01.SparkStreaming概述
[TOC]前言在介绍SparkStreaming之前需要先理解几个概念:流式计算流式计算的上游算子处理完一条数据后,会立马发送给下游算子,所以一条数据从进入流式系统到输出结果的时间间隔较短(当然有的流式系统为了保证吞吐,也会对数据做buffer)。批量计算批量计算按数据块来处理数据,每一个task接收一定大小的数据块,比如MR,map任务在处理完一个完整的数据块后(比如128M),然后将中间...
18.【终章】Kafka监控工具Eagle最新版安装
[TOC]前言Kafka监控系统在Kafka的监控系统中有很多优秀的开源监控系统。比如Kafka-manager,open-faclcon,zabbix等主流监控工具均可直接监控kafka。Kafka集群性能监控可以从消息网络传输,消息传输流量,请求次数等指标来衡量集群性能。这些指标数据可以通过访问kafka集群的JMX接口获取。JMX接口JMX(Java Management Extens...
17.Kafka自定义拦截器
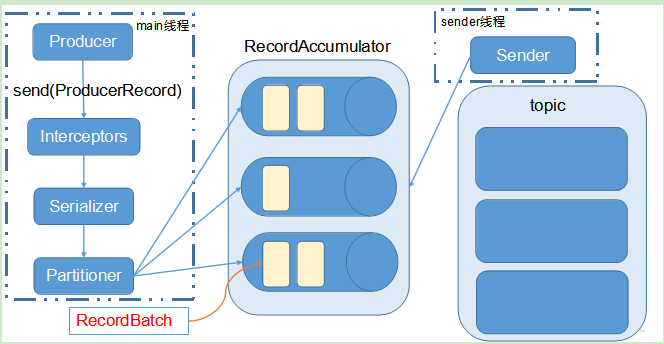
[TOC]一、拦截器原理 Producer 拦截器(interceptor)是在 Kafka 0.10 版本被引入的,主要用于实现clients端的定制化控制逻辑。 对于 producer 而言,interceptor 使得用户在消息发送前以及 producer 回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer 允许用户指定多个 ...
16.Kafka消费者API
[TOC]前言Consumer 消费数据时的可靠性是很容易保证的,因为数据在 Kafka 中是持久化的,故不用担心数据丢失问题。由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。所以 offset 的维护是 Consumer 消费数据是必须考虑的...