
【转载】04.Azkaban Flow 2.0的使用
[TOC]一、Flow 2.0简介1.1 Flow 2.0的产生Azkaban 目前同时支持 Flow 1.0 和 Flow2.0 ,但是官方文档上更推荐使用 Flow 2.0,因为 Flow 1.0 会在将来的版本被移除。Flow 2.0 的主要设计思想是提供 1.0 所没有的流级定义。用户可以将属于给定流的所有 job / properties 文件合并到单个流定义文件中,其内容采用 YAML 语法进行定义,同时还支持在流中再定义流,称为为嵌入流或子流。1.2 基本结构项目 zip 将包含多个流 YAML 文件,一个项目 YAML 文件以及可选库和源代码。Flow YAML 文件的基...

03.Azkaban使用案例
[TOC]前言Azkaban 2.0支持properties配置文件,也支持YML配置文件Azkaban 3.0默认支持YML配置文件Hello World案例实操(1)在windows环境新建first.project文件,增加如下内容azkaban-flow-version: 2.0注意:该文件作用,是采用新的Flow-API方式解析flow文件。文件必须以.project结尾。(2)新建first.flow文件,增加如下内容nodes: - name: jobA type: command config: command: echo "He...
02.Azkaban单机版安装教程
前言环境准备MySQL数据库JDK1.8本次安装Azkaban版本Azkaban-3.84.4一、安装步骤1、上传文件(1)将安装包上传到服务器上(2)创建目录,解压安装包到对应目录[hadoop@hadoopserver local]$ mkdir azkaban [hadoop@hadoopserver azkaban]$ tar -zxf azkaban-db-3.84.4.tar.gz -C /usr/local/azkaban/ [hadoop@hadoopserver azkaban]$ tar -zxf azkaban-exec-server-3.84.4.tar.gz -...
01.Azkaban概述
前言为什么需要工作流调度器一个完整的数据分析系统通常都是由大量任务单元组成: shell 脚本程序,java 程序,mapreduce 程序、hive 脚本等;各任务单元之间存在时间先后及前后依赖关系;为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行。常见任务调度工具crontab (Linux 自带命令,使用方式简单,适合不是非常复杂的场景,比如只按照时间来调度)oozie( Hadoop 自带的开源调度系统,使用方式比较复杂,适合大型项目场景)azkaban(一个开源调度系统,使用方式比较简单,适合中小型项目场景)企业定制开发(企业自研的调度系统,不开源)一、Az...

【转载】ZooKeeper详细介绍
[TOC]前言本文将以如下内容为主线讲解ZooKeeper中的学习重点,包括 ZooKeeper 中的角色、ZAB协议、数据模型、选举机制、监听器原理以及应用场景等。也会穿插一些相关面试或开发中常见内容进行重点讲解。接下来将带领大家入门学习 ZooKeeper 系列的内容,力求通俗易懂,图文并茂。一、ZooKeeper 的工作机制1.什么是ZooKeeperZooKeeper 是一个分布式协调服务,其设计的初衷是为分布式软件提供一致性服务。其本质上,就是文件系统+通知机制。ZooKeeper 提供了一个类似 Linux 文件系统的树形结构,ZooKeeper 的每个节点既可以是目录也可以...
Flume拓扑结构
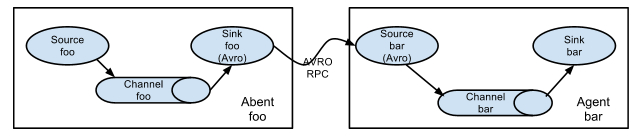
一、简单串联Flume Agent 连接 这种模式是将多个flume顺序连接起来了,从最初的source开始到最终sink传送的目的存储系统。此模式不建议桥接过多的 flume 数量, flume数量过多不仅会影响传输速率,而且一旦传输过程中某个节点 flume 宕机,会影响整个传输系统。二、复制和多路复用单 source,多 channel、sink Flume 支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个 channel 中,或者将不同数据分发到不同的 channel 中,sink 可以选择传送到不同的目的地。三、负载均衡和故障转...
