CentOS7 Spark Local模式搭建
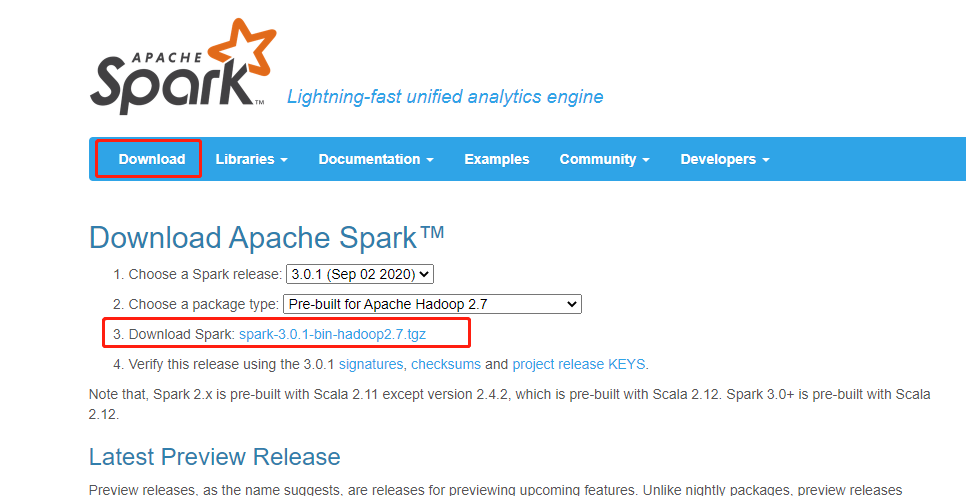
07.CentOS7 Spark Local模式搭建前言需要提前准备的环境JDK1.8Hadoop 2.8.5(小编安装的Hadoop环境)系统版本Centos7本次搭建的Spark版本为3.0.1。一、Spark Local环境搭建下载访问官网:http://spark.apache.org/ 点击Download下载最新版本。 下载spark其实是跟hadoop包对应的,但是我看官...

【转载】Spark部署模式介绍
【转载】06.Spark部署模式介绍前言目前Apache Spark支持三种分布式部署方式,分别是standalone、spark on mesos和 spark on YARN,其中,第一种类似于MapReduce 1.0所采用的模式,内部实现了容错性和资源管理,后两种则是未来发展的趋势,部分容错性和资源管理交由统一的资源管理系统完成:让Spark运行在一个通用的资源管理系统之上,这样可以...
Spark入门程序WordCount
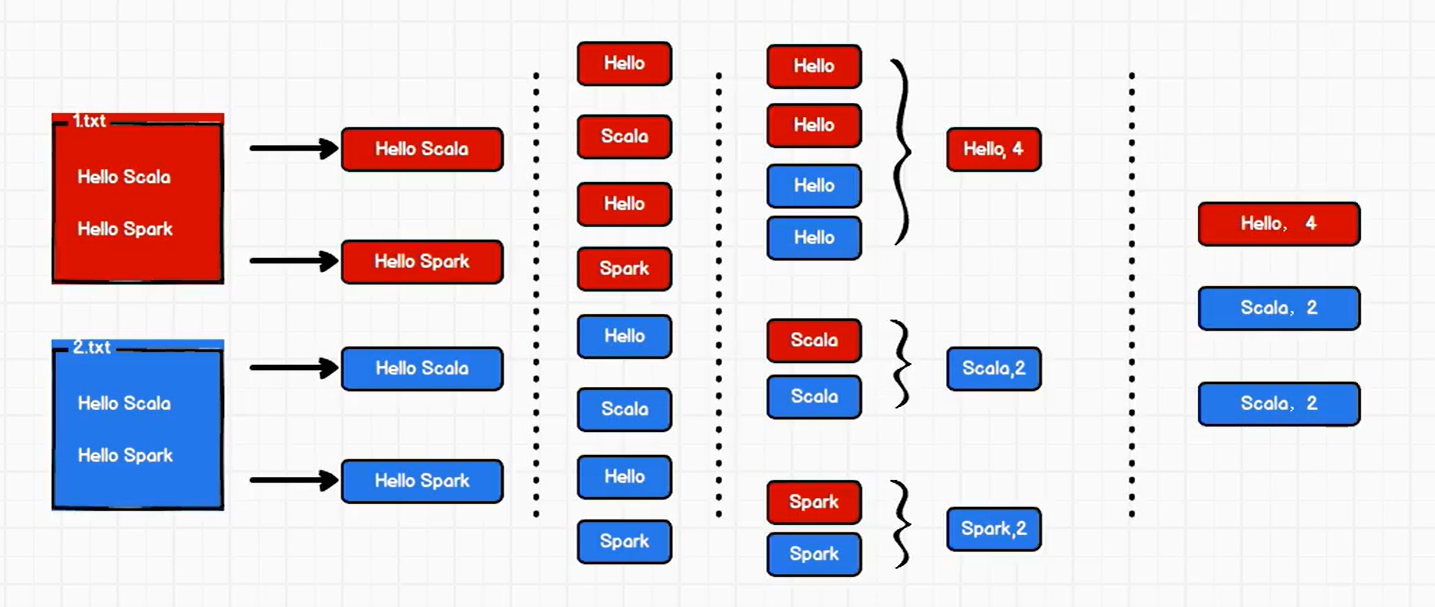
05.Spark入门程序WordCount一、问题描述描述:编写一个Spark应用程序,对1.txt和2.txt文件中的单词进行词频统计通过Spark core进行实现二、方法一1. 思路整行读取1.txt和2.txt文件中所有内容将整行数据拆分,形成一个个单词根据单词进行分组,将相同的单词放在一组当中,方便统计对分组后的数据进行转换将转换结果输出2. 代码实现流程建立和Spark框架的连接...
基于IDEA构建spark开发环境
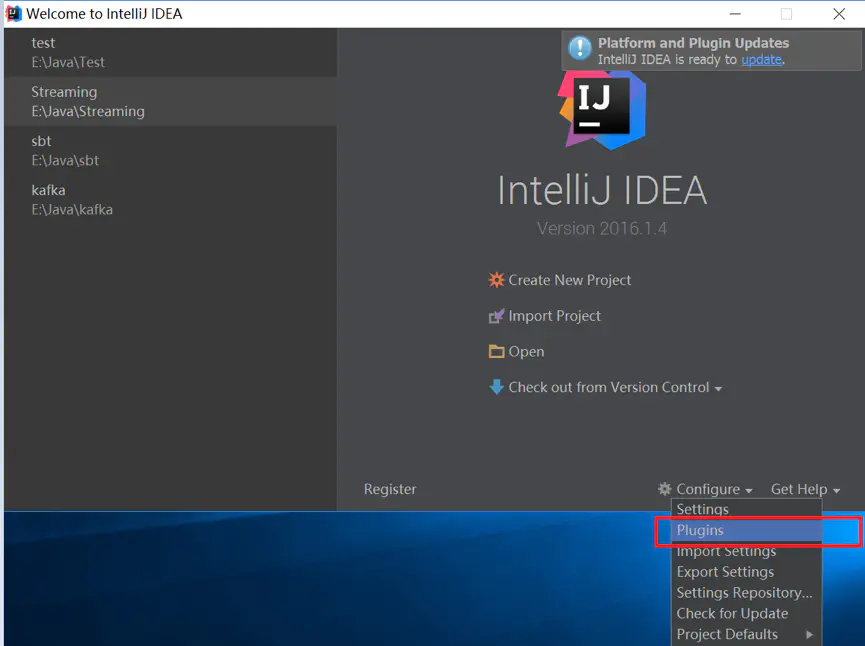
04.基于IDEA构建spark开发环境前言开发环境:1.IDEA版本2018.3.42.JDK版本1.83.Scala版本2.12.11一、IDEA安装Scala插件(1)点击右下角configuration,选择plugins(2)选择Browse repositories(3)输入Scala后搜索,然后安装,安装需要一些时间如果通过install自动下载插件失败,可以选择手动下载sca...

