match": { "tages": { "query": "程序猿 菜鸟", "minimum_should_match": "2" } } } } ``` 只会返回匹配上`程序猿`和`菜鸟`两个词的文档返回,如果`minimum_should_match`是1,则只要匹配上其中一个词,文档就会返回 **3、multi_match查询** 多字段查询,比如查询`desc`和`tages`字段包含`直`的文档 ```json GET /my_index2/user/_search { "query": { "multi_match": { "query": "直", "fields": ["tages","desc"] } } } ``` **4、range查询** 范围查询,查询年龄大于6小于60的文档 ```json GET /my_index2/user/_search { "query": { "range": { "age": { "gt": 6, "lt": 60 } } } } ``` 范围查询操作符: | 字符 | 说明 | | ---- | -------- | | gt | 大于 | | gte | 大于等于 | | lt | 小于 | | lte | 小于等于 | **5、term查询** 精确值查询 查询`age`字段等于38的文档 ```json GET /my_index2/user/_search { "query": { "term": { "age": { "value": "38" } } } } ``` 查询`name`字段等于`李林超博客`的文档 ```json GET /my_index2/user/_search { "query": { "term": { "name": { "value": "李林超博客" } } } } ``` 返回值如下,没有查询到名称为`李林超博客`的文档 ```json { "took" : 7, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 0, "relation" : "eq" }, "max_score" : null, "hits" : [ ] } } ``` 为什么没有查到`李林超博客`的这个文档那,这里需要介绍一下`term`的查询原理 `term`查询会去倒排索引中寻找确切的`term`,它并不会走分词器,只会去匹配倒排索引 ,而`name`字段的`type`类型是`text`,会进行分词,将`李林超博客`进行切分,我们使用`term`查询`李林超博客`时倒排索引中没有`李林超博客`,所以没有查询到匹配的文档。 `term`查询与`match`查询的区别 - `term`查询时,不会分词,直接匹配倒排索引 - `match`查询时会进行分词 还有一点需要注意,因为`term`查询不会走分词器,但是回去匹配倒排索引,所以查询的结构就跟分词器如何分词有关系,比如新增一个`/my_index2/user`类型下的文档,`name`字段赋值为`Oppo`,这时使用`term`查询`Oppo`不会查询出文档,这时因为es默认是用的`standard`分词器,它在分词后会将单词转成小写输出,所以使用`oppo`查不出文档,使用小写`oppo`可以查出来 ```json GET /my_index2/user/_search { "query": { "term": { "name": { "value": "Oppo" //改成oppo可以查出新添加的文档 } } } } ``` 6、terms查询 `terms`查询与`term`查询一样,但它允许你指定多直进行匹配,如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件 ```json GET /my_index2/user/_search { "query": { "terms": { "age": ["5","38"] } } } ``` #### 7. `exists` 查询 用于查找那些指定字段中有值 (`exists`)的文档 指定`name`字段有值: ```json GET /my_index2/user/_search { "query": { "bool": { "filter": { "exists": { "field": "name" } } } } } ``` **8. match_phrase查询** 短语查询,精确匹配,查询`攻城狮`会匹配`tages`字段包含`攻城狮`短语的,而不会进行分词查询,也不会查询出包含`攻城xxx狮`这样的文档 ```json GET /my_index2/user/_search { "query": { "match_phrase": { "tages": "攻城狮" } } } ``` **9. scroll查询** 类似于分页查询,不支持跳页查询,只能一页一页往下查询,`scroll`查询不是针对实时用户请求,而是针对处理大量数据,例如为了将一个索引的内容重新索引到具有不同配置的新索引中 ```json POST /my_index2/user/_search?scroll=1m { "query": { "match_all": {} }, "size": 1, "from": 0 } ``` 返回值包含一个`"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAk-IWcnNUZFJ2cVBTNDZGRnRsRExiZ3Jsdw=="` 下次查询的时候使用`_scroll_id`就可以查询下一页的文档 ```json POST /_search/scroll { "scroll" : "1m", "scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAk-IWcnNUZFJ2cVBTNDZGRnRsRExiZ3Jsdw==" } ``` **10. fuzzy查询** 模糊查询,`fuzzy` 查询会计算与关键词的拼写相似程度 ```json GET /my_index2/user/_search { "query": { "fuzzy": { "tages":{ "value": "攻城狮", "fuzziness": 2, "prefix_length": 1 } } } } ``` 参数设置: + fuzziness:最大编辑距离,默认为`AUTO` + prefix_length:不会“模糊化”的初始字符数。这有助于减少必须检查的术语数量,默认为`0` + max_expansions:`fuzzy`查询将扩展到 的最大术语数。默认为`50`,设置小,有助于优化查询 + transpositions:是否支持模糊转置(`ab`→ `ba`),默认是`false` **11、wildcard查询** 支持通配符的模糊查询,?匹配单个字符,*匹配任何字符 为了防止极其缓慢通配符查询,`*`或`?`通配符项不应该放在通配符的开始 ``` json GET /my_index2/user/_search { "query": { "wildcard": { "name": "张*" } } } ``` *附:* [参考文档链接地址](https://juejin.cn/post/6844903890396135438#heading-18)
标签:
Elasticsearch
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:
https://lilinchao.com/archives/1039.html
上一篇
ElasticSearch核心概念
下一篇
CentOS7安装ElasticSearch教程
取消回复
评论啦~
提交评论
栏目分类
随笔
2
Java
326
大数据
229
工具
31
其它
25
GO
47
标签云
数据结构和算法
Yarn
Stream流
Golang
Flink
Kibana
Http
Jenkins
数据结构
Python
Golang基础
Flume
Nacos
Quartz
稀疏数组
查找
工具
Java编程思想
国产数据库改造
Elastisearch
链表
SpringCloudAlibaba
Spark Core
NIO
nginx
线程池
Netty
Kafka
高并发
SpringBoot
友情链接
申请
范明明
庄严博客
Mx
陶小桃Blog
虫洞