Flume进阶
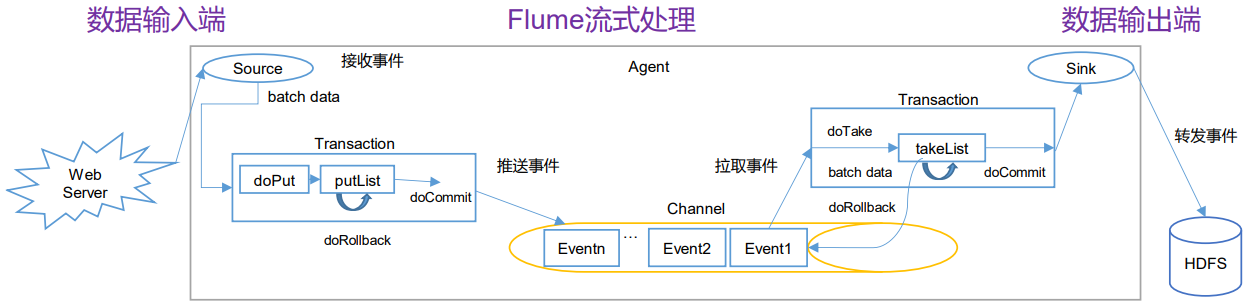
一、Flume事务在Flume中一共有两个事务:Put事务:在Source到Channel之间Take事务:Channel到Sink之间从Source到Channel过程中,数据在Flume中会被封装成Event对象,也就是一批Event,把这批Event放到一个事务中,把这个事务也就是这批event一次性的放入Channel中。同理,Take事务的时候,也是把这一批event组成的事务统一拿出来到sink放到HDFS上。Put事务流程doPut:将批数据先写入临时缓冲区 putListdoCommit:检查 channel 内存队列是否足够合并doRollback:channel 内存...
Flume概述
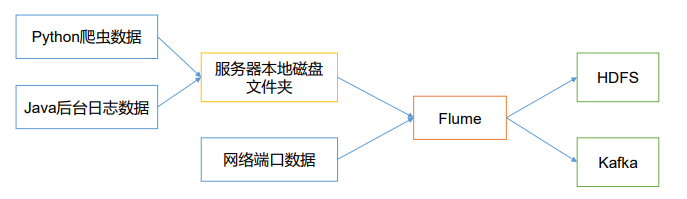
[TOC]一、定义Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。Flume作用从固定目录下采集日志信息到目的地(HDFS,HBase,Kafka);实时采集日志信息(taidir)到目的地;支持级联(多个Flume对接起来),合并数据;支持按照用户定制采集数据。说明Flume 使用 java 编写,其需要运行在 java1.6 或更高版本之上。官方网站:http://flume.apache.org/二、演进过程Fl...
DataX介绍
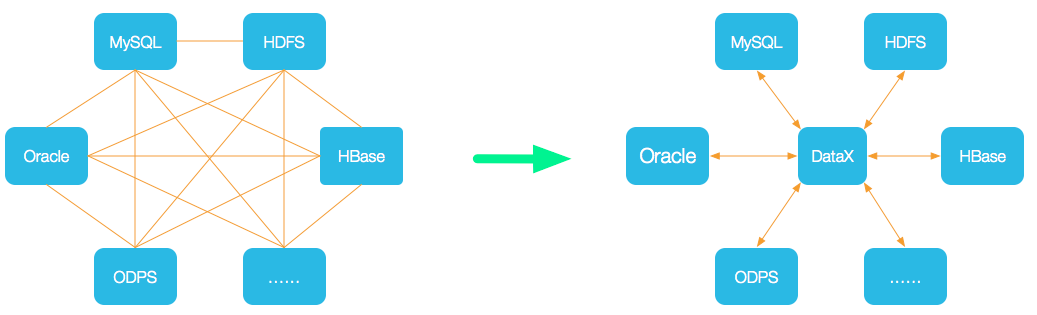
[TOC]一、概述DataX是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS各种异构数据源之间稳定高效的数据同步功能。设计理念 为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要...
12.Table API和Flink SQL之函数
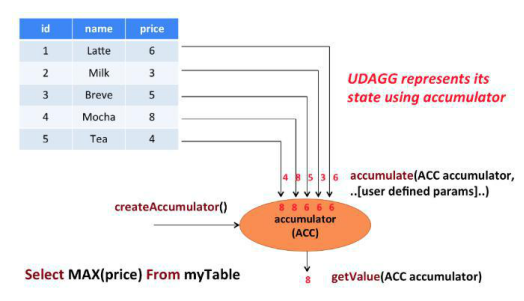
[TOC]前言 Flink Table 和 SQL 内置了很多 SQL 中支持的函数;如果有无法满足的需要,则可以实现用户自定义的函数(UDF)来解决。一、系统内置函数 Flink Table API 和 SQL 为用户提供了一组用于数据转换的内置函数。SQL 中支持的很多函数,Table API 和 SQL 都已经做了实现,其它还在快速开发扩展中。以下是一些典型函数的举例,全部的内置函数,可以参考官网介绍。类型TableApiSQLAPI比较函数ANY1 === ANY2value1 = value2比较函数NY1 > ANY2value1 >...