windows10 scala安装
03.windows10 scala安装前言已经安装成功JDK1.8,本次安装的scala版本为2.12.11一、下载下载地址:https://www.scala-lang.org/download/all.html2.下载windows安装版的scala二、scala安装1. 接受协议,下一步2. 选择安装的路径3.进行安装即可三、环境变量配置1、此电脑-->右击选择属性进行环境变量...
Spark和Hadoop比较
02.Spark和Hadoop比较一、历史比较Hadoop2006 年 1 月,Doug Cutting 加入 Yahoo,领导 Hadoop 的开发2008 年 1 月,Hadoop 成为 Apache 顶级项目2011 年 1.0 正式发布2012 年 3 月稳定版发布2013 年 10 月发布 2.X (Yarn)版本Spark2009 年,Spark 诞生于伯克利大学的 AMPLab...
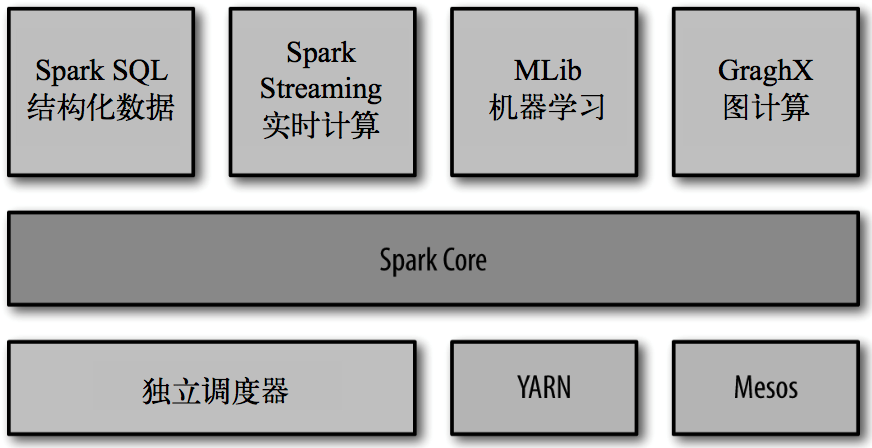
Spark入门介绍
01.Spark入门介绍一、简介Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。同Hadoop的MapReduce计算框架类似,但是相对于MapReduce,Spark凭借其可伸缩、基于内存计算等特点,以及可以直接读写Hadoop上任何格式数据的优势,进行批处理时更加高效,并有更低的延迟。二、历史2009 年,Spark 诞生于伯克利大学的 AMPLab 实验室2010 年...

Linux高级指令
03.Linux高级指令1、hostname指令作用:操作服务器的主机名(读取、设置)语法1:#hostname 含义:表示输出完整的主机名语法2:#hostname -f 含义:表示输出当前主机名中的FQDN(全限定域名)[root@hadoopserver file]# hostname hadoopserver [root@hadoo...
Linux进阶指令
02.Linux进阶指令1、df指令作用:查看磁盘的空间语法:#df -h -h表示以可读性较高的形式展示大小[root@hadoopserver /]# df -h 文件系统 容量 已用 可用 已用% 挂载点 /dev/mapper/centos-root 18G 2.7G 15G 16% / devtmpfs ...
